本文主要包括:
- hudi和iceberg测试比较
背景和需求
当前采集系统分为实时采集、定时采集,实时采集当天数据存在Hbase中,当天以前的数据存在Hive中。定时采集只有当天以前的数据。随着业务的要求越来越高,T+1的延时已经无法满足业务的的使用场景,数据实时性是采集系统亟需改善的一个地方。
我们也尝试使用了Kudu来解决这个问题,Kudu是一个列式存储的存储引擎,不兼容Hdfs,其次孩子王Kudu系统也不稳定,所以没有把整个表的数据写入Kudu,而是使用Kudu替代了Hbase,解决了Hbase批量查询的性能问题,但还是没有通过一个组件解决采集的实时性问题。
总结下来就是,采集系统需要将原系统数据实时采入单个组件,可以达到分钟级的延迟。同时提供高性能的查询方式给业务查询。数据湖很早就进入我们的视野,目前主流的就是Iceberg和Hudi,本文就是从原理、特性、性能上对比两个数据湖组件。
Hudi介绍
存储
Hudi使用Hadoop FileSystem API与湖存储交互,Hudi充分利用了像HDFS之类的存储模式所支持的“append”特性。这有助于Hudi提供流时写入,而不会导致文件计数/表元数据激增。
文件格式
Hudi是围绕基本文件和增量日志文件的概念设计的,它们将更新 / 增量数据存储到给定的基本文件(称为文件片,file slice)。基本文件格式包括 Parquet(列访问)和 HFile(索引访问),增量日志以 Avro(面向行)。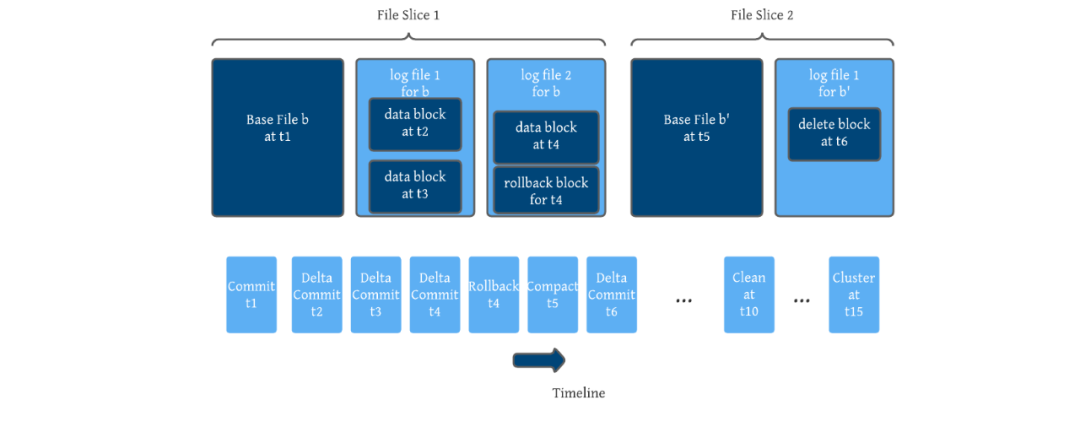
表格式
表格式包括表的文件布局、表的schema、表变更的元数据跟踪。Hudi使用Avro模式来存储、管理和演进表的schema。Hudi有意识地将表/分区中的文件分组,并维护记录的键与所有文件组之间的映射,所有更新都记录到特定于文件组的增量日志文件中,Hudi的设计理念基于键的快速upserts/deletes,并且只需要在每个文件组中合并delta日志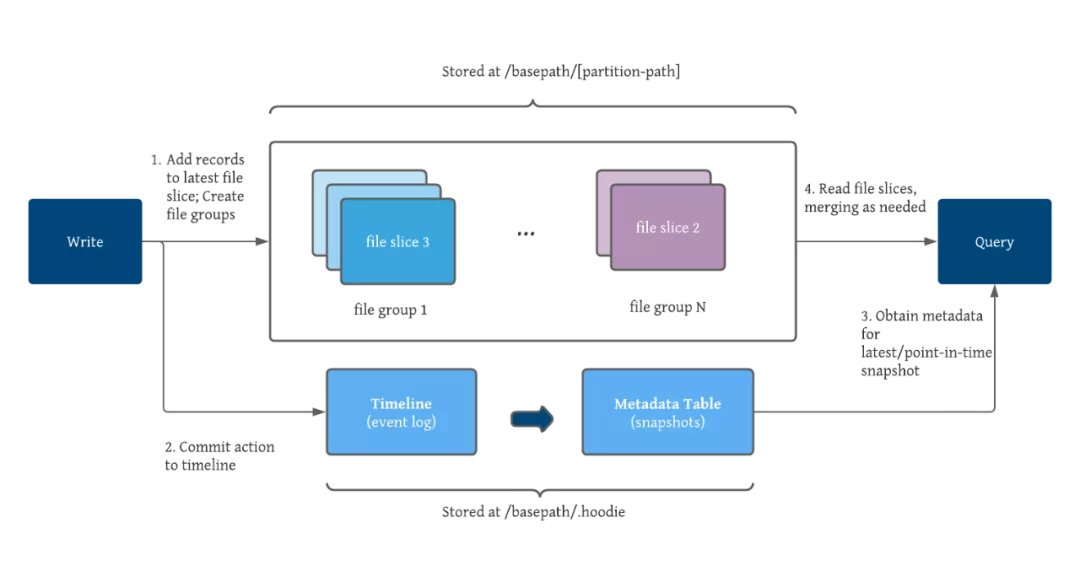
表类型和查询
Hudi支持两种类型的表,COW(Copy-On-Write),MOR(Merge-On-Read),COW表的写放大问题严重,MOR提供了低延迟、更高效地实时写入,但读取的时候需要更高的延迟
| COW | MOR | |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| 更新成本 | 高(重写整个parquet) | 低(添加到delta日志大小) |
| Parquet文件大小 | 小 | 大 |
| 写放大 | 高 | 低 |
Hudi支持三种类型的查询,快照查询(能够查询到表的最新快照数据,如果是MOR表,会将基本文件和增量文件合并后再提供数据)、增量查询(增量查询只能查看到写入表的新数据)、读优化查询(可以查询到表的最新快照数据,它近查询最新的基本列文件,可以保证查询性能,这种方式保证了性能,但数据可能会有延迟)
| 表类型 | 支持的查询类型 |
|---|---|
| COW | 快照查询、增量查询 |
| MOR | 快照查询、增量查询、读优化查询 |
索引
Hudi支持不同的基于主键的索引方案,以快速将采集的记录键映射到他们所在的文件组中。Hudi会自动强制执行文件大小,这有助于降低从Parquet页脚读取统计信息所需的时间。
并发控制
定义了不同的写入器/读取器如何协调对表的访问。Hudi确保原子写入,通过将提交原子地发布到时间线,并标记一个即时时间(instant),以标记该操作具体发生的时间。Hudi明确区分了写入进程(执行用户的更新、插入、删除)、表服务(写入数据、元数据以优化执行所需的信息)和读取器(执行查询),Hudi在所有三种类型的进程之间提供快照隔离,他们都对表的一致快照进行操作。
写入器
Hudi表可以用作Spark/Flink管道的接收器,upsert、delete操作都会自动处理输入流中具有相同键的记录的预合并,然后查找索引,最后调用二进制打包算法将数据打包到文件中,同时遵循预配置的目标文件大小。
读取器
Hudi在写入器和读取器之间提供了快照隔离,并允许所有主流的湖查询引擎(Spark、Hive、Presto)在任何表快照上进行一致的查询,每当Hudi必须为查询合并基础文件和日志文件时,Hudi都会进行控制并采用多种机制来提高合并性能,同时还提供对数据的读优化查询,以权衡数据新鲜度与查询性能。
hudi支持建表、写入时将数据同步到hive元数据,生成ro、rt表,支持hive查询,支持presto使用presto连接器查询
表服务
为了让Hudi能作为增量数据管道的状态存储,为其设计了内置的表服务和自我管理运行时,可以编排/触发这些服务并在内部优化一切,Hudi有几个内置的表服务,目标都是确保高性能的表存储布局和元数据管理,他们在每次写入操作后同步自动调用,或者作为单独的后台作业异步调用。
- 归档服务:一旦事件从时间线上过期,归档服务就会清除湖缓存的任何副作用。
- 清理服务:以增量的方式,删除超过保留期限的用于增量查询的文件切片
- 压缩服务:将基本文件与一组增量日志文件合并以生成新的基本文件,同时允许对文件组进行并发写入
- 聚簇服务:用户可以通过排序键将经常查询的记录组合在一起,或者通过将较小的基本文件合并为较大的文件来控制文件大小
数据服务
Hudi能对常见的端到端用例做到开箱即用,最重要的是DeltaStreamer实用程序,可以轻松基于Kafka流以及在湖存储之上的不同格式的文件来构建数据湖。支持检查点的自动管理、跟踪源检查点作为Hudi表元数据的一部分
hudi测试案例
Flinksql写数据入hudi
flink以sql-client的方式启动
- 在flinksql中创建t1表:
CREATE TABLE t1( uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20) ) WITH ( 'connector' = 'hudi', 'path' = 'hdfs:///user/hive/warehouse/hudi.db/t1', 'table.type' = 'MERGE_ON_READ' ); - 向t1表插入几条数据并查询结果
