本文主要包括:
- Flink简介
- Flink如何提交任务到Yarn
- Flink任务案例
Flink简介
Flink是什么?
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Flink是一个流计算驱动的引擎,核心是Streaming。但是,它可以基于Streaming的内核,实现流批一体更全能的架构
- 无边界数据流
有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性纯实时数据,不存在等数据累计一定程度再处理的情况,数据生产后,立刻消费
- 有边界数据流
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理批处理数据,需要数累积一定量以后再行处理
- 有状态的计算
Flink有如下优点:
- 真正的流处理
- 多种窗口
- 自带状态(state)
- 精确一次传输语义
- 时间管理
流式计算框架对比
- 模型:Storm和Flink是真正的一条一条处理数据;Spark Streaming其实是小批处理,一次处理一批数据(小批量)
- API:Storm使用基础API进行开发,比如实现一个简单的sum求和操作;而Spark Streaming和Flink中都提供封装后的高阶函数,可以直接拿来使用
- 保证次数:在数据处理方面,Storm可以实现至少处理一次,但不能保证仅处理一次,这样就会导致数据重复处理问题,所以针对计数类的需求,可能会产生一些误差;Spark Streaming和Flink通过事务可以保证对数据实现仅一次的处理
- 容错机制:Storm通过ACK机制实现数据的容错机制,而SparkStreaming和Flink可以通过CheckPoint机制实现容错机制
- 状态管理:Storm中没有实现状态管理,Spark Streaming实现了基于DStream的状态管理,Flink实现了基于操作的状态管理
- 延时:表示数据处理的延时情况,因此Storm和Flink接收到一条数据就处理一条数据,其数据处理的延时性是很低的;而Spark Streaming是小型批处理,数据处理的延时性相对会偏高
- 吞吐量:Storm的吞吐量其实也不低,只是相对于其他几个框架而言较低;而Spark Streaming和Flink的吞吐量是比较高的
Strom是第一代实时处理框架,基于流处理,数据吞吐量和延迟上效果不理想,只支持at least once和at most once,不能保证精确一次性,在数据准确性上存在不足
Spark Streaming作为第二代实时处理框架,基于mini-batch思想,每次处理一小批数据,一小批数据包含多个事件,以接近事实处理效果,概况性来说是微批次、准实时
Spark Streaming说到底,还是微批处理,并不是真正的实时处理,所以它的吞吐量很好,但是实时性没有Flink好,而且Spark官方也说了,最好不要把batch设置的太小
第三代实时处理框架,支持有界和无界数据流上做有状态计算,以时间为单位,支持exactly once,数据的准确性得到提高,相比Strom,吞吐量更高,延迟更低,相比SparkStreaming,Flink是真正意义上的实时计算,所需计算资源更少
工作中如何选择实时计算框架
- 需要关注流数据是否需要进行状态管理,如果是,那么只能SparkStreaming和Flink中选择一个。
- 需要考虑项目对At-least-once(至少一次)或者Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择Storm。
- 对于小型独立的项目,并且需要低延迟的场景,建议使用Storm,这样比较简单。
- 如果你的项目已经使用了Spark,并且秒级别的实时处理可以满足需求的话,建议使用Spark Streaming
- 要求消息投递语义为Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用Flink。
Flink下载安装
到官网上下载Flink安装包,并解压
这里只是要把Flink当成一个客户端,提交任务到Yarn上,所以不必配置Flink集群,只需要配置一下HADOOP_CLASSPATH
export HADOOP_CLASSPATH=`hadoop classpath`最后,配置Flink的环境变量
Flink如何提交任务到Yarn
在官网点击Documentation -> Latest stable release -> Deploy Flink -> Clusters and Deployments -> YARN
Flink提交任务到Yarn有3种方式:
Application Mode
Application Mode将在YARN上启动一个Flink集群,其中Application jar的main()方法将在YARN中的JobManager上执行。
应用程序完成后,Flink集群将立即关闭。可以使用yarn application -kill <ApplicationId>或取消Flink作业来手动停止集群flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar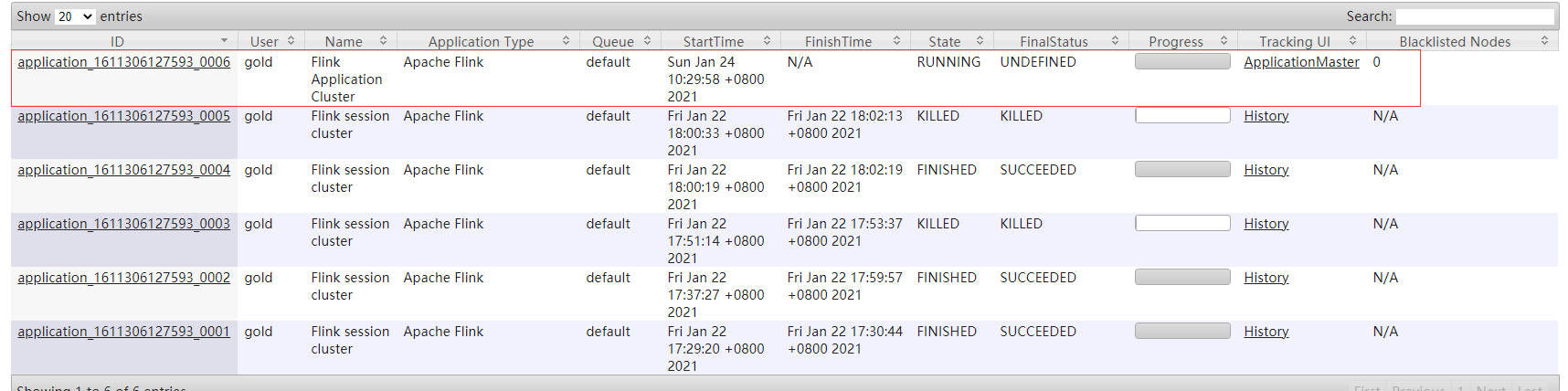
这种就是直接把Flink任务注册到Yarn上,就跟Spark、Hive任务提交Yarn任务一样。
通过这种方式提交到Yarn上,可以与它交互以执行诸如取消、获取保存点之类的操作
