本文主要包括:
- DataX学习笔记
DataX概览
DataX 3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX 的设计理念
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。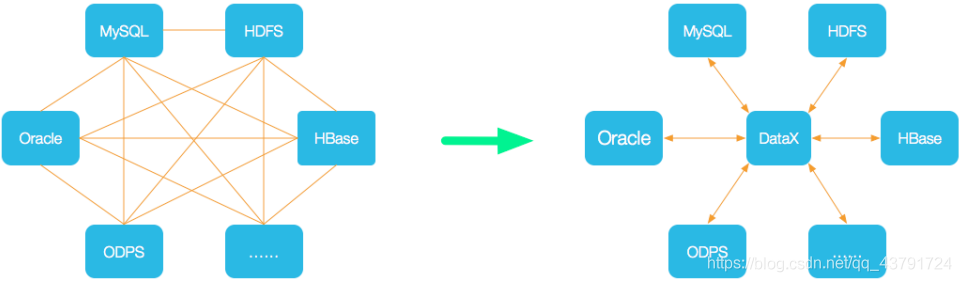
框架设计

- Reader:数据采集模块,负责采集数据源的数据,将数据发给Framework。
- Wiriter: 数据写入模块,负责不断向Framwork取数据,并将数据写入到目的端。
- Framework:用于连接read和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等你核心技术问题。
运行原理
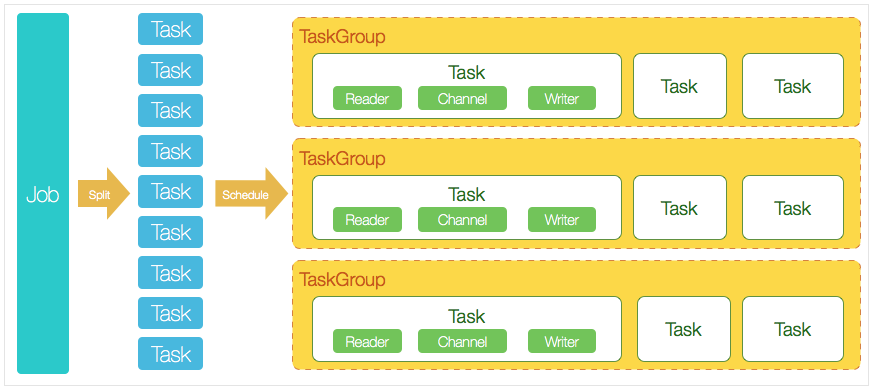
- *核心模块介绍:**
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
DataX3.0插件体系
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 阿里云图数据库 | GDB | √ | √ | 读 、写 |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | 写 | ||
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。
DataX使用案例
DataX通过插件机制,动态的在运行时载入reader和writer进行数据同步的执行。
所以在使用DataX的时候,需要指定reader和writer,确定是数据是从哪里来到哪里去
例如,现在需要采集mysql数据到hive。那么reader其实就是mysql,writer就是hdfs
- 进入到
datax/plugin/reader查看reader下插件目录,从中发现有mysqlreader - 再进入
datax/plugin/writer查看writer下插件目录,从中发现有hdfswriter - 查看官方给的调用模版,执行
bin/datax.py -r mysqlreader -w hdfswriter,得到如下json:{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [], "connection": [ { "jdbcUrl": [], "table": [] } ], "password": "", "username": "", "where": "" } }, "writer": { "name": "hdfswriter", "parameter": { "column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": "" } } } ], "setting": { "speed": { "channel": "" } } } }
注意: 这里的模版只会给必写的选项,非必写的,就不会在这个模版里。例如hadoopConfig
如果要看全部的选项,可以在源码里找到相对应的插件目录,里面有相应的md文件,例如hdfswriter的文档在DataX/hdfswriter/doc/hdfswriter.md
- 编写自己的mysql2hive.json文件,并执行
bin/datax.py job/mysql2hive.json即可
完整的mysql2hive.json案例:
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"`id`",
"`activity_name`",
"`start_time`",
"`end_time`",
"`status`",
"`status_desc`",
"`charge_type`",
"`daily_budgets`",
"`bid`",
"`kb_cost_task_id`",
"`account_type`",
"`bp_id`",
"`bp_type`",
"`bp_name`",
"`shop_id`",
"`shop_name`",
"`create_user`",
"`create_user_name`",
"`create_time`",
"`update_user`",
"`update_time`",
"`yn`",
"`update_user_name`",
"`sales_order_no`"
],
"connection":[
{
"customParam":null,
"jdbcUrl":[
"jdbc:mysql://xxxx:3306/ad_star_store?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"
],
"querySql":null,
"table":[
"hbp_ad_activity"
]
}
],
"mandatoryEncoding":null,
"monthTableMode":"",
"password":"xxxx",
"splitPk":null,
"tableOrView":"1",
"username":"xxxx",
"version":"2",
"where":null
}
},
"transformer":[
{
"name":"proxy_transformer",
"parameter":{
"code":null,
"columnIndex":-1,
"extraPackage":null,
