本文主要包括:
- Flink状态管理
- Flink Checkpoint机制
- Flink精准一次探究
Flink状态管理
看到一篇文章,讲述的Flink的状态管理特别详细,忍不住想记录一下,哈哈
具体可以参考:
Flink状态管理:Keyed State和Operator List State深度解析
为什么要管理状态
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
- 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
- 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
- 对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
- 在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
我们知道,Flink的一个算子有多个子任务,每个子任务分布在不同实例上,我们可以把状态理解为某个算子子任务在其当前实例上的一个变量,变量记录了数据流的历史信息。当新数据流入时,我们可以结合历史信息来进行计算。实际上,Flink的状态是由算子的子任务来创建和管理的。一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。
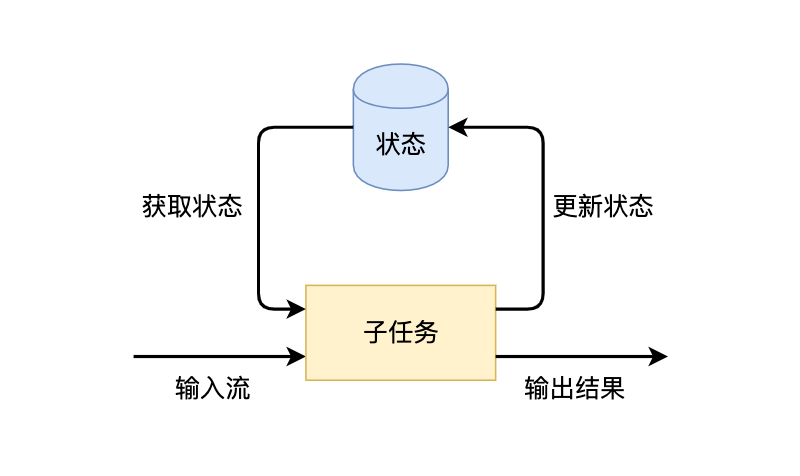
获取和更新状态的逻辑其实并不复杂,但流处理框架还需要解决以下几类问题:
- 数据的产出要保证实时性,延迟不能太高。
- 需要保证数据不丢不重,恰好计算一次,尤其是当状态数据非常大或者应用出现故障需要恢复时,要保证状态的计算不出任何错误。
- 一般流处理任务都是7*24小时运行的,程序的可靠性非常高。
基于上述要求,我们不能将状态直接交由内存管理,因为内存的容量是有限制的,当状态数据稍微大一些时,就会出现内存不够的问题。假如我们使用一个持久化的备份系统,不断将内存中的状态备份起来,当流处理作业出现故障时,需要考虑如何从备份中恢复。而且,大数据应用一般是横向分布在多个节点上,流处理框架需要保证横向的伸缩扩展性。可见,状态的管理并不那么容易。
作为一个计算框架,Flink提供了有状态的计算,封装了一些底层的实现,比如状态的高效存储、Checkpoint和Savepoint持久化备份机制、计算资源扩缩容等问题。因为Flink接管了这些问题,开发者只需调用Flink API,这样可以更加专注于业务逻辑。
Flink的几种状态类型
Managed State和Raw State
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。从名称中也能读出两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime托管,自动存储、自动恢复、自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供的常用数据结构,如ListState、MapState等 | 字节数组:byte[] |