--插入数据 INSERT INTO t1 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'); -- 查询数据 select * from t1; - 查询hdfs上文件记录
###同步hudi元数据到hivehadoop fs -ls hdfs:///user/hive/warehouse/hudi.db/t1 -rw-r--r-- 1 gujincheng supergroup 1397 2022-04-06 09:33 hdfs:///user/hive/warehouse/hudi.db/t1/.cbde2bbe-5097-44e9-a5b1-7419be14b63e_20220406093302182.log.1_3-4-0 drwxr-xr-x - gujincheng supergroup 0 2022-04-06 09:33 hdfs:///user/hive/warehouse/hudi.db/t1/.hoodie -rw-r--r-- 1 gujincheng supergroup 96 2022-04-06 09:33 hdfs:///user/hive/warehouse/hudi.db/t1/.hoodie_partition_metadata
一般来说Hudi表在用Spark或者Flink写入数据时会自动同步到Hive外部表, 此时可以直接通过beeline查询同步的外部表, 若写入引擎没有开启自动同步,则需要手动利用hudi客户端工具run_hive_sync_tool.sh 进行同步具体可以参考官网查看相关参数。
上述创建的表,没有开启自动同步,需要使用run_hive_sync_tool.sh进行同步hive环境准备
- 将 hudi-hadoop-mr-bundle 导入 hive。在 hive 根目录下创建 auxlib/ 文件夹,并将 hudi-hadoop-mr-bundle-0.x.x-SNAPSHOT.jar 移动到 auxlib 中。 hudi-hadoop-mr-bundle-0.x.x-SNAPSHOT.jar 位于包/hudi-hadoop-mr-bundle/target。
cd /opt/modules/hive-2.3.9/ && mkdir auxlib cp ~/hudi/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.10.1.jar auxlib - Flink sql客户端远程连接hive metastore时,需要开启hive metastore和hiveserver2服务,并且需要正确设置端口号。开启服务的命令:
# Enable hive metastore and hiveserver2 nohup ./bin/hive --service metastore & nohup ./bin/hive --service hiveserver2 & # While modifying the jar package under auxlib, you need to restart the service. - Flink hive sync 现在支持 hms(hive metastore sync) 和 jdbc 两种 hive 同步模式。 hms 模式只需要配置 metastore uris。对于 jdbc 模式,JDBC 属性和 Metastore uris 都需要配置
所以,hive的metastore是必须的
flinksql自动同步hive元数据
- 在sql-client里创建hudi表:
CREATE TABLE t2( uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20) ) WITH ( 'connector' = 'hudi', 'path' = 'hdfs:///user/hive/warehouse/hudi.db/t2', 'table.type' = 'MERGE_ON_READ', 'hive_sync.enable' = 'true', -- Required. To enable hive synchronization 'hive_sync.mode' = 'hms', -- Required. Setting hive sync mode to hms, default jdbc 'hive_sync.metastore.uris' = 'thrift://golden-02:9083', -- Required. The port need set on hive-site.xml 'hive_sync.table'='t2', -- required, hive table name 'hive_sync.db'='hudi' ); - 向表中插入几条数据
INSERT INTO t2 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3');flinkcdc 读取mysql并写入hudi
- 创建mysql表
--- 创建mysql表 CREATE TABLE users_source_mysql ( uuid varchar(10) PRIMARY KEY , name varchar(10), age int, ts timestamp, part varchar(10) ); -- 向表中插入数据 INSERT INTO users_source_mysql VALUES ('id1','Danny',23, '2021-01-01 00:00:00','par1'), ('id2','Stephen',33, '2021-01-01 00:00:02','par1'), ('id3','Julian',53, '2021-01-01 00:00:03','par2'), ('id4','Fabian',31, '2021-01-01 00:00:04','par2'), ('id5','Sophia',18, '2021-01-01 00:00:05','par3'), ('id6','Danny',23, '2021-01-01 00:00:01','par1'), ('id7','Stephen',33, '2021-01-01 00:00:02','par1'), ('id8','Julian',53, '2021-01-01 00:00:03','par2'), ('id9','Fabian',31, '2021-01-01 00:00:04','par2'), ('id10','Sophia',18, '2021-01-01 00:00:05','par3'); - 在flinksql中创建映射表
