本文主要包括:
- Hbase简介
- Hbase安装
- HBase命令行操作
- Phoenix操作Hbase
Hbase简介
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
Hbase的表模型与关系型数据库的表模型不同:
- Hbase的表没有固定的字段定义;
- Hbase的表中每行存储的都是一些key-value对
- Hbase的表中有列族的划分,用户可以指定将哪些kv插入哪个列族
- Hbase的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中
- Hbase的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复
- Hbase中的数据,包含行键,包含key,包含value,都是byte[ ]类型,hbase不负责为用户维护数据类型
- HBASE对事务的支持很差
HBASE相比于其他nosql数据库(mongodb、redis、cassendra、hazelcast)的特点:
Hbase的表数据存储在HDFS文件系统中,所以,hbase具备如下特性:
- 海量存储
- 列式存储
- 数据存储的安全性可靠性极高!
- 支持高并发
- 存储容量可以线性扩展;
HBase存储机制
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase: - 表是行的集合。 - 行是列族的集合。 - 列族是列的集合。 - 列是键值对的集合。
下面给出的表中是HBase模式的一个例子。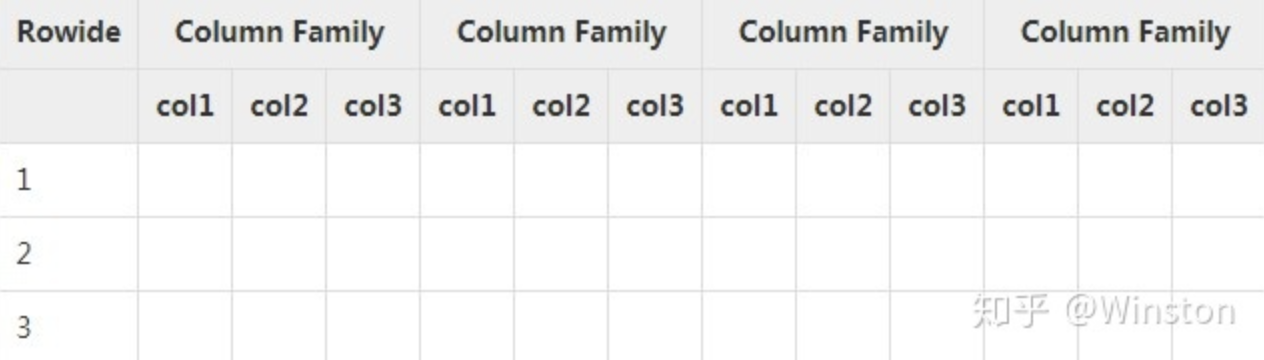
名词概念
Rowkey的概念
Rowkey的概念和mysql中的主键是完全一样的,Hbase使用Rowkey来唯一的区分某一行的数据。Hbase只支持3种查询方式: - 1、基于Rowkey的单行查询 - 2、基于Rowkey的范围扫描 - 3、全表扫描
因此,Rowkey对Hbase的性能影响非常大,Rowkey的设计就显得尤为的重要。设计的时候要兼顾基于Rowkey的单行查询也要键入Rowkey的范围扫描。
rowkey 行键可以是任意字符串(最大长度是64KB,实际应用中长度一般为 10-100bytes),最好是16。在HBase 内部,rowkey 保存为字节数组。HBase会对表中的数据按照 rowkey 排序 (字典顺序)Column的概念
列,可理解成MySQL列。ColumnFamily的概念
Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。列族是由一个一个的列组成(任意多)。
Hbase表的创建的时候就必须指定列族。就像关系型数据库创建的时候必须指定具体的列是一样的。
Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。我们使用的场景一般是1个列族。
TimeStamp的概念
TimeStamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不通版本的数据。
在写入数据的时候,如果用户没有指定相应的timestamp,HBase会自动添加一个timestamp,timestamp和服务器时间保持一致。
HBase 中通过rowkey和columns确定的为一个存储单元称为cell。每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是64位整型。时间戳可以由 hbase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理(包括存贮和索引)负担,hbase 提供了两种数据版本回收方式: - 保存数据的最后 n 个版本 - 保存最近一段时间内的版本(设置数据的生命周期 TTL)。
用户可以针对每个列簇进行设置。单元格(Cell)
由{rowkey, column( = +),version}唯一确定的单元。 Cell 中的数据是没有类型的,全部是字节码形式存贮。Region
Region的概念和关系型数据库的分区或者分片差不多。
Hbase会将一个大表的数据基于Rowkey的不同范围分配到不通的Region中,每个Region负责一定范围的数据访问和存储。这样即使是一张巨大的表,由于被切割到不通的region,访问起来的时延也很低。
Hbase安装
此处略过,具体可以参考[][]
HBase命令行操作
| 名称 | 命令表达式 |
|---|---|
| 创建表 | create ‘表名’, ‘列族名1’,’列族名2’,’列族名N’ |
| 查看所有表 | list |
| 描述表 | describe ‘表名’ |
| 判断表存在 | exists ‘表名’ |
| 判断是否禁用启用表 | is_enabled ‘表名’is_disabled ‘表名’ |
| 添加记录 | put ‘表名’, ‘rowKey’, ‘列族 : 列‘ , ‘值’ |
| 查看记录rowkey下的所有数据 | get ‘表名’ , ‘rowKey’ |
| 查看表中的记录总数 | count ‘表名’ |
| 获取某个列族 | get ‘表名’,’rowkey’,’列族’ |
| 获取某个列族的某个列 | get ‘表名’,’rowkey’,’列族:列’ |