| 使用场景 | 绝大多数Flink算子 | 用户自定义算子 |
两者的具体区别有:
- 从状态管理的方式上来说,Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当我们横向伸缩,或者说我们修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。
- 从状态的数据结构上来说,Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。
- 从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。
下文将重点介绍Managed State。
Keyed State和Operator State
对Managed State继续细分,它又有两种类型:Keyed State和Operator State。这里先简单对比两种状态,后续还将展示具体的使用方法。
Keyed State是KeyedStream上的状态。假如输入流按照id为Key进行了keyBy分组,形成一个KeyedStream,数据流中所有id为1的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个自己的状态。下图展示了Keyed State,因为一个算子子任务可以处理一到多个Key,算子子任务1处理了两种Key,两种Key分别对应自己的状态。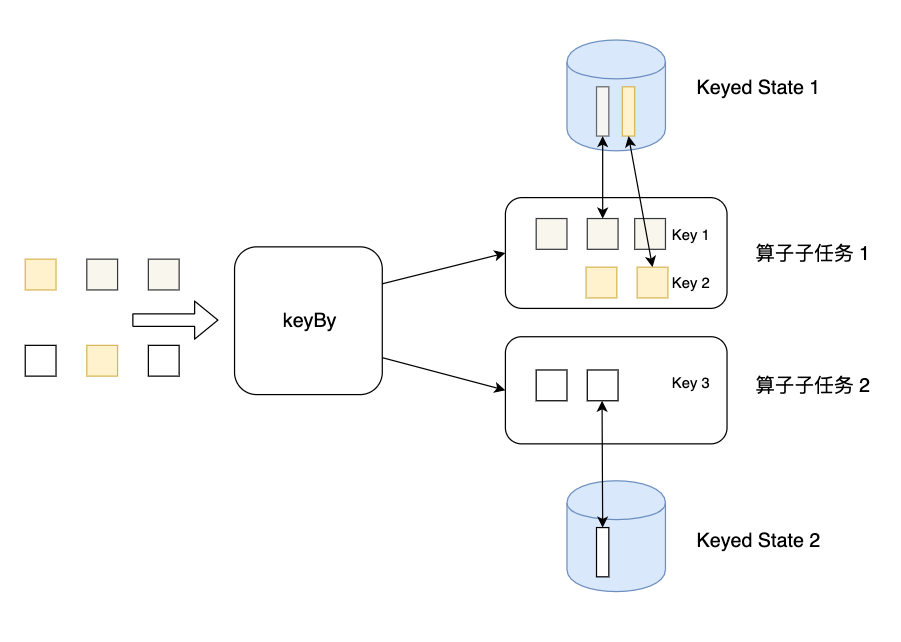
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。下图展示了Operator State,算子子任务1上的所有数据可以共享第一个Operator State,以此类推,每个算子子任务上的数据共享自己的状态。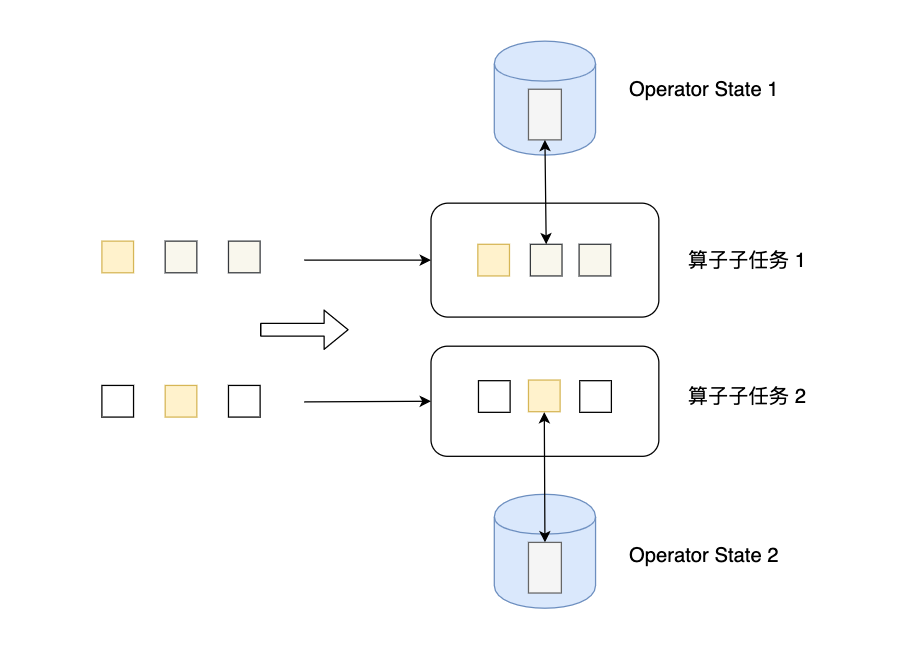
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
在之前各算子的介绍中曾提到,为了自定义Flink的算子,我们可以重写Rich Function接口类,比如RichFlatMapFunction。使用Keyed State时,我们也可以通过重写Rich Function接口类,在里面创建和访问状态。对于Operator State,我们还需进一步实现CheckpointedFunction接口。
| Keyed State | Operator State | |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上的算子 | 可以用于所有算子 |
| 状态分配 | 每个Key对应一个状态 | 一个算子子任务对应一个状态 |