set sql-client.execution.result-mode=tableau; -- 因为是流式写数据,所以,必须得开启ck,否则会报错 set execution.checkpointing.interval=3sec; CREATE TABLE users_source_mysql ( uuid string PRIMARY KEY NOT ENFORCED, name STRING, age int, ts timestamp(3), part string ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '150.158.190.192', 'port' = '3306', 'username' = 'root', 'password' = 'Gjc123!@#', 'server-time-zone' = 'Asia/Shanghai', 'debezium.snapshot.mode' = 'initial', 'database-name' = 'test', 'table-name' = 'users_source_mysql' ); - 写数据到hudi
数据在hive和spark中都能查询到数据--创建hudi表 CREATE TABLE t2_tmp( uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts timestamp(3), part VARCHAR(20) ) WITH ( 'connector' = 'hudi', 'path' = 'hdfs://golden-02:9000/user/hive/warehouse/hudi.db/t2', 'table.type' = 'MERGE_ON_READ', 'hoodie.datasource.write.recordkey.field'= 'uuid', 'write.precombine.field'= 'ts', 'write.tasks' = '1', 'write.rate.limit' = '2000', 'compaction.tasks' = '1', 'compaction.async.enabled' = 'true', 'compaction.trigger.strategy' = 'num_commits', 'compaction.delta_commits' = '1', 'changleog.enabled' = 'true', 'read.streaming.enabled'= 'true', 'read.streaming.check-interval'= '3', 'hive_sync.enable' = 'true', -- Required. To enable hive synchronization 'hive_sync.mode' = 'hms', -- Required. Setting hive sync mode to hms, default jdbc 'hive_sync.metastore.uris' = 'thrift://golden-02:9083', -- Required. The port need set on hive-site.xml 'hive_sync.jdbc_url' = 'jdbc://hive2://golden-02:10000', 'hive_sync.table'='t2', -- required, hive table name 'hive_sync.db'='hudi', 'hive_sync.username' = 'gujincheng', 'hive_sync.password' = '980071', 'hive_sync.support_timstamp' = 'true' ); --读取视图数据并写入hudi表 INSERT INTO t2_tmp SELECT uuid, name, age, ts, part FROM users_source_mysql ;
编写java实现flinkcdc入hudi
具体代码看githup,FlinkMysqlCDC2Hudi
这里遇到一个注意点,tenv.executeSql就是触发执行的操作,不需要再使用env.execute()再次触发一次
这里测试了一下,提交到standalone和提交到yarn上都是可以正常执行的。
hudi踩坑记录
- hadoop 环境不对
- 报
Caused by:java.lanq.NoClassDefFoundError:org/apache/hadoop/mapred/JobConf,具体信息如下:
问题原因:flink缺少hadoop相关依赖
解决办法:把hadoop-mapreduce相关jar放到flink lib下# 确保如下几个jar包放在了flink的lib文件夹下 -rw-r--r-- 1 wheel 787K 4 6 16:56 hadoop-mapreduce-client-common-3.2.2.jar -rw-r--r-- 1 wheel 1.6M 4 6 16:56 hadoop-mapreduce-client-core-3.2.2.jar -rw-r--r-- 1 wheel 84K 4 6 16:57 hadoop-mapreduce-client-jobclient-3.2.2.jar -rw-r--r-- 1 wheel 44M 4 7 15:10 hudi-flink-bundle_2.12-0.10.1.jar - 报
