本文主要包括:
- 采集写入hudi设计文档
采集hudi表结构设计
采集hudi表目录:
hudi表目录:/apps/hudi/warehouse/fdm/tableName
hudi删除表目录:/apps/hudi/warehouse/fdm/tableName_del
采集hudi表外表hive表
- 读优化视图表:tableName_ro
- 快照视图:tableName_rt
按月分区表
/basePath/tableName/2021-07/
/basePath/tableName/2021-08/
/basePath/tableName/…/
/basePath/tableName/2021-09/
概述:根据创建日期所在月分区,按月分区表适合大部分业务场景,业务每天数据量不是很大,或者数据变更不是很频繁,按月分区表以dam结尾。
优点:减少Hdfs小文件数量,hudi表使用MOR格式。
缺点:数据倾斜导致一个分区数据很大,分区内更新效率低
按日分区表
/basePath/tableName/2021-08-16/
/basePath/tableName/2021-08-17/
/basePath/tableName/…/
/basePath/tableName/2021-09-14/
概述:根据创建日期分区,按日分区表适合业务每天数据量很大,或者数据变更频繁,适用于读少写多大表场景,按日分区表以dad结尾。
优点:优化写入效率,hudi表使用MOR格式。
缺点:分区越来越多,hive查询效率低,数据倾斜导致一个分区数据量很少,带来小文件问题
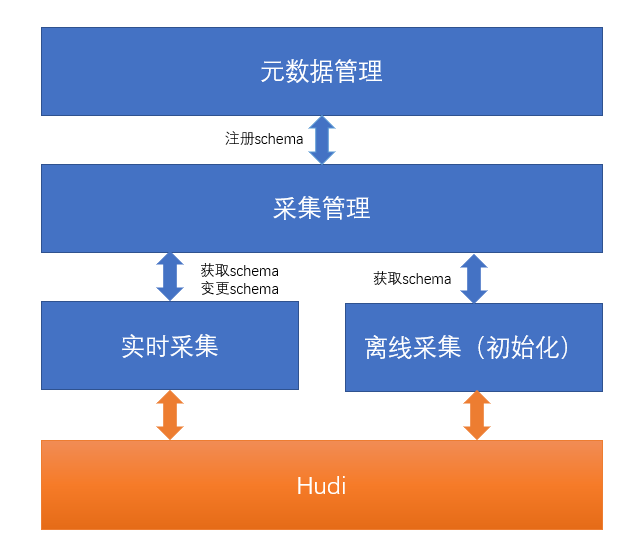