| 创建和访问方式 | 重写Rich Function,通过里面的RuntimeContext访问 | 实现CheckpointedFunction等接口 |
| 横向扩展 | 状态随着Key自动在多个算子子任务上迁移 | 有多种状态重新分配的方式 |
| 支持的数据结构 | ValueState、ListState、MapState等 | ListState、BroadcastState等 |
上表总结了Keyed State和Operator State的区别。
横向扩展问题
状态的横向扩展问题主要是指修改Flink应用的并行度,确切的说,每个算子的并行实例数或算子子任务数发生了变化,应用需要关停或启动一些算子子任务,某份在原来某个算子子任务上的状态数据需要平滑更新到新的算子子任务上。其实,Flink的Checkpoint就是一个非常好的在各算子间迁移状态数据的机制。算子的本地状态将数据生成快照(snapshot),保存到分布式存储(如HDFS)上。横向伸缩后,算子子任务个数变化,子任务重启,相应的状态从分布式存储上重建(restore)。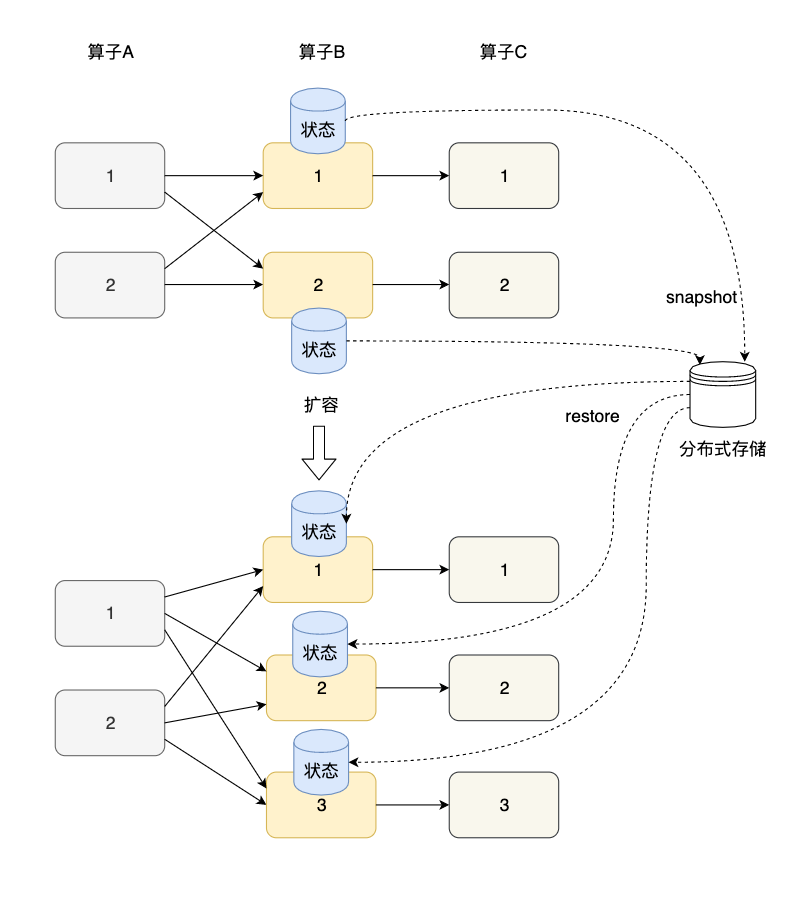
对于Keyed State和Operator State这两种状态,他们的横向伸缩机制不太相同。由于每个Keyed State总是与某个Key相对应,当横向伸缩时,Key总会被自动分配到某个算子子任务上,因此Keyed State会自动在多个并行子任务之间迁移。对于一个非KeyedStream,流入算子子任务的数据可能会随着并行度的改变而改变。如上图所示,假如一个应用的并行度原来为2,那么数据会被分成两份并行地流入两个算子子任务,每个算子子任务有一份自己的状态,当并行度改为3时,数据流被拆成3支,或者并行度改为1,数据流合并为1支,此时状态的存储也相应发生了变化。对于横向伸缩问题,Operator State有两种状态分配方式:一种是均匀分配,另一种是将所有状态合并,再分发给每个实例上。
Keyed State的使用方法
对于Keyed State,Flink提供了几种现成的数据结构供我们使用,包括ValueState、ListState等,他们的继承关系如下图所示。首先,State主要有三种实现,分别为ValueState、MapState和AppendingState,AppendingState又可以细分为ListState、ReducingState和AggregatingState。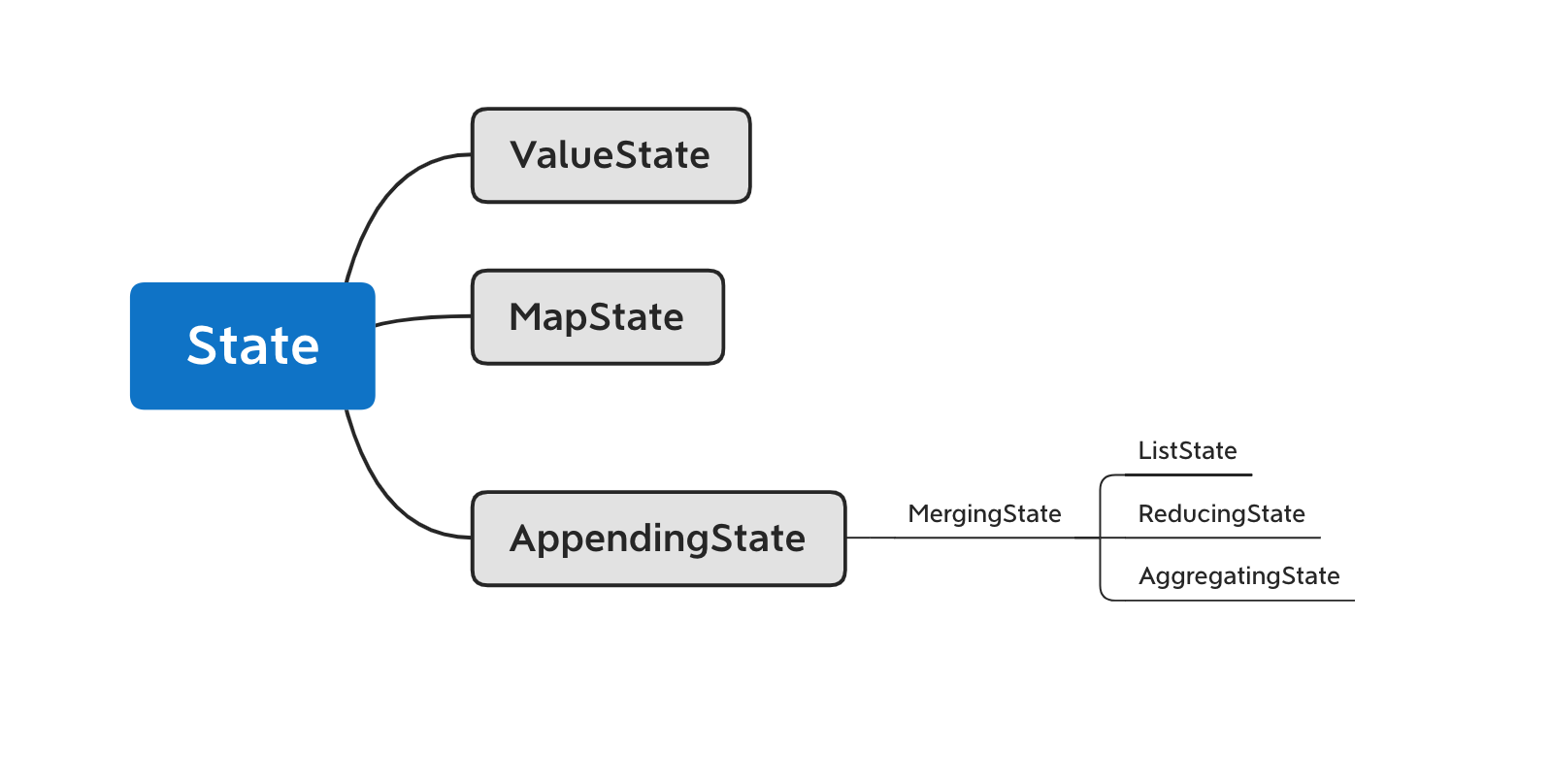
这几个状态的具体区别在于:
- ValueState[T]是单一变量的状态,T是某种具体的数据类型,比如Double、String,或我们自己定义的复杂数据结构。我们可以使用value()方法获取状态,使用update(value: T)更新状态。