# 列举集群上的app flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY # 取消正在执行的job flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>需要注意的是,任务取消后,Flink集群也会停止
为了挖掘Application Mode的潜力,可以考虑使用yarn.provided.lib.dirs配置选项,将应用程序jar上传到集群中所有节点都可以访问的位置,例如HDFS上flink run-application -t yarn-application \ -Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \ hdfs://myhdfs/jars/my-application.jar由于所需的Flink jar和应用程序jar将由指定的远程位置接收,而不是由客户机发送到集群,因此上面的内容将允许作业提交变得格外轻量级。
任务启动的时候,客户端不需要再把jar上传到每个jobManager了,跑完了也不会再删除。
Per-Job Cluster Mode
Per-Job Cluster Mode将在Yarn上启动Flink集群,然后在本地运行提供的应用程序jar,最后将JobGraph提交给YARN上的JobManager
如果传递–detached参数,客户端将在集群接受提交后停止。
提交的任务一旦停止,Flink集群也将停止flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar同样,通过这种方式提交的任务,也可以与它交互以执行诸如取消、获取保存点之类的操作
# 列举集群上的app flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY # 取消正在执行的job flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Session Mode
# 如果成功,在yarn上是可以看到application_id的 yarn-session.sh --detached # 成功后会打印: #JobManager Web Interface: http://golden-02:39461 #2021-01-22 17:29:31,594 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli # [] - The Flink YARN session cluster has been started in detached mode. # In order to stop Flink gracefully, use the following command: #$ echo "stop" | yarn-session.sh -id application_1611306127593_0001 #If this should not be possible, then you can also kill Flink via YARN's web interface or via: #$ yarn application -kill application_1611306127593_0001 #Note that killing Flink might not clean up all job artifacts and temporary files. # 执行一个测试job flink run ./examples/streaming/TopSpeedWindowing.jar # 杀掉Flink的任务可以使用cancel flink cancel ${flink_app_id}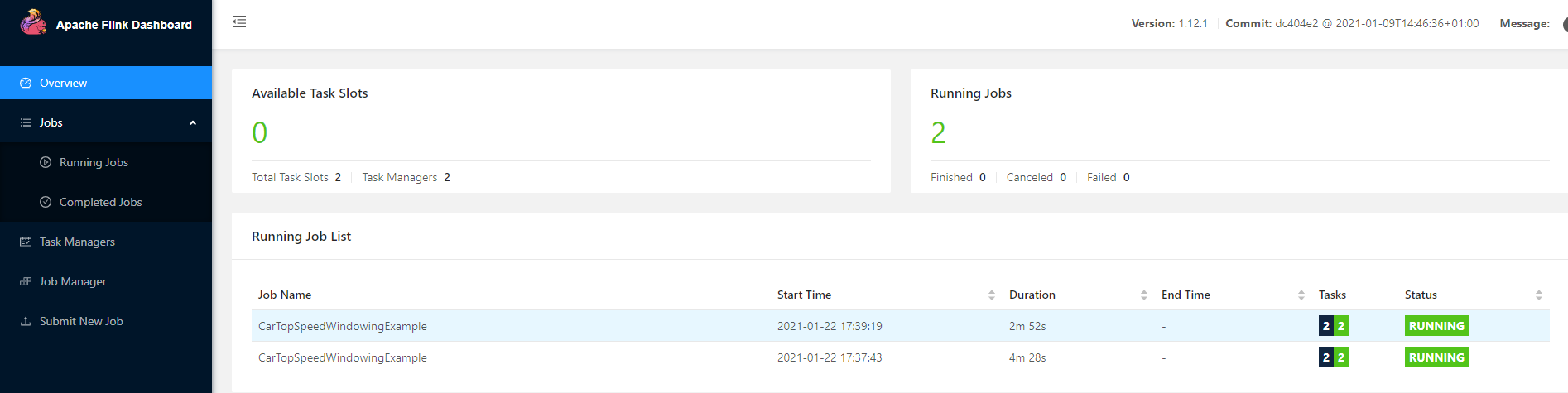
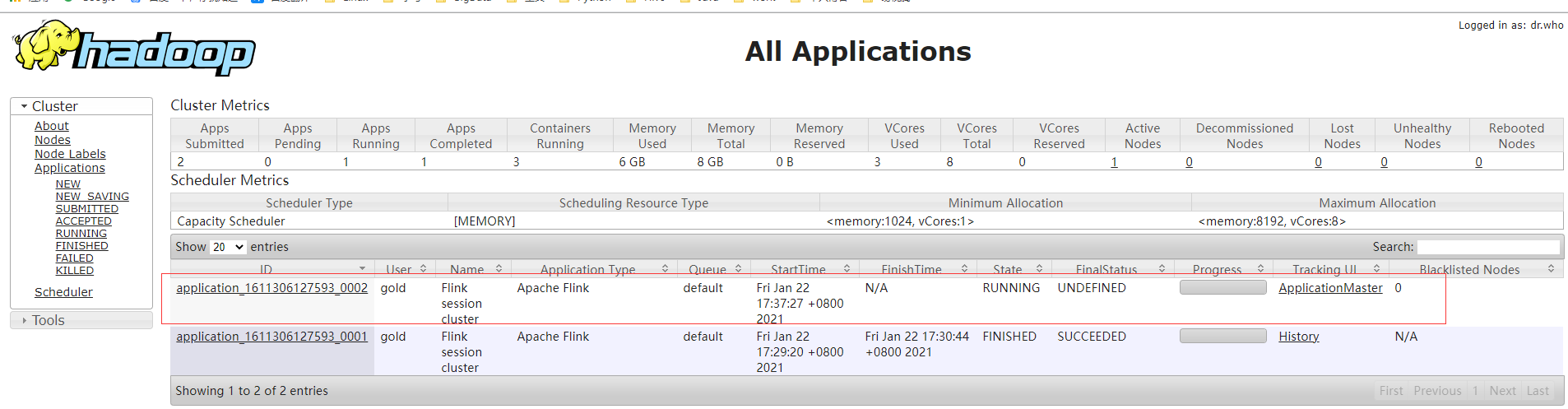
可以看到,yarn的任务监控页面只能找到一个application_id,但是Flink的任务列表有2个Session Mode有两种操作模式:attached mode (default):
yarn-session.sh将任务提交到Yarn上以后,不会关闭,会继续与集群通信,跟踪集群任务的状态,如果任务失败,会在客户端显示错误,如果客户端被停止,它也会向集群发送关闭任务的信号detached mode (-d or –detached):
yarn-session.sh将任务提交到Yarn上以后,会直接返回,要是想停止集群中的任务,就需要调用另外一个客户端,或者使用Yarn的工具(yarn application -kill)Session Mode将在/tmp/.yarn-properties-<username>中创建一个隐藏的yarn properties文件,提交作业时,命令行界面将提取该文件进行集群发现
如果提交过yarn-session任务,想要切换到其他方式提交任务,sql-client提交任务到standalone集群,需要把tmp下的/tmp/.yarn-properties-<username>文件删除
提交Flink作业时,也可以在命令行界面中手动指定目标session。举个例子:flink run -t yarn-session -Dyarn.application.id=application_XXXX_YY ./examples/streaming/TopSpeedWindowing.jar这里测试了一下,只能是注册session的application_id
可以使用
yarn-session.sh -id application_XXXX_YY重新连接session
除了通过配置conf/flink-conf.yaml,还可以在提交session时将使用-Dkey=value参数配置传递给yarn-session.sh客户端。Flink提交任务到yarn上,需要提前启动一个application,然后后面的flink任务会共享这个application的资源?