采集表元数据管理
元数据管理流程
hudi schema限制
- hudi支持类型有null、boolean、int、long、float、double、bytes、string、array、map、enum
- 不能删除字段,不能修改字段名
- 添加字段需要有默认值
- 字段类型修改只允许如下变化:int修改成long,int、long修改成float,int、long、float修改成double,bytes修改成string,string修改成bbytes
mysql hudi字段类型映射
| 序号 | mysql | hudi |
|---|---|---|
| 1 | VARCHAR | string |
| 2 | DATE | string |
| 3 | CHAR | string |
| 4 | TINYINT | int |
| 5 | SMALLINT | int |
| 6 | DATETIME | long(string)hudi不支持时间类型,可以存储时间戳 |
| 7 | TEXT | string |
| 8 | TIMESTAMP | long(string)hudi不支持时间类型,可以存储时间戳 |
| 9 | INT | int |
| 10 | BIT | int |
| 11 | VARBINARY | string |
| 12 | LONGTEXT | string |
| 13 | DECIMAL | string |
| 15 | DOUBLE | double |
| 16 | BIGINT | long |
| 17 | BLOB | string |
| 18 | TINYINT UNSIGNED | int |
| 19 | SMALLINT UNSIGNED | int |
| 20 | INT UNSIGNED | long |
| 21 | BIGINT UNSIGNED | long |
| 22 | FLOAT UNSIGNED | float |
| 23 | DOUBLE UNSIGNED | double |
| 24 | FLOAT | float |
| 25 | MEDIUMINT UNSIGNED | int |
采集初始化根据数据创建日期采集到数据日期所在月份的分区,示意图如3-1: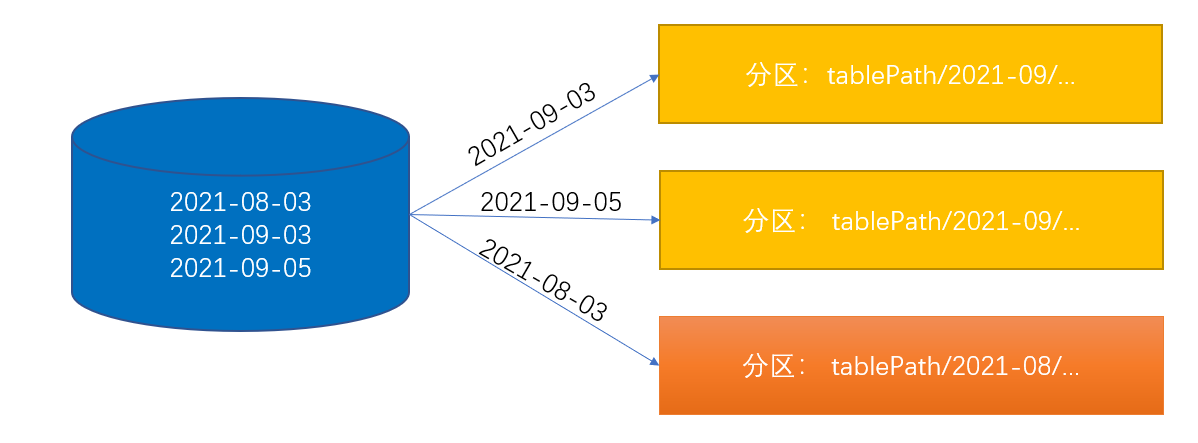
采集初始化由采集模块发起,请求调度,调度触发脚本机执行初始化任务,脚本机启动使用spark任务采集关系数据库数据,spark任务使用Datax采集MySQL、MongoDB,使用Hudi-spark-client模块将数据写入Hudi,示意图如3-2
这里依然生成了调度任务,只是在初始化的时候用了一次,可以简化成采集直接和脚本机接入,由采集直接触发脚本机执行任务,但是这个改动量比较大。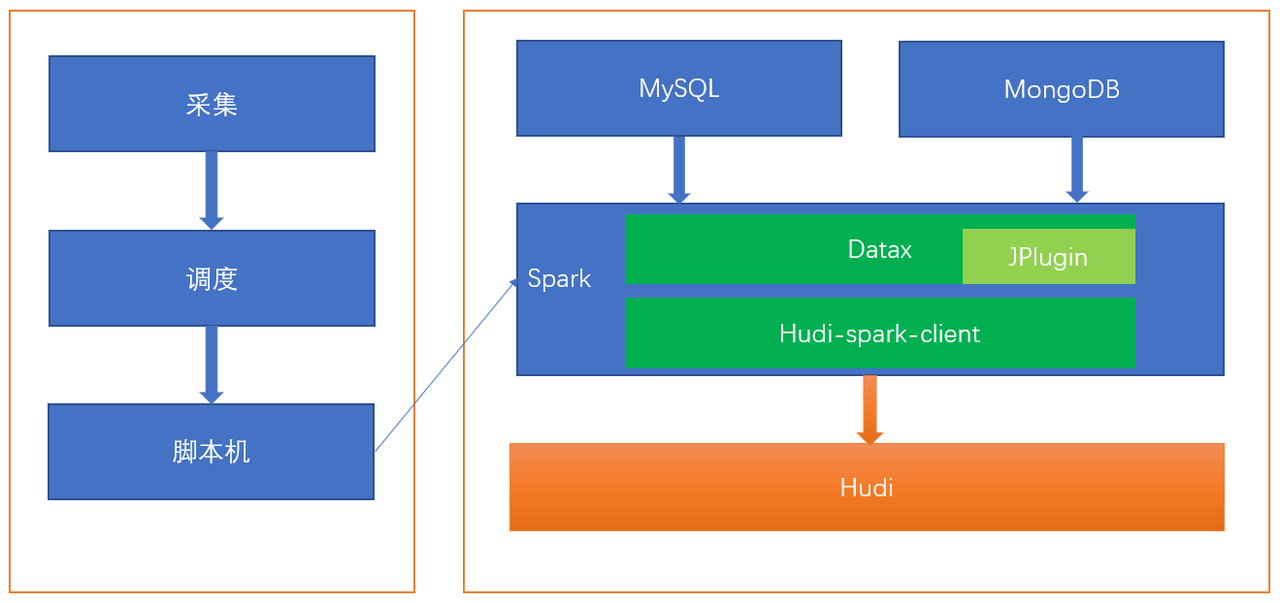
采集实时写入hudi
- 插入数据记录,直接插入到hudi原表
- 更新数据记录,直接更新hudi原表记录
- 删除数据记录,直接删除hudi原表记录,同时插入hudi删除表
- 以分钟频率拉取kafka记录摄入hudi,减少元数据提交次数
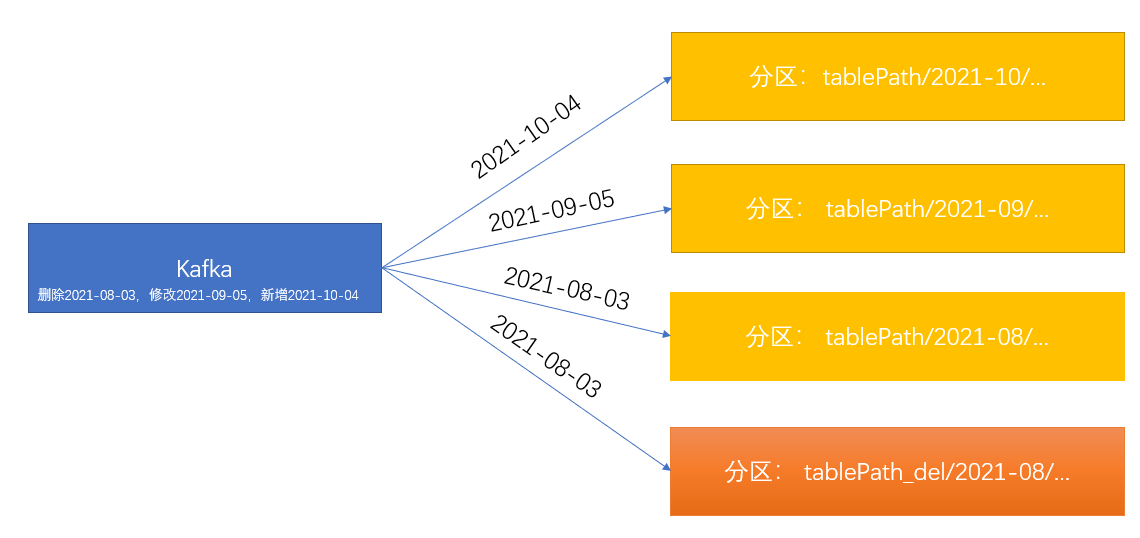