- MapState[K, V]存储一个Key-Value map,其功能与Java的Map几乎相同。get(key: K)可以获取某个key下的value,put(key: K, value: V)可以对某个key设置value,contains(key: K)判断某个key是否存在,remove(key: K)删除某个key以及对应的value,entries(): java.lang.Iterable[java.util.Map.Entry[K, V]]返回MapState中所有的元素,iterator(): java.util.Iterator[java.util.Map.Entry[K, V]]返回一个迭代器。需要注意的是,MapState中的key和Keyed State的key不是同一个key。
- ListState[T]存储了一个由T类型数据组成的列表。我们可以使用add(value: T)或addAll(values: java.util.List[T])向状态中添加元素,使用get(): java.lang.Iterable[T]获取整个列表,使用update(values: java.util.List[T])来更新列表,新的列表将替换旧的列表。
- ReducingState[T]和AggregatingState[IN, OUT]与ListState[T]同属于MergingState[T]。与ListState[T]不同的是,ReducingState[T]只有一个元素,而不是一个列表。它的原理是新元素通过add(value: T)加入后,与已有的状态元素使用ReduceFunction合并为一个元素,并更新到状态里。AggregatingState[IN, OUT]与ReducingState[T]类似,也只有一个元素,只不过AggregatingState[IN, OUT]的输入和输出类型可以不一样。ReducingState[T]和AggregatingState[IN, OUT]与窗口上进行ReduceFunction和AggregateFunction很像,都是将新元素与已有元素做聚合。
注意,Flink的核心代码目前使用Java实现的,而Java的很多类型与Scala的类型不太相同,比如List和Map。这里不再详细解释Java和Scala的数据类型的异同,但是开发者在使用Scala调用这些接口,比如状态的接口,需要注意将Java的类型转为Scala的类型。对于List和Map的转换,只需要需要引用import scala.collection.JavaConversions._,并在必要的地方添加后缀asScala或asJava来进行转换。此外,Scala和Java的空对象使用习惯不太相同,Java一般使用null表示空,Scala一般使用None。
Flink Checkpoint机制
如何理解flink中state(状态)
state泛指:flink中有状态函数和运算符在各个元素(element)/事件(event)的处理过程中存储的数据(注意:状态数据可以修改和查询,可以自己维护,根据自己的业务场景,保存历史数据或者中间结果到状态(state)中);
使用状态计算的例子:
- 当应用程序搜索某些事件模式时,状态将存储到目前为止遇到的事件序列。
- 在每分钟/小时/天聚合事件时,状态保存待处理的聚合。