yarn-session 模式的taskmanager可以根据任务自动弹性扩缩容,比如先用-d注册一个分离的session集群,这时候yarn上的taskmanager数为0,这时候提交任务到这个session上,此时yarnsession会自动注册一个taskmanegr,如果这个任务失败或者取消,这个taskmangaer会自动释放
yarn-session模式下-ytm 1024m,是指每个taskmanager的内存,不是整个集群总共的内存。并且,yarn-seesion的每个taskmanager内存都是相同的,无法为某个指定的taskmanager指定独有的内存设置
yarn-session的缺点是,tm的内存用量都是一样的,并且,只要有一个任务导致jobmanager宕机,那所有的taskmanager就都会失败
为什么flink官网要废弃yarn-per-job模式
放弃的原因:
- 根据工作模式和申请模式,我们有两个对大多数用户来说可能会做同样的事情的模式。具体来说,对于那些不关心main()方法在哪里执行并且希望 每个集群提交一个作业。有两种方法可以做同样的事情令人困惑
- “按作业模式”仅由YARN支持。如果我们保留它,我们应该努力在Kubernetes和Standalone中提供支持,以减少特殊情况套管。 删除每个作业模式将降低代码的复杂性,并允许我们将更多资源用于其他两种部署模式。
会话模式: olap风格,交互式作业/查询,短期批处理作业、非常小的作业、传统的以集群为中心的部署模式(适合“Hadoop世界”)
应用模式: 长时间流式作业,大规模&异构作业(资源隔离!),以应用程序为中心的部署模式(适合“Kubernetes世界”)
也就是说,flink官方认为,yarn-application模式与perjob模式功能是差不多的,perjob是多余的
但是,application模式,好像没办法使用-sae吧,这个需要确认一下
Flink任务案例
公司是Flink是以java为开发语言的,这里学习也使用java
配置Flink的Maven开发环境
到Flink的官网,点击Getting Started -> Application Development -> DataStream API -> Project Configuration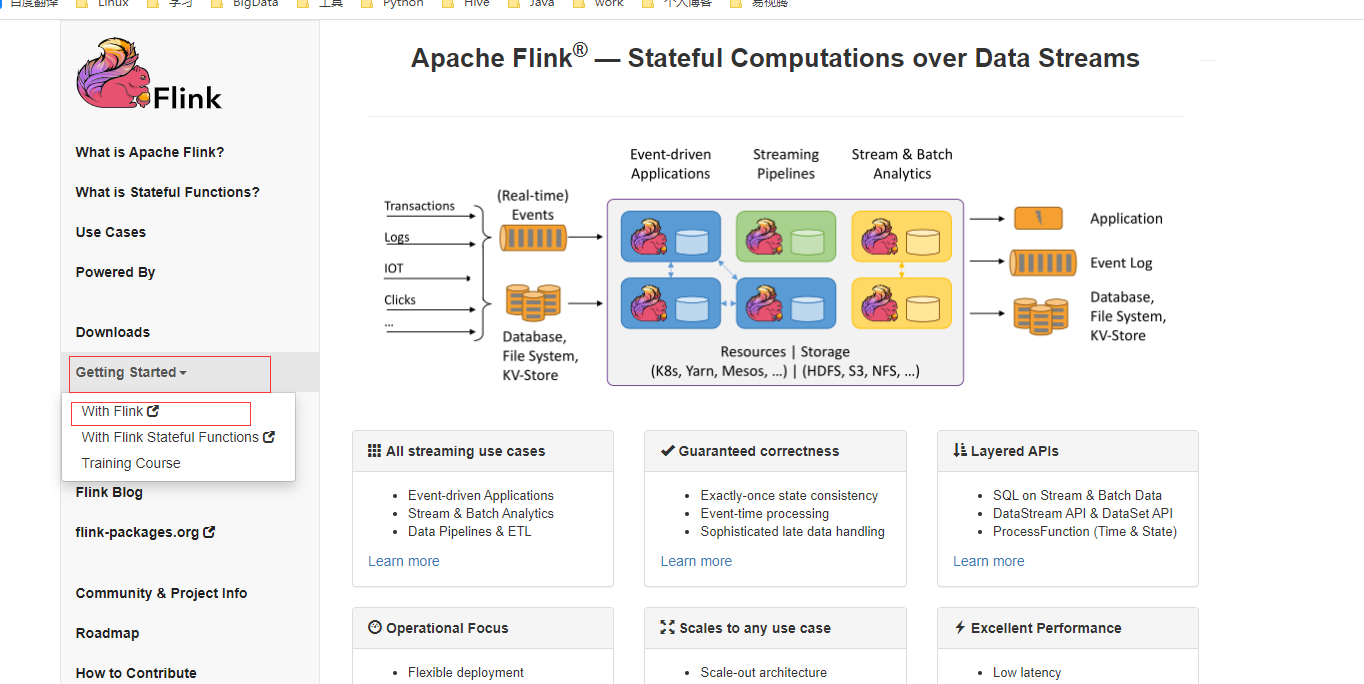