java.lang.NoClassDefFoundError: org/apache/thrift/TBase,具体报错如下:
这个问题找了很久,总是卡在flink同步元数据到hive。java.lang.NoClassDefFoundError: org/apache/thrift/TBase at java.lang.ClassLoader.defineClass1(Native Method) ~[?:1.8.0_162] at java.lang.ClassLoader.defineClass(ClassLoader.java:763) ~[?:1.8.0_162] ... at org.apache.hudi.hive.HiveSyncTool.<init>(HiveSyncTool.java:78) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.sink.utils.HiveSyncContext.hiveSyncTool(HiveSyncContext.java:51) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.sink.StreamWriteOperatorCoordinator.syncHive(StreamWriteOperatorCoordinator.java:302) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.sink.utils.NonThrownExecutor.lambda$execute$0(NonThrownExecutor.java:93) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_162] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_162] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_162] Caused by: java.lang.ClassNotFoundException: org.apache.thrift.TBase at java.net.URLClassLoader.findClass(URLClassLoader.java:381) ~[?:1.8.0_162] at java.lang.ClassLoader.loadClass(ClassLoader.java:424) ~[?:1.8.0_162] at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338) ~[?:1.8.0_162] at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ~[?:1.8.0_162] ... 19 more
想了一下原因,应该是flink在连接hms的时候,缺少依赖。这里在hudi源码里编译里好多次,怎么修改都不行,最后是把hive-exec的jar放到flink lib下-rw-r--r-- 1 wheel 44M 4 6 22:39 hive-exec-2.3.9.jar - 报
java.lang.NoClassDefFoundError:org/apache/hudi/org/apache/hadoop/hive/ql/metadata/Hive错误 ,具体报错如下:
问题原因:hudi对hive的代码进行了部分shade,这里在hudi的服务群里找到解决方案2022-04-06 22:59:12,854 ERROR org.apache.hudi.sink.StreamWriteOperatorCoordinator [] - Executor executes action [sync hive metadata for instant 20220406225911632] error java.lang.NoClassDefFoundError: org/apache/hudi/org/apache/hadoop/hive/ql/metadata/Hive at org.apache.hudi.hive.ddl.HMSDDLExecutor.<init>(HMSDDLExecutor.java:68) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.hive.HoodieHiveClient.<init>(HoodieHiveClient.java:76) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.hive.HiveSyncTool.<init>(HiveSyncTool.java:78) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.sink.utils.HiveSyncContext.hiveSyncTool(HiveSyncContext.java:51) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.sink.StreamWriteOperatorCoordinator.syncHive(StreamWriteOperatorCoordinator.java:302) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at org.apache.hudi.sink.utils.NonThrownExecutor.lambda$execute$0(NonThrownExecutor.java:93) ~[hudi-flink-bundle_2.12-0.10.1.jar:0.10.1] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_291] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_291] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_291] Caused