| 删除记录 | delete ‘表名’ ,‘行名’ , ‘列族:列’ |
| 删除整行 | deleteall ‘表名’,’rowkey’ |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除第一步 disable ‘表名’ ,第二步 drop ‘表名’ |
| 清空表 | truncate ‘表名’ |
| 查看所有记录 | scan “表名” |
| 查看某个表某个列中所有数据 | scan “表名” , {COLUMNS=>’列族名:列名’} |
| 更新记录 | 就是重写一遍,进行覆盖,hbase没有修改,都是追加 |
hbase 更新一列数据
原始数据:
hbase(main):005:0> get 'IRW_OD','4620160759245174311780535580595841689669732958'
COLUMN CELL
info:collectedTime timestamp=1689669733091, value=2023-07-18 16:42:10
info:deviceId timestamp=1689669733091, value=462016075924517431
info:eid timestamp=1689669733091, value=178053558059584
info:model timestamp=1689669733091, value={"DataContent":{"IRW_index":"\xE8\xA8\x82\xE5\x96\xAE\xE5\xAF\xA9\xE6\xA0\xB8\xE5\xA4\xA9\xE6\x95\xB8","IRW_
YYYYMM":"202201","IRW_data":0,"IRW_ID":"a2XX"},"BasicInfo":{"deviceId":"462016075924517431","eid":"178053558059584","collectedTime":"2023-0
7-18 16:42:10","collectConfigId":"609666927010368","uploadDataModelCode":"IRW_OD","deviceCollectDetailId":"609889430315584"}}
info:rowKey timestamp=1689669733091, value=4620160759245174311780535580595841689669732958
1 row(s)现在要把info:eid修改一下数值
put 'your_table_name', 'your_row_key', 'your_column_family:your_column_qualifier', 'your_new_value'
真实的语句:
put 'IRW_OD','417660679831438902430738667280001689736759541','info:eid','526095658639936'Phoenix操作Hbase
Phoenix安装与配置
新公司使用的CM来统一管理大数据集群,为了防止软件版本不统一导致各种问题,这里在CM上安装Phoenix
首先,需要确定CM平台是哪个版本的,在CM的管理页面上可以直接看出,我们的CM的6.2.0版本的
那么剩下的,就是要下载一个和6.2.0版本想匹配的phoenix安装包
但是,CM从2021.1月份开始收费,通过正常渠道无法下载到这个安装包了。这里是在百度上找了很久才找到
具体参考CDH 6.2 安装 Phoenix
安装包已经搞定,下面开始安装
首先安装 CSD 文件
- 确定 CSD(Custom Service Descriptor) 文件安装路径,公司的安装路径为/opt/cloudera/csd,这里的地址就是server的地址,即ddp1服务器的地址
- 将 CSD文件(PHOENIX-1.0.jar) 放到到本地描述符存储库路径,然后重启 Cloudera Manager 服务器
- 重启 cloudera-scm-server 服务
systemctl restart cloudera-scm-server这里如果cloudera-scm-server 服务不重启,虽然phoenix安装上去了也能正常使用,但是,在主页面添加不了服务,监控不了该组件
安装Phoenix parcel
- 上传文件到
/opt/cloudera/parcel-repo目录下,PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel、PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha 、 manifest.json - 点击检查新 Parcel ,当出现 PHOENIX 后,点击 Distribute
- 点击激活 PHOENIX,并在弹框中点击 确认
- 集群 -> 操作 -> 添加服务,出现 PHOENIX 服务
- 将 PHOENIX 服务添加到每个 Region Server 中
- 重启hbase集群,否则phoenix启动会报错
- 上传文件到
遇到的问题
Phoenix安装完成以后,在服务里找不到选项,添加不了服务,原因是CSD文件配置好以后,CM没有重启
添加完成phoenix服务以后,监控不了,CM页面提示如下告警信息