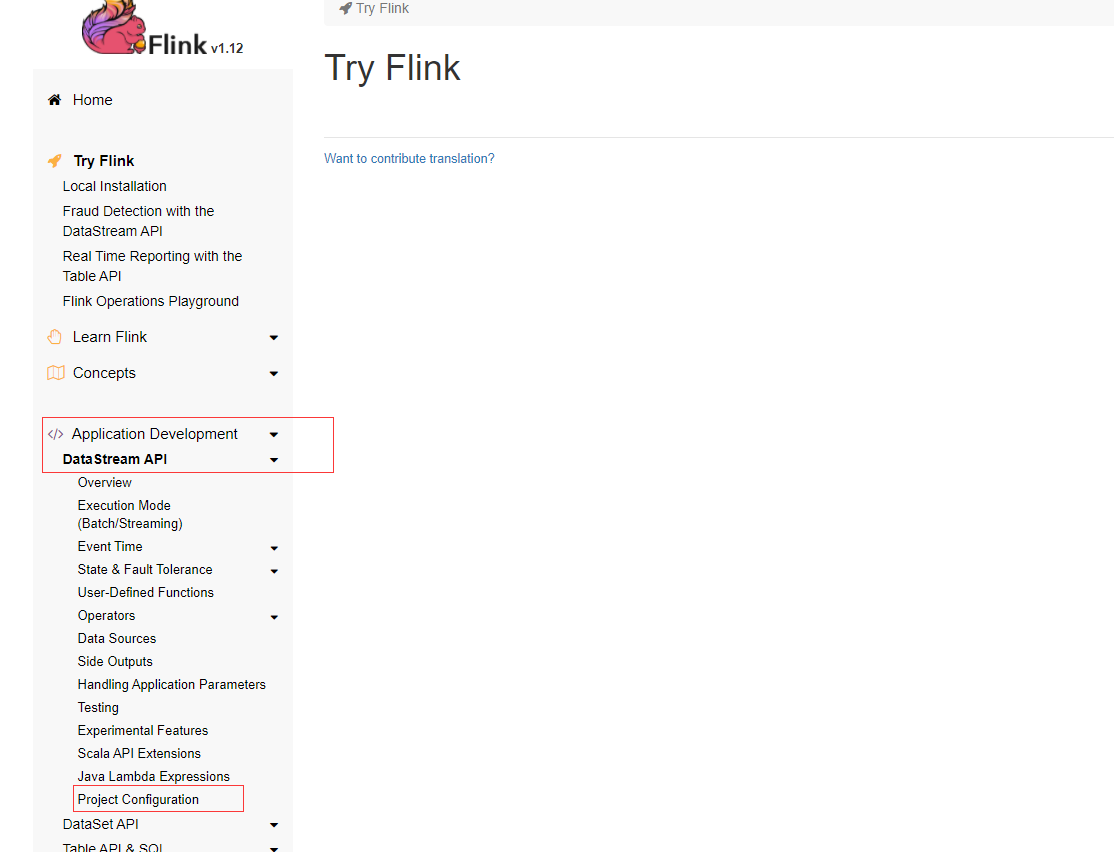
也可以在Flink的下载页面寻找maven的配置项
得到maven配置:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.12.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.12.0</version>
</dependency>
</dependencies>实现简单功能:Flink消费Kafka数据后再写入Kafka
下面直接上代码:
package com.hzw.bigdata.flinkstudy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class FlinkConsumerKafka2Kafka {
public static void main(String[] args) throws Exception {
// 创建Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Kafka参数
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "golden-02:9092");
properties.setProperty("group.id", "fink-test");
properties.setProperty("auto.offset.reset","earliest");
String inputTopic = "first";
// Source
DataStreamSource<String> kafkaData = env.addSource(new FlinkKafkaConsumer<>(
inputTopic,
new SimpleStringSchema(),
properties)).setParallelism(1);
kafkaData.print();
// Sink
Properties prop = new Properties();
prop.setProperty("bootstrap.servers", "golden-02:9092");