by: java.lang.ClassNotFoundException: org.apache.hudi.org.apache.hadoop.hive.ql.metadata.Hive at java.net.URLClassLoader.findClass(URLClassLoader.java:382) ~[?:1.8.0_291] at java.lang.ClassLoader.loadClass(ClassLoader.java:418) ~[?:1.8.0_291] at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355) ~[?:1.8.0_291] at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ~[?:1.8.0_291] ... 9 more
解决办法:
参考master分支,修改packaging/hudi-flink-bundle/pom.xml,去掉hive相关的shade,把原本的<relocations>里的内容用master分支的替换掉,但是需要加上<relocation> <pattern>org.apache.parquet.</pattern> <shadedPattern>${flink.bundle.shade.prefix}org.apache.parquet.</shadedPattern> </relocation> - hive里能查到hudi的表结构,但是查不到hudi的数据
问题描述:
这里也想了很多办法,都找不到原因,最后,想了一下,hive在-- 查询不到数据 select * from hudi.t2_rt;select *的时候,不会执行mr,这时候扫描不到与表结构匹配的文件不会报错
这里想着让它执行一下mr程序,让它必须读取一下数据文件
这时候报如下错误:select count(1) from hudi.t2_rt;
问题原因:Diagnostic Messages for this Task: Error: java.lang.IndexOutOfBoundsException: Index: 1, Size: 1 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.get(ArrayList.java:433) at org.apache.hadoop.hive.ql.io.parquet.read.DataWritableReadSupport.getProjectedGroupFields(DataWritableReadSupport.java:116) at org.apache.hadoop.hive.ql.io.parquet.read.DataWritableReadSupport.getSchemaByName(DataWritableReadSupport.java:176) at org.apache.hadoop.hive.ql.io.parquet.read.DataWritableReadSupport.getRequestedSchemaForIndexAccess(DataWritableReadSupport.java:289) at org.apache.hadoop.hive.ql.io.parquet.read.DataWritableReadSupport.init(DataWritableReadSupport.java:231) at org.apache.hadoop.hive.ql.io.parquet.ParquetRecordReaderBase.getSplit(ParquetRecordReaderBase.java:84) at org.apache.hadoop.hive.ql.io.parquet.read.ParquetRecordReaderWrapper.<init>(ParquetRecordReaderWrapper.java:78) at org.apache.hadoop.hive.ql.io.parquet.read.ParquetRecordReaderWrapper.<init>(ParquetRecordReaderWrapper.java:63) at org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat.getRecordReader(MapredParquetInputFormat.java:75) at org.apache.hudi.hadoop.HoodieParquetInputFormat.getRecordReader(HoodieParquetInputFormat.java:224) at org.apache.hadoop.mapred.MapTask$TrackedRecordReader.<init>(MapTask.java:175) at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:444) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:349) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
hive.input.format 默认是org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,解析hudi表数据会存在问题
解决办法 - add jar /opt/cloudera/parcels/CDH/jars/hudi-hadoop-mr-bundle-0.11.0.jar;
- 需要设置