"paras":["1","xxxx","id","activity_name","start_time","end_time","status","status_desc","charge_type","daily_budgets","bid","kb_cost_task_id","account_type","bp_id","bp_type","bp_name","shop_id","shop_name","create_user","create_user_name","create_time","update_user","update_time","yn","update_user_name","sales_order_no"]
}
},
{
"name":"proxy_transformer",
"parameter":{
"code":null,
"columnIndex":-1,
"extraPackage":null,
"paras":["2","xxxx","id","activity_name","start_time","end_time","status","status_desc","charge_type","daily_budgets","bid","kb_cost_task_id","account_type","bp_id","bp_type","bp_name","shop_id","shop_name","create_user","create_user_name","create_time","update_user","update_time","yn","update_user_name","sales_order_no"]
}
}
],
"writer":{
"name":"hdfswriter",
"parameter":{
"column":[
{
"name":"id",
"type":"BIGINT"
},
{
"name":"activity_name",
"type":"STRING"
},
{
"name":"start_time",
"type":"TIMESTAMP"
},
{
"name":"end_time",
"type":"TIMESTAMP"
},
{
"name":"status",
"type":"TINYINT"
},
{
"name":"status_desc",
"type":"STRING"
},
{
"name":"charge_type",
"type":"TINYINT"
},
{
"name":"daily_budgets",
"type":"BIGINT"
},
{
"name":"bid",
"type":"BIGINT"
},
{
"name":"kb_cost_task_id",
"type":"BIGINT"
},
{
"name":"account_type",
"type":"TINYINT"
},
{
"name":"bp_id",
"type":"STRING"
},
{
"name":"bp_type",
"type":"TINYINT"
},
{
"name":"bp_name",
"type":"STRING"
},
{
"name":"shop_id",
"type":"STRING"
},
{
"name":"shop_name",
"type":"STRING"
},
{
"name":"create_user",
"type":"STRING"
},
{
"name":"create_user_name",
"type":"STRING"
},
{
"name":"create_time",
"type":"TIMESTAMP"
},
{
"name":"update_user",
"type":"STRING"
},
{
"name":"update_time",
"type":"TIMESTAMP"
},
{
"name":"yn",
"type":"INT"
},
{
"name":"update_user_name",
"type":"STRING"
},
{
"name":"sales_order_no",
"type":"STRING"
}
],
"compress":null,
"defaultFS":"hdfs://xxxx",
"fieldDelimiter":"\t",
"fileName":"hbp_ad_activity",
"fileType":"text",
"hadoopConfig":{
"fs.defaultFS":"hdfs://xxxx",
"dfs.ha.namenodes.HZWONE":"nn1,nn2",
"dfs.nameservices":"xxxx",
"dfs.namenode.rpc-address.HZWONE.nn2":"hdfs://xxxx:xxxx",
"dfs.namenode.rpc-address.HZWONE.nn1":"hdfs://xxxx:xxxx",
"dfs.client.failover.proxy.provider.HZWONE":"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},
"path":"xxxx",
"writeMode":"append"
}
}
}
],
"setting":{
"errorLimit":null,
"speed": {
"channel": 4,
"record":-1,
"byte":-1,
"batchSize":10240
}
}
}
}hadoopConfig是为了datax往hdfs写数据如何配置高可用
DataX定制化插件开发与使用
DataX为什么要使用插件机制?