prop.setProperty("zookeeper.connect", "golden-02:2181");
prop.setProperty("group.id", "flink-write");
kafkaData.addSink(new FlinkKafkaProducer<>(
"golden-02:9092",
"flink-write",
new SimpleStringSchema()
)).name("flink-connectors-kafka")
.setParallelism(1);
// execute
env.execute("kafka consumer to kafka ");
}
}IDEA本地调试Flink程序报错
如果直接在IDEA上执行,会报如下错误: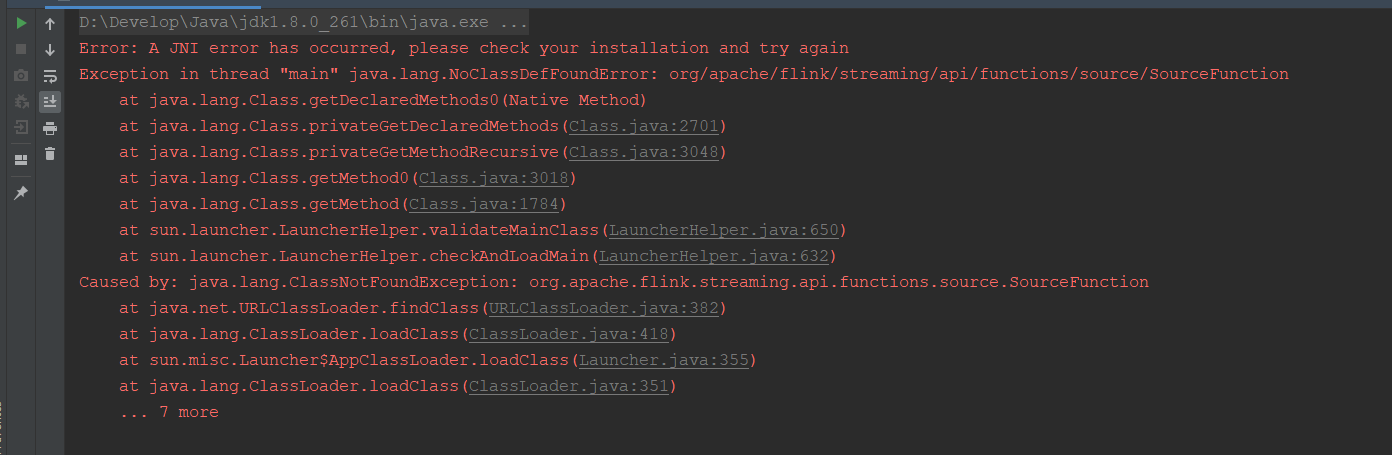
本质上,这是因为没有配置java的jre环境,可以使用两种办法解决:
导入
Flinklib文件夹下的jar包
导入流程:
依次点击File->Project Structure->Module->Dependencies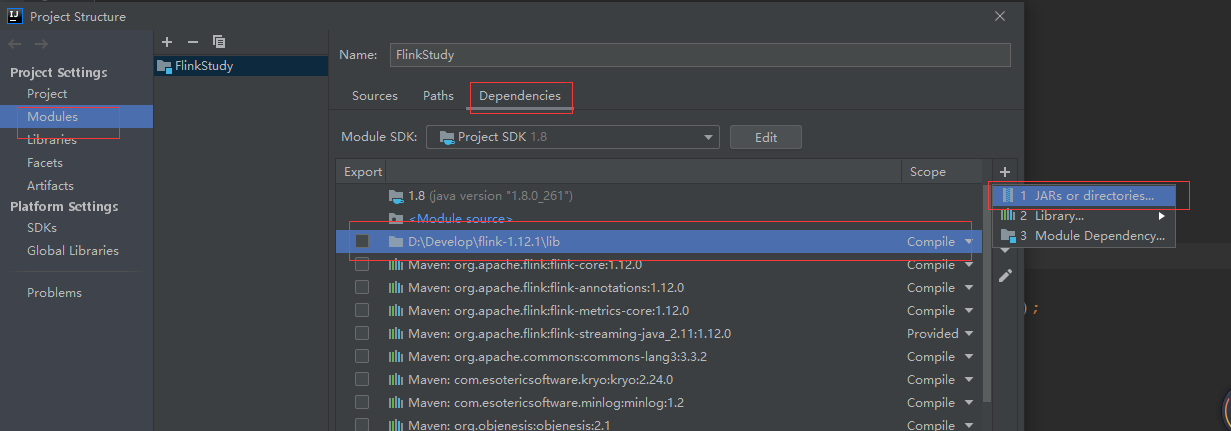
配置完成后,右键run,控制台就能看到程序的运行结果了
通过配置java的jre环境解决:
配置方法: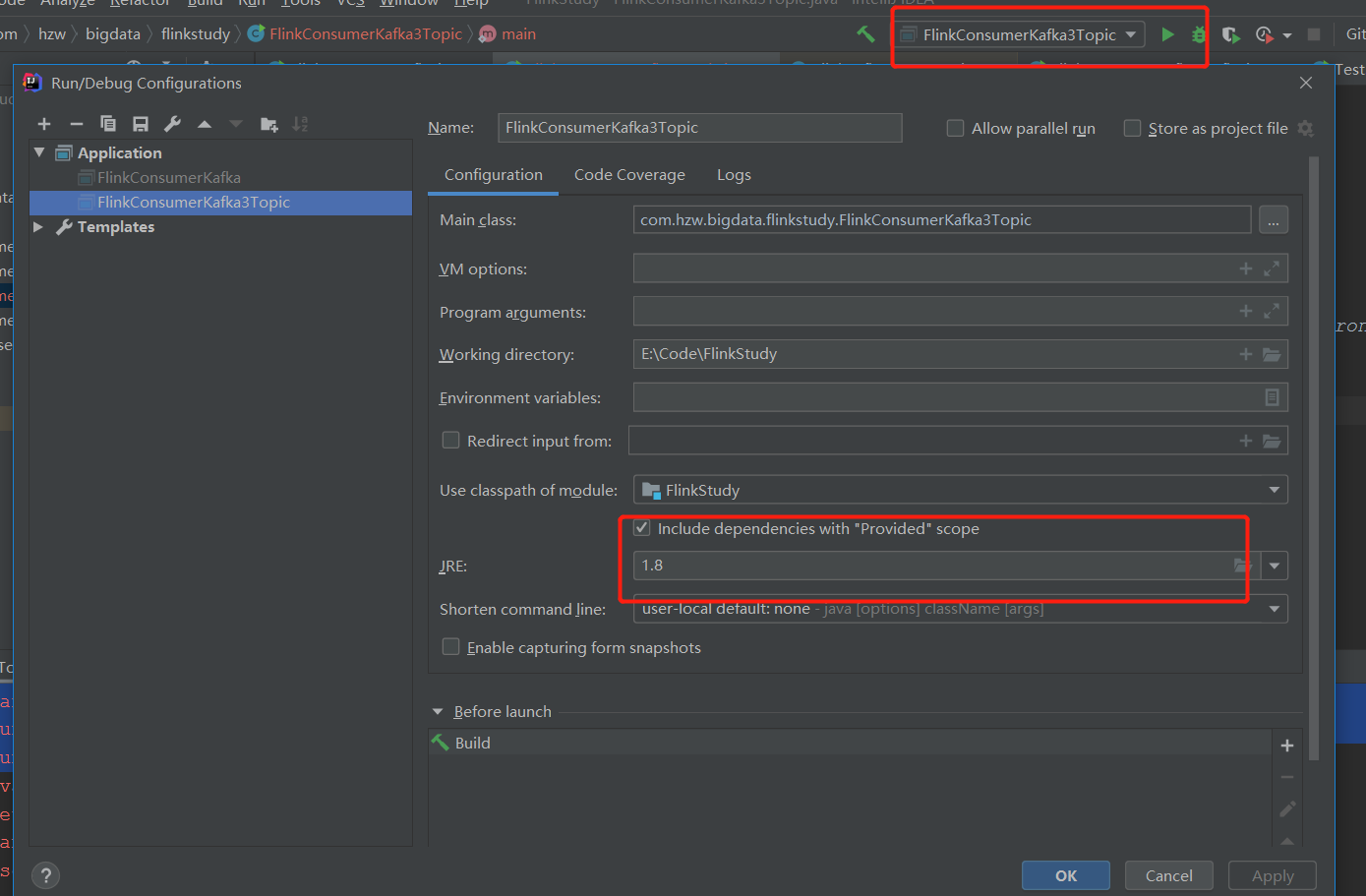
或者,配置JRE的环境变量
通过命令行提交任务到yarn上执行:
flink run -t yarn-per-job --class com.hzw.bigdata.flinkstudy.FlinkConsumerKafka2Kafka FlinkStudy-1.0-SNAPSHOT-jar-with-dependencies.jar给firsttopic生产点数据:
消费flink写入的另一个topic数据
虽然利用Per-Job Cluster Mode方式提交到Yarn上执行成功了,但是使用Application Mode方式是报错的
报错信息如下:
Caused by: org.apache.flink.streaming.runtime.tasks.StreamTaskException: Cannot instantiate user function.