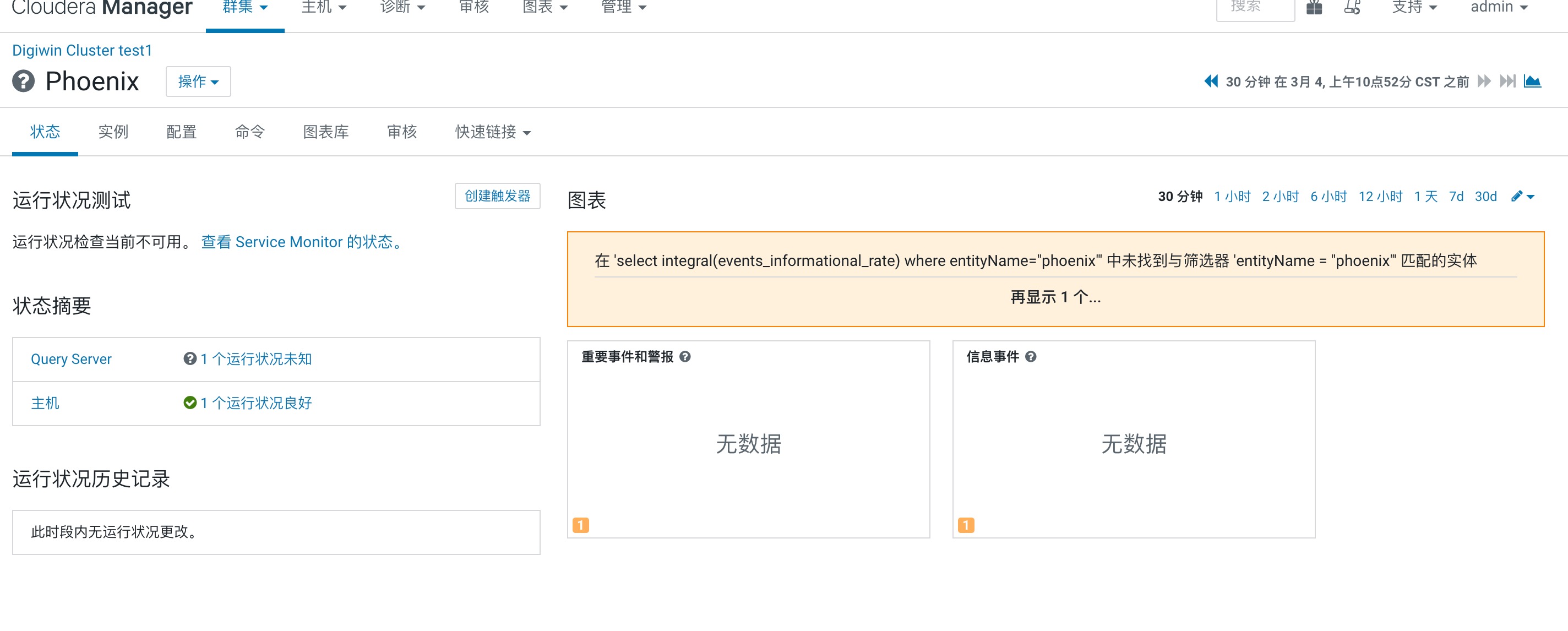
在CM界面点击Cloudera Management Service重启后解决Phoenix安装完成以后,直接打开phoenix-sqlline,报如下错误
Error: org.apache.hadoop.hbase.DoNotRetryIOException: Unable to load configured region split policy 'org.apache.phoenix.schema.MetaDataSplitPolicy' for table 'SYSTEM.CATALOG' Set hbase.table.sanity.checks to false at conf or table descriptor if you want to bypass sanity checks at org.apache.hadoop.hbase.master.HMaster.warnOrThrowExceptionForFailure(HMaster.java:2232) at org.apache.hadoop.hbase.master.HMaster.sanityCheckTableDescriptor(HMaster.java:2079) at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1978) at org.apache.hadoop.hbase.master.MasterRpcServices.createTable(MasterRpcServices.java:630) at org.apache.hadoop.hbase.shaded.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413) at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304) (state=08000,code=101)网上的说法是,需要把phoenix的jar包放到hbase的安装路径之下,但是,那应该是自己解压phoenix安装的问题,使用CM安装,CM会把这些配置都设置好的,只需要重启一下Hbase集群即可
phoenix里查不到hbase的表
- 这里不算是问题,phoenix创建的表hbase能看到,但是,hbase的表想要在phoenix里看到,需要做一次映射
phoenix映射HBase
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的。
如果要在phoenix中操作由hbase创建的表,则需要在phoenix中进行表的映射。
映射方式有两种:
视图映射和表映射
两种方式的区别:
- 视图只读,不支持新增和修改
- 如果删除视图,源数据不会发生改变
- 视图的查询效率较低(原因是:表映射会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率,而视图映射没有)
- 使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。
案例:
首先在Hbase中创建一个表,并写入几条数据
create 'phoenix','info'
put 'phoenix', 'row001','info:name','phoenix'
put 'phoenix', 'row002','info:name','hbase'- 创建视图:
create view "phoenix"(empid varchar primary key,"info"."name" varchar); - *注意:**
- 这里一定要注意的是表名和列族以及列名需要用双引号括起来,因为HBase是区分大小写的,如果不用双引号括起来的话Phoenix在创建表的时候会自动将小写转换为大写字母,这样HBase中会创建另外一张表PHOENIX。
- 这里查询表名需要用双引号括起来,强制不转换为大写。

视图是只读的,不可以修改hbase表的内容
- 创建关联表:
直接这么创建,从hbase端修改的数据,在phoenix里是查不到的。create table "phoenix"(empid varchar primary key,"info"."name" varchar);
经过阅读官方文档发现,phoenix 4.10 版本后,对列映射做了优化,采用一套新的机制,不在基于列名方式映射到 hbase。
如果只是想查询hbase数据,那么可以使用创建视图的方式,但是如果必须要映射到表,需要禁用列映射规则(会降低查询性能)create table "phoenix"(empid varchar primary key,"info"."name" varchar) column_encoded_bytes=0;
还有一个问题:
通过phoenix创建的表,在phoenix侧修改数据后,hbase里的数据是两条
不知道这种数据会不会是脏数据
JDBC链接Phoenix
添加Maven依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0</version>
</dependency>java代码:
因为jdbc调用UDF失败,需要把hbase-site.xml加入到resource文件夹下再打包
package com.digiwin.escloud.phoenix;