从设计之初,DataX就把异构数据源同步作为自身的使命,为了应对不同数据源的差异、同时提供一致的同步原语和扩展能力,DataX自然而然地采用了框架 + 插件的模式:
- 插件只需关心数据的读取或者写入本身。
- 而同步的共性问题,比如:类型转换、性能、统计,则交由框架来处理。
作为插件开发人员,则需要关注两个问题:
数据源1. 本身的读写数据正确性。
如何与2. 框架沟通、合理正确地使用框架。
插件视角看框架
逻辑执行模型
插件开发者不用关心太多,基本只需要关注特定系统读和写,以及自己的代码在逻辑上是怎样被执行的,哪一个方法是在什么时候被调用的。在此之前,需要明确以下概念:
- Job: Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到odps的一个表的特定分区。
- Task: Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,用若干个并发执行。
- TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroup
- JobContainer: Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。类似Yarn中的JobTracker
- TaskGroupContainer: TaskGroup执行器,负责执行一组Task的工作单元,类似Yarn中的TaskTracker。
简而言之, Job拆分成Task,在分别在框架提供的容器中执行,插件只需要实现Job和Task两部分逻辑。
物理执行模型
框架为插件提供物理上的执行能力(线程)。DataX框架有三种运行模式:
- Standalone: 单进程运行,没有外部依赖。
- Local: 单进程运行,统计信息、错误信息汇报到集中存储。
- Distrubuted: 分布式多进程运行,依赖DataX Service服务。
当然,上述三种模式对插件的编写而言没有什么区别,你只需要避开一些小错误,插件就能够在单机/分布式之间无缝切换了。 当JobContainer和TaskGroupContainer运行在同一个进程内时,就是单机模式(Standalone和Local);当它们分布在不同的进程中执行时,就是分布式(Distributed)模式。
编程接口
那么,Job和Task的逻辑应是怎么对应到具体的代码中的?
首先,插件的入口类必须扩展Reader或Writer抽象类,并且实现分别实现Job和Task两个内部抽象类,Job和Task的实现必须是 内部类 的形式,原因见 加载原理 一节。
具体参考DataX插件开发宝典
插件定义
代码写好了,有没有想过框架是怎么找到插件的入口类的?框架是如何加载插件的呢?
在每个插件的项目中,都有一个plugin.json文件,这个文件定义了插件的相关信息,包括入口类。例如:
{
"name": "mysqlwriter",
"class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter",
"description": "Use Jdbc connect to database, execute insert sql.",
"developer": "alibaba"
}- name: 插件名称,大小写敏感。框架根据用户在配置文件中指定的名称来搜寻插件。 十分重要 。
- class: 入口类的全限定名称,框架通过反射插件入口类的实例。十分重要 。
- description: 描述信息。
- developer: 开发人员。
打包发布
DataX使用assembly打包,assembly的使用方法请咨询谷哥或者度娘。打包命令如下:mvn clean package -DskipTests assembly:assembly
DataX插件需要遵循统一的目录结构:${DATAX_HOME} |-- bin | `-- datax.py |-- conf | |-- core.json | `-- logback.xml |-- lib | `-- datax-core-dependencies.jar `-- plugin |-- reader | `-- mysqlreader | |-- libs | | `-- mysql-reader-plugin-dependencies.jar | |-- mysqlreader-0.0.1-SNAPSHOT.jar | `-- plugin.json `-- writer |-- mysqlwriter | |-- libs | | `-- mysql-writer-plugin-dependencies.jar | |-- mysqlwriter-0.0.1-SNAPSHOT.jar | `-- plugin.json |-- oceanbasewriter `-- odpswriter - ${DATAX_HOME}/bin: 可执行程序目录。
- ${DATAX_HOME}/conf: 框架配置目录。
- ${DATAX_HOME}/lib: 框架依赖库目录。
- ${DATAX_HOME}/plugin: 插件目录。
插件目录分为reader和writer子目录,读写插件分别存放。插件目录规范如下:
- ${PLUGIN_HOME}/libs: 插件的依赖库。
- ${PLUGIN_HOME}/plugin-name-version.jar: 插件本身的jar。
- ${PLUGIN_HOME}/plugin.json: 插件描述文件。
尽管框架加载插件时,会把${PLUGIN_HOME}下所有的jar放到classpath,但还是推荐依赖库的jar和插件本身的jar分开存放。
注意: 插件的目录名字必须和plugin.json中定义的插件名称一致。
配置文件
DataX使用json作为配置文件的格式。
具体参考DataX插件开发宝典
问题:
hdfswriter写到hdfs只会产生一个文件,是因为并发为1嘛?
这里需要确认一下
公司写hudi的时候,仅在实时用的是spark,在离线初始化的时候使用了datax,这里没有用spark重写datax的writer,用spark写不了data的writer
抽取本地mysql报如下错误
报mysql链接不上,报错日志如下:
ERROR RetryUtil - Exception when calling callable, 异常Msg:DataX无法连接对应的数据库,可能原因是: 1) 配置的ip/port/database/jdbc错误,无法连接。 2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的连接信息是否正确。*解决办法:**
datax里面的mysql驱动更换成合适的8.x的版本就好了:报值非法
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 任务读取配置文件出错. 配置文件路径[job.setting.speed.channel] 值非法, 期望是整数类型: For input string: "". 请检查您的配置并作出修改.