at org.apache.flink.streaming.api.graph.StreamConfig.getStreamOperatorFactory(StreamConfig.java:339) ~[flink-dist_2.12-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.OperatorChain.<init>(OperatorChain.java:143) ~[flink-dist_2.12-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:509) ~[flink-dist_2.12-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:565) ~[flink-dist_2.12-1.12.1.jar:1.12.1]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:722) ~[FlinkStudy-1.0-SNAPSHOT-jar-with-dependencies.jar:?]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:547) ~[FlinkStudy-1.0-SNAPSHOT-jar-with-dependencies.jar:?]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_201]
Caused by: java.lang.ClassCastException: cannot assign instance of org.apache.commons.collections.map.LinkedMap to field org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.pendingOffsetsToCommit of type org.apache.commons.collections.map.LinkedMap in instance of org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2287) ~[?:1.8.0_201]
at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1417) ~[?:1.8.0_201]
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2293) ~[?:1.8.0_201]
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211) ~[?:1.8.0_201]
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) ~[?:1.8.0_201]- 报错原因:
LinkedMap cannot be cast to LinkedMap exceptionsLinkedMap class is being loaded from two different packages, and those are being assigned to each other. - 解决办法:
在conf/flink-conf.yaml 添加如下内容classloader.resolve-order: parent-first
实现简单功能:Flink消费Kafka数据并实现wordCount
这里遇到了问题
- 直接消费kafka数据,不使用window函数,可以正常wordCount
- 直接copy网上的代码,使用
timeWindow(Time.seconds(5)),kafka数据正常消费,但是没有正常计算并打印 window(EventTimeSessionWindows.withGap(Time.seconds(1L)))kafka数据正常消费,但是没有正常计算并打印
代码如下:package com.hzw.bigdata.flinkstudy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.util.Collector; import java.util.Properties; public class FlinkConsumerKafka { public static void main(String[] args) throws Exception { // 创建Flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // Kafka参数 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "golden-02:9092"); properties.setProperty("group.id", "fink-test"); String inputTopic = "first"; // Source FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(inputTopic, new SimpleStringSchema(), properties); DataStream<String> stream = env.addSource(consumer); DataStream<Object> wordCount = stream .flatMap((String line, Collector<Tuple2<String, Integer>> collector) -> { String[] tokens = line.split("\\s"); // 输出结果 (word, 1) for (String token : tokens) { if (token.length() > 0) { collector.collect(new Tuple2<>(token, 1)); } } }) .returns(Types.TUPLE(Types.STRING, Types.INT)) .keyBy(key -> key.f0) //.window(EventTimeSessionWindows.withGap(Time.seconds(1L))) //无数据 .window(TumblingProcessingTimeWindows.of(Time.seconds(1))) //有数据 //.timeWindow(Time.seconds(5)) //无数据 .sum(1) .map(key -> (key.f0 + ":" + key.f1)); wordCount.print(); env.execute("kafka streaming word count"); } }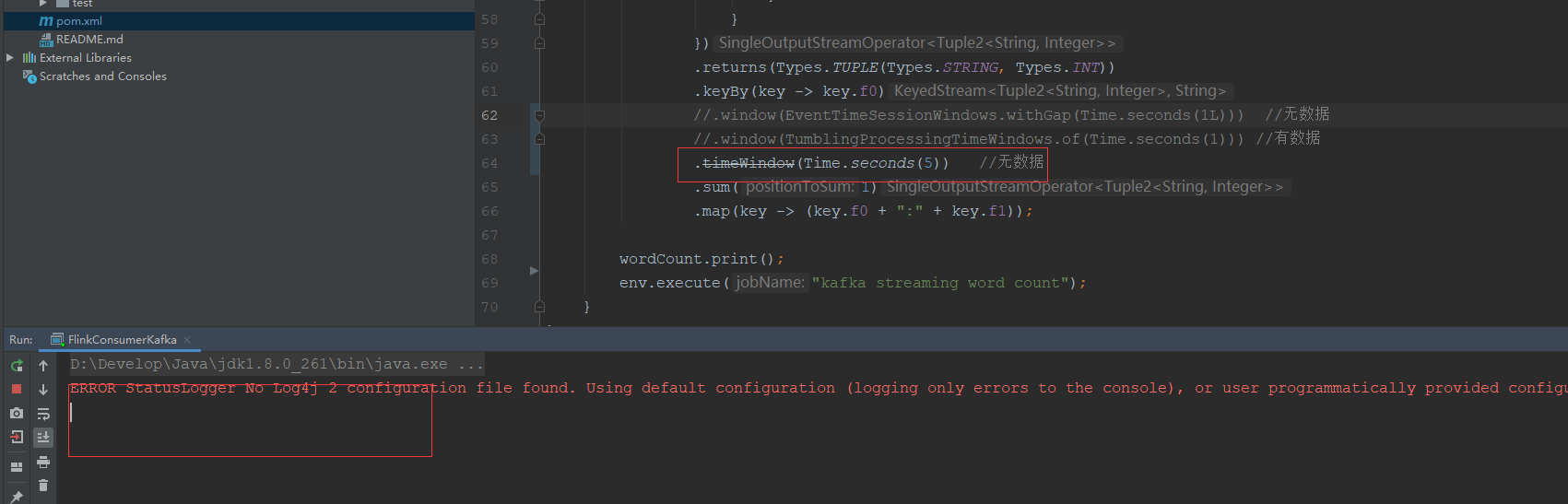