set hive.input.format= org.apache.hadoop.hive.ql.io.HiveInputFormat;或者设置set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
如果不设置,可以直接select * from hudi,但是count会数据翻倍
可以参考Hive On Hudi
hudi-0.11.0与flink整合
hudi-0.11.0与flink整合简单很多,只需要把以下jar包放到flink/lib下
-rw-r--r--. 1 root root 35787665 5月 6 13:51 hive-exec-2.1.1-cdh6.2.0.jar
-rw-r--r--. 1 root root 83405474 5月 10 17:38 hudi-flink1.13-bundle_2.12-0.11.0.jar
-rw-r--r--. 1 root root 38046857 5月 10 15:39 hudi-hadoop-mr-bundle-0.11.0.jar不需要再把hadoop-mapreduce-client*几个jar包放到lib下了
hudi与spark的整合
首先修改hudi源码,把pom文件夹下的spark.version改成3.1.1,然后重新编译hudi源码
nohup mvn clean install -DskipTests -Dmaven.test.skip=true -Dscala-2.12 -Dhadoop.version=3.0.0-cdh6.2.0 -Dspark3 -Pflink-bundle-shade-hive2 > nohup.log 2>&1 &这里加了-Dspark3
复制packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.12-0.10.1.jar
spark首先要与hive集成的,就是把hive-site.xml复制到spark/conf文件夹即可
spark-sql启动:
spark-sql --jars hudi-spark3.1.1-bundle_2.12-0.10.1.jarspark-sql查询hudi表:
use hudi;
select * from t2_rt;经过检验,spark-sql可以查询flink写入hudi的表
hudi与impala整合
hudi与impala整合需要注意亮点
- 需要升级impala3.4版本以上,3.4以前的版本不支持读取hudi。
- impala仅支持读取COPY_ON_WRITE类型的hudi表
- 每次使用impala查询hudi表之前,都需要refresh该表
--flinksql写数据进hudi
CREATE TABLE t2_1(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts timestamp(3),
part VARCHAR(20)
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs:///user/hive/warehouse/hudi.db/t2_1',
'table.type' = 'COPY_ON_WRITE', --注意是COPY_ON_WRITE
'hoodie.datasource.write.recordkey.field'= 'uuid',
'write.precombine.field'= 'ts',
'write.tasks' = '1',
'write.rate.limit' = '2000',
'compaction.tasks' = '1',
'compaction.async.enabled' = 'true',
'compaction.trigger.strategy' = 'num_commits',
'compaction.delta_commits' = '1',
'changleog.enabled' = 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable' = 'true', -- Required. To enable hive synchronization
'hive_sync.mode' = 'hms', -- Required. Setting hive sync mode to hms, default jdbc
'hive_sync.metastore.uris' = 'thrift://cxxxx:9083', -- Required. The port need set on hive-site.xml
'hive_sync.jdbc_url' = 'jdbc://hive2://cxxxx:10000',
'hive_sync.table'='t2_1', -- required, hive table name
'hive_sync.db'='hudi',
'hive_sync.username' = '',
'hive_sync.password' = '',
'hive_sync.support_timstamp' = 'true'
);
INSERT INTO t2_1 SELECT uuid, name, age, ts, part FROM users_source_mysql ;
-- 在impala中查询hudi表
INVALIDATE METADATA hudi.t2_1;
REFRESH hudi.t2_1;
select * from hudi.t2_1;
Iceberg介绍
存储
Iceberg支持使用Hadoop FileSystem API与湖存储交互,Iceberg需要文件系统支持写、读、删除操作,比如S3。Iceberg不需要随机写,一旦写入,数据文件和元数据文件在被删除之前是不可变的。
文件格式
Iceberg是围绕数据文件和元数据文件的概念设计的,数据文件格式支持parquet, avro, orc,数据文件可以设置大小,减少数据文件重写成本,元数据文件格式支持Json
表格式