- 当在数据点流上训练机器学习模型时,状态保持模型参数的当前版本。
- 当需要管理历史数据时,状态允许有效访问过去发生的事件。
无状态计算指的是数据进入Flink后经过算子时只需要对当前数据进行处理就能得到想要的结果;
有状态计算就是需要和历史的一些状态或进行相关操作,才能计算出正确的结果;
flink中checkpoint执行流程
- checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 证应用流图状态的一致性。Flink的checkpoint机制原理来自“Chandy-Lamport algorithm”算法。 (分布式快照算)
- 每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作。
- CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier。
- 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状 态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告 自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
- 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身 快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
- 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败 ;
整个过程如下:
- JobManager端的 CheckPointCoordinator向 所有SourceTask发送CheckPointTrigger,Source Task会在数据流中安插CheckPoint barrier
- 当task收到所有的barrier后,向自己的下游继续传递barrier,然后自身执行快照,并将自己的状态异步写入到持久化存储中。增量CheckPoint只是把最新的一部分更新写入到 外部存储;为了下游尽快做CheckPoint,所以会先发送barrier到下游,自身再同步进行快照
- 当task完成备份后,会将备份数据的地址(state handle)通知给JobManager的CheckPointCoordinator;如果CheckPoint的持续时长超过 了CheckPoint设定的超时时间,CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator就会认为本次CheckPoint失败,会把这次CheckPoint产生的所有 状态数据全部删除。
- 最后 CheckPoint Coordinator 会把整个 StateHandle 封装成 completed CheckPoint Meta,写入到hdfs。
什么是barrier对齐?