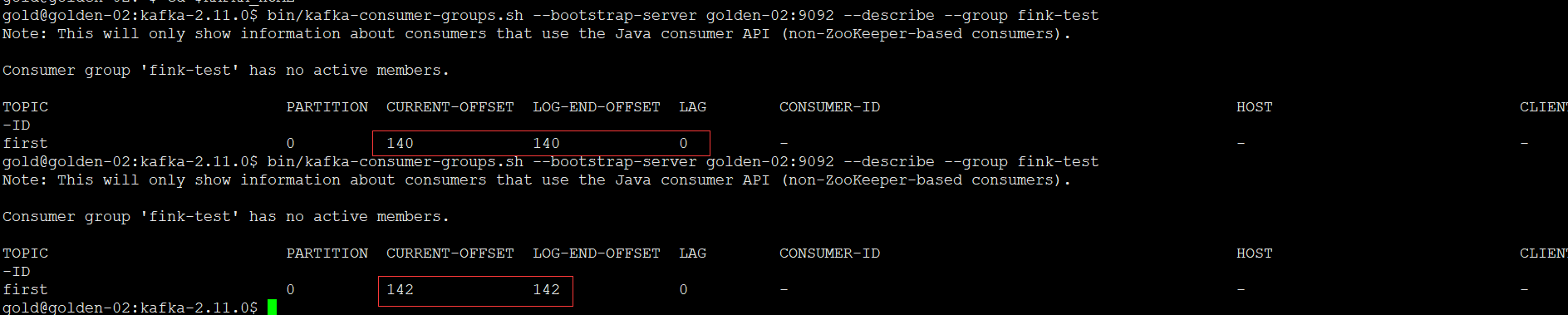
从checkpoint点重新消费kafka数据
发现通过公司封装的Flink,虽然在配置任务的时候,选择了从某个检查点恢复,但是消费的kafka的offset还是从最新的位置开始,这里自己调研一下:
Flink kafka consumer的消费模式设置
- setStartFromEarliest:从队头开始,最早的记录,内部的Consumer提交到Kafka/zk中的偏移量将被忽略。
- setStartFromLatest:从队尾开始,最新的记录,内部的Consumer提交到Kafka/zk中的偏移量将被忽略。
- setStartFromGroupOffsets():默认值,从当前消费组记录的偏移量开始,接着上次的偏移量消费,以Consumer提交到Kafka/zk中的偏移量最为起始位置开始消费,group.id设置在consumer的properties里;如果没找到记录的偏移量,则使用consumer的properties的auto.offset.reset设置的策略。
- setStartFromSpecificOffsets(Map<TopicPartition, Long>的参数):从指定的具体位置开始消费
- setStartFromTimestamp(long):从指定的时间戳开始消费,对于每个分区,时间戳大于或等于指定时间戳的记录将用作起始位置。如果一个分区的最新记录早于时间戳,那么只需要从最新记录中读取该分区。在此模式下,Kafka/zk中提交的偏移量将被忽略。
从队头、指定offset、指定时间戳位置开始消费,会把历史数据当成批数据处理,不会有一条处理一条。
验证代码:
package com.hzw.bigdata.flinkstudy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class FlinkConsumerKafka {
public static void main(String[] args) throws Exception {
// 创建Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "golden-02:9092");
properties.setProperty("group.id", "fink-test");
properties.setProperty("auto.offset.reset","earliest");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
String inputTopic = "first";
// Source
FlinkKafkaConsumer<String> consumer =
new FlinkKafkaConsumer<String>(inputTopic, new SimpleStringSchema(), properties);
//这里设置一开始总是失败,原因是token.length() < 6不满足,直接exit了
//但是这里有个问题,数据不应该是来一条消费一条吗?,最开始的几条数据,是满足token.length() < 6的
//看这样的情况是,flatmap执行完以后,才会触发后面的函数
consumer.setStartFromEarliest();
//consumer.setStartFromTimestamp(1612246518000l);
//consumer.setStartFromLatest();
DataStream<String> stream = env.addSource(consumer);
DataStream<Object> wordCount = stream
.flatMap((String line, Collector<Tuple2<String, Integer>> collector) -> {
String[] tokens = line.split("/s");
// 输出结果 (word, 1)
for (String token : tokens) {
//这里的现象是:一直没有输出结果,突然exit(1),直接走了else,也就是说,它会把历史数据消费完/消费一个批次,再执行后面的聚合
//但是,这里不知道是会把历史数据消费完才执行后面的聚合,还是只要消费到一定程度就会执行聚合
//如果一定要消费所有历史数据才聚合,那么可能以后对历史数据的消费需要慎重,因为一口气读取的历史数据如果太多,绝对会出问题
if (token.length() > 0 && token.length() < 6) {
collector.collect(new Tuple2<>(token, 1));
}else {
System.out.println(token);
System.exit(1);
}
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(key -> key.f0)
//.window(TumblingProcessingTimeWindows.of(Time.seconds(1))) //有数据
.sum(1)
.map(key -> (key.f0 + ":" + key.f1));
wordCount.print();
env.execute("kafka streaming word count");
}
}Flink Standalone集群模式部署
Flink Standalone模式部署集群是最简单的一种部署方式,不依赖于其他的组件,另外还支持YARN/Mesos/Docker等模式下的部署
老规矩,配置flink前必须做下面的基础准备:
- JDK环境,1.8.x或者更高,Oracle JDK或者OpenJDK都可以,二进制包解压的方式安装要配置好JAVA_HOME
- 主机名和hosts配置文件集群内完全对应,准确配置.