Iceerg支持创建表、删除表、修改表名、修改表属性、添加列、修改列名、修改列大小、修改列的顺序、删除列等操作。Iceberg的schema更新是元数据修改,数据文件不需要重写。
Iceberg分区每次都正确地生成分区值,并总是在可能的情况下用于加速查询。最重要的是,查询不再依赖于表的物理布局。通过物理和逻辑之间的分离,Iceberg表可以随着数据量的变化而发展分区方案。分区修改是一个元数据操作且不需要重写文件。
Iceberg排序顺序也可以在现有表中更新,在修改排序顺序时,使用较早顺序写入的旧数据将保持不变,引擎总是可以选择以最新的排序顺序。
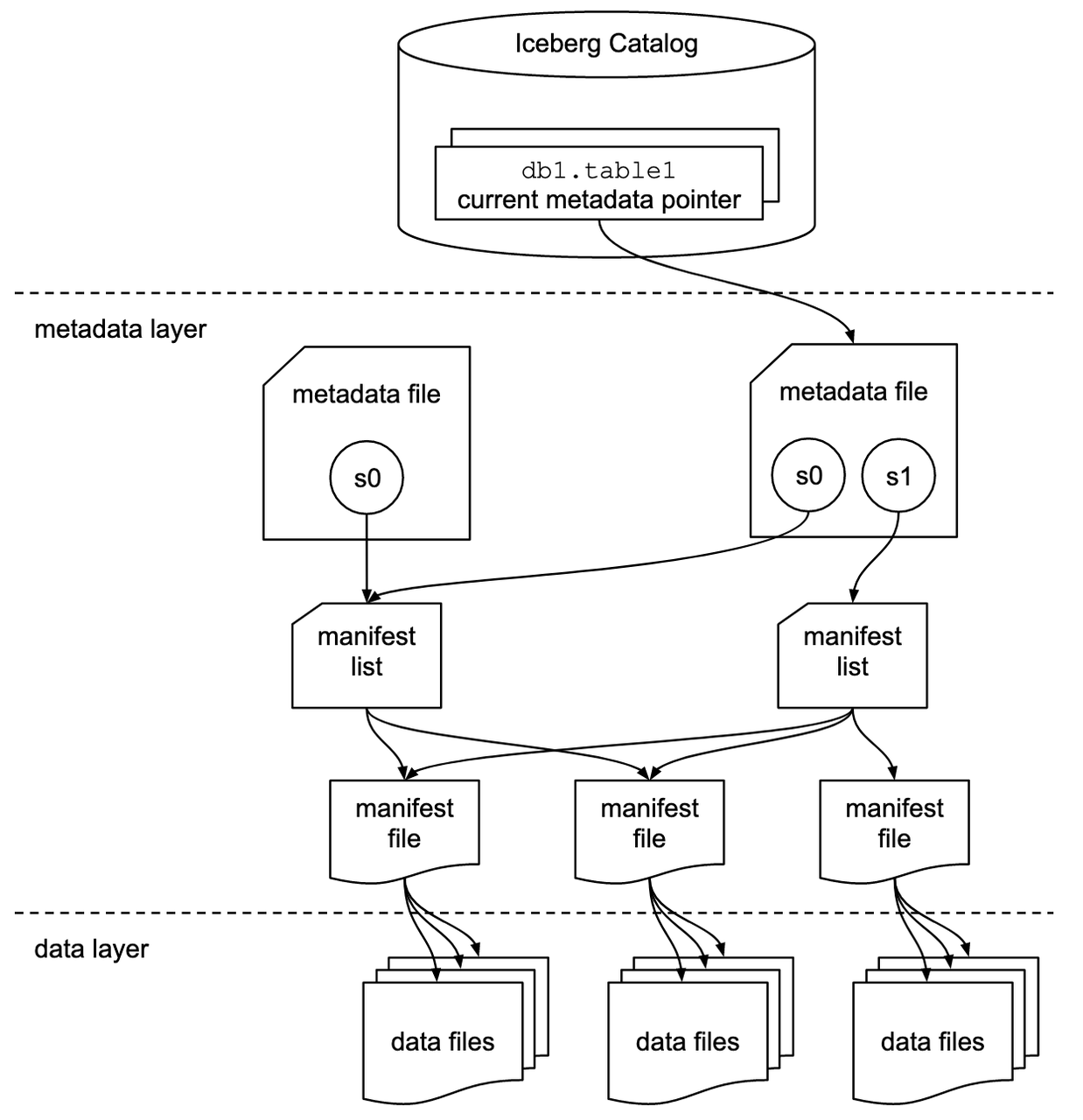
快照文件列出清单列表文件。清单列表文件列出组成表快照的清单文件,以及每个分区的范围。清单文件列出组成表快照的数据文件,以及数据文件分区数据和列级别统计信息。Iceberg首先使用清单列表文件分区的范围,然后使用清单文件获取数据文件。通过这种模式,清单列表文件作为清单文件的索引,不需要扫描所有的清单文件。
并发控制
一个表的元数据文件与另一个元数据文件的原子交换为可序列化隔离提供了基础。读取器在加载表元数据时使用当前的快照,并且在刷新元数据位置之前不会受到更改的影响。写入器乐观地创建表元数据文件,假设当前版本不会在写入器提交之前更改,一旦写入器创建了更新,它就通过将表的元数据文件指针从基本版本交换到新版本来提交。
写入器
批量写入:
- insert into:向表中添加新数据
- merge into:实现行级更新,包含更新行的数据文件会被重写
- insert overwrite,分区数据文件会被重写
流式写入:Iceberg支持append和complete输出模式 - append:将每个少量的批处理的行追加到表中
- complete:每个少量的批处理替换表内容
Iceberg对分区表进行写操作之前,需要对每个任务的数据按照分区进行排序。对于批处理,鼓励执行显示排序来满足需求,但是这种方法会带来额外的延迟,因为排序被认为是流工作负载的繁重操作。为了避免额外的延迟,可以启用fanout写入器来消除这个需求
流式写入会快速创建新的表版本,从而创建大量的表元数据来跟踪这些版本。建议通过调优提交速率、过期旧快照和自动清理元数据文件来维护元数据
读取器
Iceberg查询不需要指定分区值查询,支持快照查询,支持表历史元数据、快照元数据、文件元数据、清单元数据查询
Iceber查询扫描计划会根据快照文件、清单列表文件、清单文件找出查询需要的数据文件,扫描计划能够在单节点上运行,因此任何一个客户端都可以低延迟的查询
Iceberg支持hive表,元数据保存在Iceberg中,支持hive查询,支持presto使用Iceberg链接起查询
表服务
- 过期快照:Iceberg每次写入会产生一个新的快照,快照可以被用来做时间快照查询,或者回滚,快照会聚集直到过期快照动作执行,推荐定期执行过期快照来删除不再需要数据文件,来保持较小的表元数据
- 删除旧的元数据文件:Iceberg使用Json文件跟踪表元数据,对表的每次更改都会生成一个新的元数据文件,以提供原子性,默认情况下,将保留旧的元数据文件作为历史记录。经常提交的表,比如流式任务,需要定期地清除元数据文件。
- 删除孤儿文件:在Spark或者其他分布式处理引擎中,任务或作业失败可能会留下不被表元数据引用的文件,而且在某些情况下,正常快照过期可能无法确定某个文件不再需要并删除它
- 压缩数据文件:Iceberg在一个表中跟踪每个数据文件,更多的数据文件导致清单文件中存储更多的元数据,而小的数据文件导致不必要的元数据量和文件打开成本的低效率查询,Iceberg可以并行压缩数据文件,这将把小文件合并成大文件,以减少元数据开销和运行时文件打开成本。
- 重写清单文件:Iceberg使用清单列表文件和清单文件元数据加快查询计划,并过滤不必要的数据文件,当表写的模式和查询模式不一致,元数据可以被重写。
iceberg测试案例
iceberg与hive整合
这个比较简单,首先到官网下载iceberg-hive-runtime-0.13.1.jar
在hive-cli执行如下命令:
add jar /Users/gujincheng/Downloads/iceberg-hive-runtime-0.13.1.jar;
SET iceberg.engine.hive.enabled=true;
CREATE EXTERNAL TABLE test.iceberg_hive(
`id` int,
`name` string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://golden-02:9000/user/hive/warehouse/test/iceberg_hive';
INSERT INTO test.iceberg_hive values(2, 'b');
select * from test.iceberg_hive;这里测试了一下,iceberg与hive整合,不支持行级别更新,
iceberg在spark3.x 里支持行级别更新
在flink中支持行级别更新,需要指定主键,如果是分区表,改主键必须得包含分区字段,只支持insert into
insert overwrite 只支持批写入,流式写入不支持
这里因为技术选型最终选择了hudi,我们就不进一步测试了,具体的可以参考网上的博客
Iceberg +Flink+CDH+Trino+Hive
写的很详细
Hudi和Iceberg特性对比
- ACID和隔离级别
| Iceberg | Hudi | |
|---|---|---|
| ACID | 支持 | 支持 |
| 隔离级别 | 多个写必须严格串行化,读和写可以同时跑 | 多个写的数据无交集,可以并发执行,读和写可以同时跑 |
| 并发多写 | 支持 | 支持 |
| 时间快照查询 | 支持 | 支持 |
- 表格式
| Iceberg | Hudi | |
|---|---|---|
| 支持schema变更 | 支持,添加字段、删除字段、修改字段名称、修改字段长度 | 支持,添加、删除 |