- 一旦Operator从输入流接收到CheckPoint barrier n,它就不能处理来自该流的任何数据记录,直到它从其他所有输入接收到barrier n为止。否则,它会混合属于快照n的记录和属于快照n + 1的记录;
- 接收到barrier n的流暂时被搁置。从这些流接收的记录不会被处理,而是放入输入缓冲区。
- 上图中第2个图,虽然数字流对应的barrier已经到达了,但是barrier之后的1、2、3这些数据只能放到buffer中,等待字母流的barrier到达;
- 一旦最后所有输入流都接收到barrier n,Operator就会把缓冲区中pending 的输出数据发出去,然后把CheckPoint barrier n接着往下游发送
- 这里还会对自身进行快照;之后,Operator将继续处理来自所有输入流的记录,在处理来自流的记录之前先处理来自输入缓冲区的记录。
什么是barrier不对齐?
checkpoint 是要等到所有的barrier全部都到才算完成
- 上述图2中,当还有其他输入流的barrier还没有到达时,会把已到达的barrier之后的数据1、2、3搁置在缓冲区,等待其他流的barrier到达后才能处理
- barrier不对齐就是指当还有其他流的barrier还没到达时,为了不影响性能,也不用理会,直接处理barrier之后的数据。等到所有流的barrier的都到达后,就可以对该Operator做CheckPoint了;
为什么要进行barrier对齐?不对齐到底行不行?
Exactly Once时必须barrier对齐,如果barrier不对齐就变成了At Least Once;
checkpoint中保存的是什么信息
快照里面到底保存着什么信息呢?以flink消费kafka数据wordcount为例:
我们从Kafka读取到一条条的日志,从日志中解析出app_id,然后将统计的结果放到内存中一个Map集合,app_id做为key,对应的pv做为value,每次只需要将相应app_id 的pv值+1后put到Map中即可;
kafka topic:test;
flink运算流程如下:
kakfa的testtopic的分区 —> Flink的source task —> flink的pv计算task
如何自动获取最新的checkpoint?
现在只知道可以通过-s手动把最新的chk传入到执行程序里,那么如何在java里自动带入最新的chk呢?