- 集群之间保证通信正常,关闭防火墙或者提前设置好规则.
- 集群所有节点配置ssh免密,否则后续启动集群的时候还需要输入密码.
- 集群配置时间同步服务,ntp或者chrony服务,这个应该是大数据组件集群的标配
然后准备安装flink,flink的安装目录为了便于维护所有的安装位置都要一致
编辑配置文件:conf/flink-conf.yaml
jobmanager.rpc.address: golden-01编辑master、worker文件
## master文件
golden-01:8081
## worker文件
golden-01
golden-02
golden-03三台节点都需要配置
然后启动bin/start-cluster.sh,启动以后发现,还是只在golden-01节点启动了taskmanager,找了很久才发现,golden-02和golden-03节点的bin下的启动脚本没有添加执行权限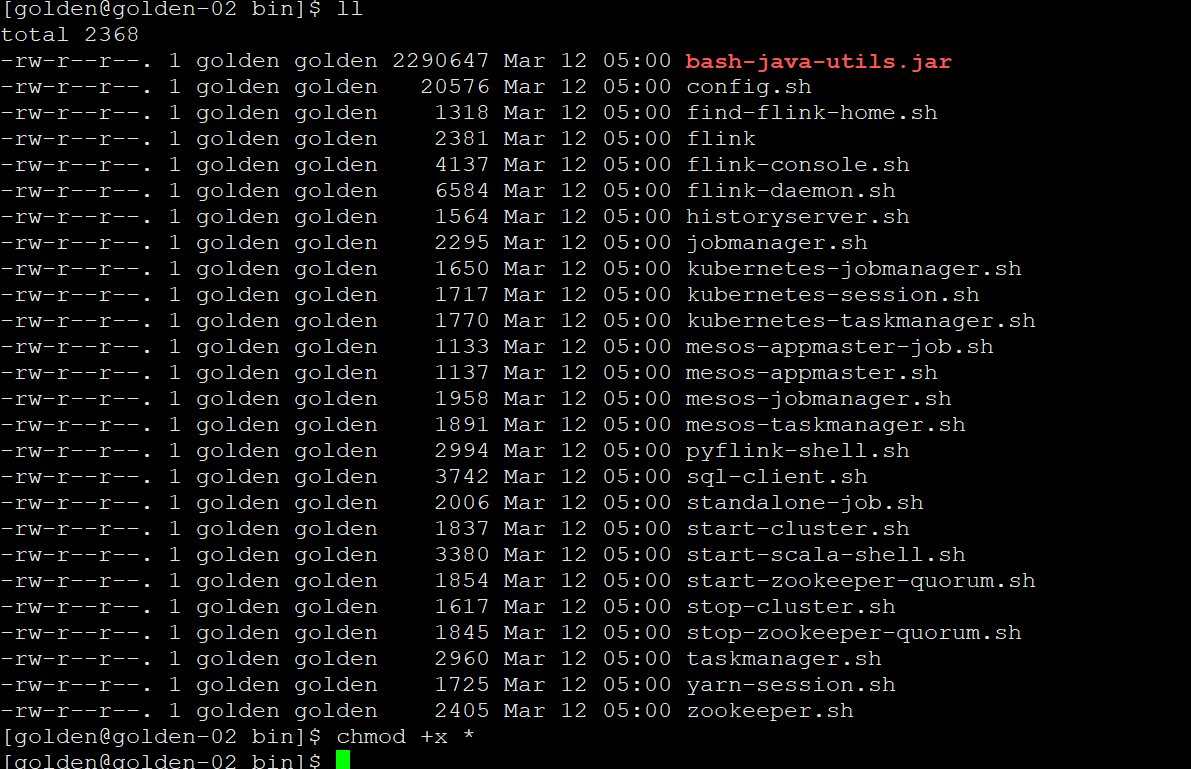
这里给bin下的脚本添加可执行权限,集群启动成功
[golden@golden-01 flink-1.13.6]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host golden-01.
Starting taskexecutor daemon on host golden-01.
Starting taskexecutor daemon on host golden-02.
Starting taskexecutor daemon on host golden-03.Flink sql-client交互式命令行
一开始以为,sql-client方式,只支持standalone模式,后来才知道,它也支持yarn-session模式
可以有2中方式启动:
standalone方式启动
## 首先启动standalone集群 cd /opt/modules/flink-1.13.6 && ./bin/start-cluster.sh ## 启动sql-client ./bin/sql-client.sh embeddedembedded模式是默认的,不加也可以,不过,建议加上规范点
yarn-session方式启动
如果想要把任务提交给yarn,则需要启动一个yarn-session任务,yarn-session模式其实就是在yarn上生成一个standalone集群./bin/yarn-session.sh -s 4 -nm cool -d然后flink-sql客户端连接这个集群提交SQL任务
./bin/sql-client.sh embedded -s yarn-session因为yarn-session模式默认会在/tmp/目录下维护一个会话信息,此时启动客户端指定yarn-session他会自动寻找到当前的session会话然后提交任务
但是,提交到yarn上只能使用yarn-session模式,无法使用per-job的方式,感觉不太实用,一般也就是测试的时候用一下,生产上肯定不会用它的
在IDEA上运行Flink任务
在IDEA上运行Flink任务,在网上查到,需要把flink-dist_xxx.jar放到代码工程的的modules里,这里提供一个更方便的方式:
在pom文件里,添加如下内容:
<flink.scope>compile</flink.scope>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>获取flink env换一种获取:
Configuration conf = new Configuration();
conf.setInteger(RestOptions.PORT, 8081);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);需要注意的是,通过打包的方式运行的时候,需要把scope改成provided
IDEA本地提交FLINK任务到远程的集群
这个和在IDEA上运行flink任务是不一样的,这个是提交任务到远程的集群
public class RemoteEnvironmentTest {
public static void main(String[] args) throws Exception {
ExecutionEnvironment remoteEnv = ExecutionEnvironment.createRemoteEnvironment("node", 6123, "C://flink-lib//flink/Users/admin/Downloads/online_training.jar");
DataSource<String> source = remoteEnv.readTextFile("hdfs://127.0.0.1:9000/test");
source.map(new