Datax读写hdfs配置HA高可用
"defaultFS":"hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode71,namenode123",
"dfs.namenode.rpc-address.nameservice1.namenode71": "ddp1:8020",
"dfs.namenode.rpc-address.nameservice1.namenode123": "ddp2:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
},每个参数分别对用hdfs-site.xml文件配置信息
这里一定要注意,参数值是变化的,每个环境都不一样。需要看下hdfs-site.xml
使用json文件,并向json文件传参
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "digiwin@123",
"column": ["*"],
"connection": [{
"table": ["${tableName}"],
"jdbcUrl": ["jdbc:mysql://47.100.1.105:19030/${dbName}"]
}]
}
},
"writer": {
"name": "starrockswriter",
"parameter": {
"username": "servicecloud",
"password": "servicecloud@123",
"database": "${dbName}",
"table": "${tableName}",
"column": ["*"],
"preSql": [],
"postSql": [],
"jdbcUrl": "jdbc:mysql://ddp2:19030/",
"loadUrl": ["ddp2:18030"],
"loadProps": {}
}
}
}
]
}
}执行datax任务:
/opt/soft/datax/bin/datax.py star2star.json -p"-DtableName=${table} -DdbName=${dbName}"任务正常启动后,数据写入一直不变,也不报错
日志一直打印:
2020-02-28 10:50:41.198 [job-0] INFO StandAloneJobContainerCommunicator - Total 3411 records, 3249695540 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 213.975s | All Task WaitReaderTime 0.918s | Percentage 0.00%
2020-02-28 10:50:51.198 [job-0] INFO StandAloneJobContainerCommunicator - Total 3411 records, 3249695540 bytes | Speed 0B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 213.975s | All Task WaitReaderTime 0.918s | Percentage 0.00%出现原因:
由于Starrocks设定了查询超时时间,DataX数据同步使用流式数据读取,导致数据读取超过了数据库指定的查询超时时间,数据读取被中断,DataX没有报错,出现了Speed一直为0的情况。
处理方法:
可以暂时将数据库的query_timout参数调大,保证数据同步时间不会超过该值。set global query_timeout=3000;
具体可以参考任务正常启动后,数据写入一直不变,也不报错
datax写starrocks,限速
{
"core": {
"transport" : {
"channel": {
"speed": {
"record": 5000
}
}
}
},
"job": {
"content": [{
"reader": {
"name": "sqlserverreader",
"parameter": {
"username": "sa",
"password": "L@ntegx2011",
"column": [
"ID","VEHICLENO", "LOTNO","PRODUCTION_SN","PRODUCTION_WIDTH","PRODUCTION_LOCATION","ISCHANGE","USER_DEFINED01","USER_DEFINED02","CREATOR","CREATEDATE","MODIFY","MODIFYDATE","MERGE_VEHICLENO","MERGE_DATE","PROD_STATUS","OPNO","POTNO","C_USERNO","USER_DEFINED03"
],
"connection": [{
"table": [
"TBLVehiclePrdRelation_2023"
],
"jdbcUrl": [
"jdbc:sqlserver://192.168.101.69:1433;DatabaseName=SMES_DW"
]
}]
}
},
"writer": {
"name": "starrockswriter",
"parameter": {
"username": "root",
"password": "digiwin@123",
"database": "SMESPROD",
"table": "ODS_TBLVEHICLEPRDRELATION_2023",
"column": ["ID","VEHICLENO", "LOTNO","PRODUCTION_SN","PRODUCTION_WIDTH","PRODUCTION_LOCATION","ISCHANGE","USER_DEFINED01","USER_DEFINED02","CREATOR","CREATEDATE","MODIFY","MODIFYDATE","MERGE_VEHICLENO","MERGE_DATE","PROD_STATUS","OPNO","POTNO","C_USERNO","USER_DEFINED03"],
"preSql": [],
"postSql": [],
"jdbcUrl": "jdbc:mysql://ddp1:29030/",
"loadUrl": ["ddp1:28030"],
"loadProps": {
"format": "json",
"strip_outer_array": true,
"column_separator": "\\x01",
"row_delimiter": "\\x02"
}
}
}
}],
"setting": {
"errorLimit": {
"record": 0,
"percentage": 0
},
"speed": {
"channel": 1
}
}
}
}具体可以参考Datax限速bug