| 文件格式 | Parquet, ORC | Parquet, Avro |
- 流批接口支持
| Iceberg | Hudi | |
|---|---|---|
| 批量读 | 支持(spark、Hive、presto) | 支持(spark、Hive、presto) |
| 批量写 | 支持(spark) | 支持(spark) |
| 流式读 | 开发中 | 支持 |
| 流式写 | 支持 | 支持 |
| Upserts/Delete/Merge/Update | 不支持 | 支持 |
- 查询性能
| Iceberg | Hudi | |
|---|---|---|
| 查询不需要指定分区 | 支持 | 不支持 |
| 元数据花费 | 低 | 低 |
| 分区内索引 | 支持 | 不支持 |
| CopyOnWrite | 支持 | 支持 |
| MergeOnRead | 开发中 | 支持 |
| 自动压缩 | 不支持(需手动调用压缩方法) | 支持 |
| 自动清除 | 不支持(需手动调用清除方法) | 支持 |
- 社区现状
| Iceberg | Hudi | |
|---|---|---|
| 开源时间 | 2018.11.6 | 2019.1.17 |
| Github watch | 118 | 1.2k |
| Github star | 1.9k | 2.2k |
| Github fork | 710 | 979 |
| Github Issue | 477 | 73 |
| Github pull request | 161 | 119 |
| Commits | 1822 | 1864 |
| Contributors | 167 | 193 |
Hudi和Iceberg性能对比
生产环境100万数据量对比(Hudi推hive,Iceberg是hive表)
| 初始化插入100万 | 新增插入10万条 | 插入20万条、更新10万条、删除10万条 | ||||
|---|---|---|---|---|---|---|
| 无分区表 | 有分区表 | 无分区表 | 有分区表 | 无分区表 | 有分区表 | |
| Iceberg插入耗时 | 7503 | 9295 | 10787 | 7983 | 14065 | 9648 |
| Iceberg查询总数耗时_spark | 2952 | 5970 | 2962 | 6170 | 2906 | 6232 |
| iceberg查询单条耗时_spark | 1019 | 852 | 1430 | 810 | 1007 | 831 |
| Iceberg查询总数耗时_hive | 10137 | 10581 | 13729 | 8753 | 9950 | 7553 |
| Iceberg查询单条耗时_hive | 934 | 239 | 183 | 160 | 170 | 168 |
| Iceberg查询总数耗时_presto | 生产上trino中的iceberg版本很低,查询报错,侧重hudi,所以跳过此测试 | |||||
| Iceberg查询单条耗时_presto | ||||||
| Hudi插入耗时 | 60255 | 59835 | 21868 | 29383 | 155586(96611+155586) | 172115(69477+102638) |
| Hudi查询创建视图耗时_spark | 3539 | 5213 | 3283 | 5606 | 3169 | 4803 |
| Hudi查询总数耗时_spark | 2660 | 2437 | 3639 | 2003 | 5234 | 3978 |
| Hudi查询单条耗时_spark | 4665 | 910 | 1048 | 2758 | 2323 | 2125 |
| Hudi查询总数耗时_hive | 11933 | 6569 | 6390 | 10721 | 5129 | 12573 |
| Hudi查询单条耗时_hive | 185 | 129 | 201 | 216 | 104 | 150 |
| Hudi查询总数耗时_presto | 毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 |
| Hudi查询单条耗时_presto | 毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 |
Hudi和Iceberg总结
Hudi的最大的特色就是upsert和delete,upsert和delete写入增量文件,一定时间后可以将增量文件合并到基本文件中,通过这种方式可以实现行更新和流式写。
Iceberge的最大特色就是查询,通过快照、清单文件列表、清单实现快速过滤,Iceberg通过merge into也可以实现行更新,Iceberg也提供了流式写的接口,但是无论是行更新和流式写都是需要更新行的数据文件,并产生一个快照,这会大大增加元数据量。Iceberge的merge into也有诸多限制,原表和更新表join要有交集,否则会失败;Iceberg的更新表不能出现既更新也删除的同一条记录,否则会失败。
虽然在性能对比章节,Iceberg性能比Hudi好很多,但是从原理上分析,Hudi耗时高是有原因的,并且带来的是较少的IO,在Hudi更新时会根据主键合并更新数据,比如一条记录先新增后删除,合并后只留下删除的记录,然后根据主键定位到记录所在的分片,如果没有找到则插入记录,如果找到则添加到增量文件中,如果使用Hbase索引,相信性能会好一些。
Iceberg耗时低从原理来看,Iceberg只是将两个表join,然后原表修改的数据所在的数据文件会被重写,这种方式会在某些场景下导致大量的IO和内存消耗,在流式写测场景下支持时间旅行会产生很多文件。Iceberg的行删除目前在开发中。
个人觉得Hudi更适合作为采集系统的数据湖组件。Hudi最大的特色upsert和delete就已经是很大的亮点,这个功能和Kudu很相似。此外,目前Hudi功能已经完善,社区反馈的问题也比较少,已经在很多大厂应用,社区比较活跃。Iceberg很多功能还在开发中,社区反馈的问题比较多。