在代码中设置如下参数:
Configuration conf = new Configuration();
String lastCheckpintPath = CheckpointUtil.getCkPath(checkpointPath);
conf.setString("execution.savepoint.path", lastCheckpintPath);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
public static String getCkPath(String relativePath) {
try {
Configuration conf = new Configuration();
conf.addResource(CheckpointUtil.class.getResourceAsStream("/core-site.xml"));
conf.addResource(CheckpointUtil.class.getResourceAsStream("/hdfs-site.xml"));
FileSystem fs = FileSystem.get(conf);
FileStatus[] listStatus = fs.listStatus(new Path(relativePath));
List<FileStatus> latestFiles = Arrays.stream(listStatus).sorted(Comparator.comparing(FileStatus::getModificationTime).reversed()).limit(1).collect(Collectors.toList());
if (CollectionUtils.isNotEmpty(latestFiles)) {
FileStatus fileStatus = latestFiles.get(0);
FileStatus[] fileStatuses = fs.listStatus(fileStatus.getPath());
for (FileStatus status : fileStatuses) {
System.out.println(status.getPath().toString());
if (status.getPath().getName().startsWith("chk")) {
return status.getPath().toString();
}
}
}
} catch (Exception ex){
System.err.println(ex.getMessage());
}
return "";
}
Flink广播状态
即broadcaststate,广播至下游所有任务,在本地存储,broadcaststate必须是mapstate类型。对于dataset api中,广播在每个计算节点存储一份,对于datastream 而言,在每个并行度存在一份,算子的每个任务的状态都相同。同时flink watermark和CheckpointBarrier向下游传递时也是基于广播机制。
注意:广播状态会在每个并行度里都保留一份,这就会导致状态被放大。比如,状态本身只有134M,但是,设置了20个并行度,最终在HDFS上的checkpoint会办成2.6G。所以,并行度的设置也会影响ck的大小
Flink Exactly-once语义探究
Flink通过实现两阶段提交和状态保存来实现端到端的一致性语义;
Flink不是默认就有EOS的,flink 官方推荐所有需要保证EOS的sink 逻辑都继承TwoPhaseCommitSinkFunction抽象类。它具体定义如下四个抽象方法。需要我们去在子类中实现。
protected abstract TXN beginTransaction() throws Exception;
protected abstract void preCommit(TXN transaction) throws Exception;
protected abstract void commit(TXN transaction);
protected abstract void abort(TXN transaction);beginTransaction(): 开始一个事务,返回事务信息的句柄。
preCommit :预提交(即提交请求)阶段的逻辑
commit():正式提交阶段的逻辑
abort():取消事务
Flink实现端到端的精准一次
端到端精确一次: flink是通过两步提交的方式实现,内部和外部存储系统间的精确一次语义,即容错发生时每条输入消息依旧只会影响最终结果一次,需满足如下三点:
source: 支持数据可重放,即当容错发生后,支持读取上个state标记后的数据,如kafka offset
link内部:通设置精确一次的checkpoint保障了内部计算在容错时候的精确一次语义
sink:必须支持事物或者幂等操作(继承TwoPhaseCommitSinkFunction抽象类)
使用kafka的sink已经自动实现了,但是,自己写的sink,需要自己继承TwoPhaseCommitSinkFunction抽象类
flink的二阶段提交
两阶段提交(two-phase commit, 2PC)是最基础的分布式一致性协议,应用广泛
2PC 在分布式系统中,为了让每个节点能够感知其他所有节点的事务执行情况,需要我们引入一个中心节点的凡是统一所有节点的执行逻辑和进度。这个中心节点叫做协调者(coordinator),而其中向中心节点汇报或者被中心节点调度的其他节点叫做参与者。
具体过程
请求阶段
1、协调者向所有参与者发送准备请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。
2、参与者执行事务中的包含操作,并记录undo日志(用于回滚)和redo日志(用于重放),但是不真正提交。
3、参与者向协调者返回事务才做的执行结果,执行陈工返回yes,否则返回no.
提交阶段(分成成功和失败两种情况)
若所有的参与者都返回yes,说明事务可以提交。
1、协调者向所有参与者发送commit请求。
2、参与者收到commit 请求后,将事务真正的提交上去,并释放占用的事务资源,并向协调者返回ack。
3、协调者收到所有参与者ack消息,事务成功完成。
事务回滚
若有参与者返回no或者超时未返回,说明事务终端,需要回滚。
1、协调者向所有参与者发送rollback请求。
2、参与者收到rollback请求后,根据undo日志回滚到事务执行前的状态,释放占用的事务资源,并向协调者返回ack。
3、协调者收到所有参与者的ack消息,事务回滚完成。
2PC 的优缺点
优点
2PC的优点在于原理非常简单,容易理解及实现。
缺点
缺点主要有3个,列举如下:
(1)协调者存在单点问题。如果协调者挂了,整个2PC逻辑就彻底不能运行。
(2)、执行过程是完全同步的。各参与者在等待其他参与者响应的过程中都处于阻塞状态,大并发下有性能问题。
(3)、仍然存在不一致风险。如果由于网络异常等意外导致只有部分参与者收到了commit请求,就会造成部分参与者提交了事务而其他参与者未提交的情况。
具体可以参考flink的二阶段提交