采集实时写入hudi由采集模块发起,在启动实时写入任务的时候将采集任务分配到固定的Flink节点,通过ESF和Flink节点通信,在Flink节点启动线程执行实时写入hudi任务,任务以每分钟频率拉取,使用Hudi-flink-client模块将数据写入Hudi,示意图如4-2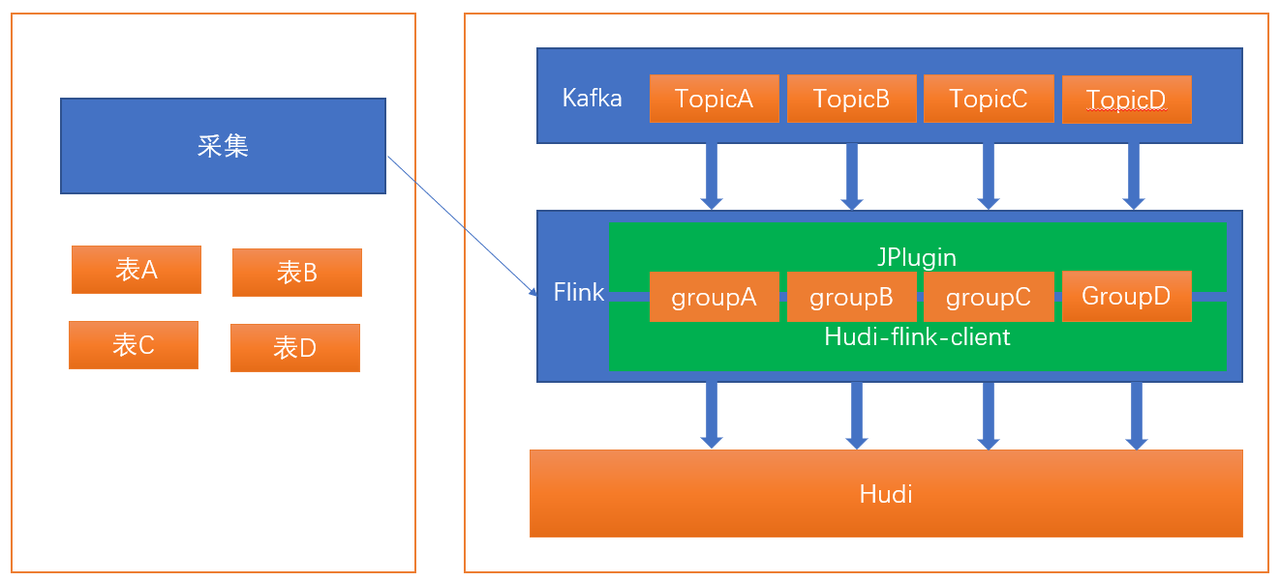
异步合并parquet任务
对于Merge-On-Read表,数据使用列式Parquet文件和行式Avro文件存储,更新被记录到增量文件,然后进行同步/异步compaction生成新版本的列式文件。Merge-On-Read表可减少数据写入延迟,因而进行不阻塞摄入的异步Compaction很有意义,流程如下图5-1
创建一个调度任务,调度任务每个小时触发一次合并任务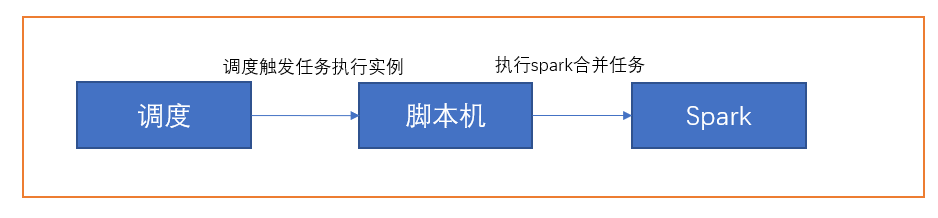
- Flink节点心跳检查
- 实时摄入任务每分钟(单次)写入耗时、写入insert条数、写入update条数、写入delete条数、写入数据条数、写入数据量,上报统一监控
- 异步合并parquet任务合并log文件数、合并耗时,上报统一监控
- 实时写入失败情况下报警
管理界
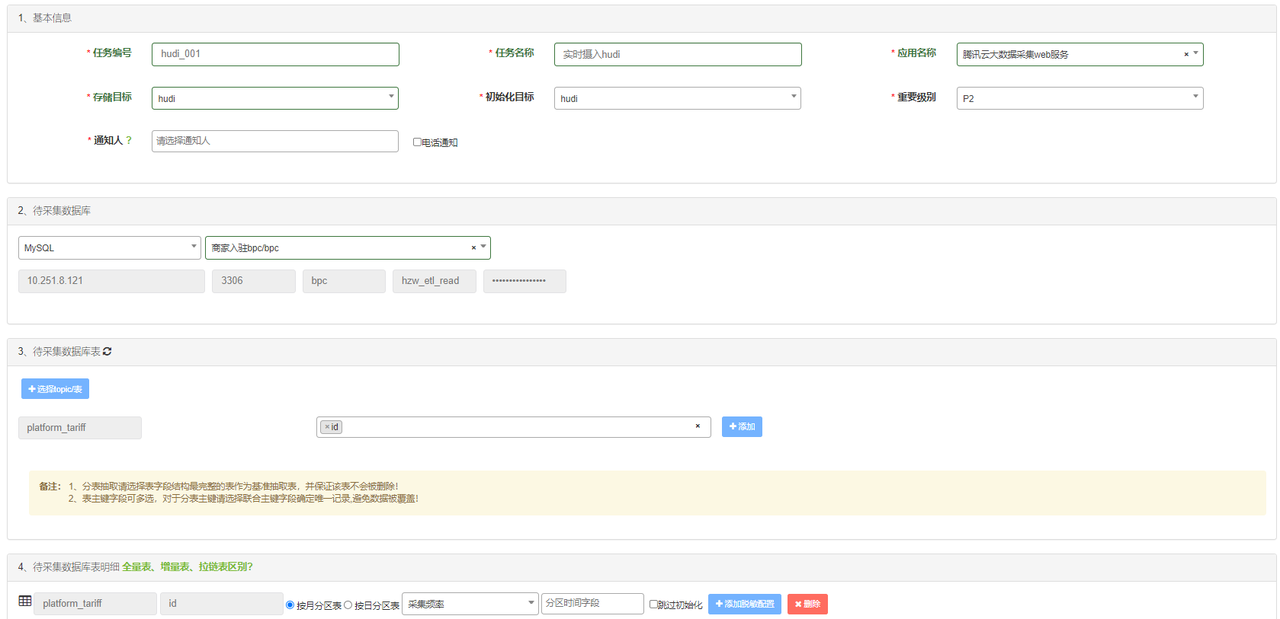
- 存储目标添加hudi存储方式
- 提供按月分区、按日分区,根据近半年每日新增数据分析初始值,可修改
- 采集频率默认1m,提供30s、2m可选项
- 分区时间字段,例如创建时间
FDM表(hudi)后续使用特点
- 实时采集默认都走hudi,全量表,拉链表功能保留,有需要可以用,不建议用
- 任务使用建议走spark引擎
问题列表
- 无创建时间表分区问题