import org.apache.hadoop.conf.Configuration;
import org.apache.phoenix.jdbc.PhoenixDriver;
import java.sql.*;
import java.util.Properties;
public class PhoenixTest {
private static String driver = "org.apache.phoenix.jdbc.PhoenixDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Statement stmt = null;
ResultSet rs = null;
Connection con = DriverManager.getConnection("jdbc:phoenix:ddp5.hadoop:2181");
stmt = con.createStatement();
String sql = "select * from \"phoenix\"";
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.print("rowkey:"+rs.getString("ROWKEY"));
System.out.println(",name:"+rs.getString("name"));
}
String s1 = "select CRC32('aaa') as aaa from \"phoenix\"";
rs = stmt.executeQuery(s1);
while (rs.next()) {
System.out.println(rs.getString(1));
System.out.print("AAA:"+rs.getString("AAA"));
}
stmt.close();
con.close();
}
}
遇到的问题
- java.lang.ClassNotFoundException: org.apache.phoenix.jdbc.PhoenixDriver
问题原因: maven工程打包不正确,应该把依赖也打到jar包里
解决办法:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<!-- get all project dependencies -->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<!-- bind to the packaging phase -->
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>- 报找不到方法,具体报错信息
解决办法:添加maven依赖Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.security.authentication.util.KerberosUtil.hasKerberosKeyTab(Ljavax/security/auth/Subject;)Z at org.apache.hadoop.security.UserGroupInformation.<init>(UserGroupInformation.java:715) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:925) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:873) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:740) at org.apache.hadoop.hbase.security.User$SecureHadoopUser.<init>(User.java:266) at org.apache.hadoop.hbase.security.User.getCurrent(User.java:164) at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver$ConnectionInfo.<init>(PhoenixEmbeddedDriver.java:504) at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver$ConnectionInfo.create(PhoenixEmbeddedDriver.java:312) at org.apache.phoenix.jdbc.PhoenixDriver.getConnectionQueryServices(PhoenixDriver.java:232) at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver.createConnection(PhoenixEmbeddedDriver.java:150) at org.apache.phoenix.jdbc.PhoenixDriver.connect(PhoenixDriver.java:221) at java.sql.DriverManager.getConnection(DriverManager.java:664) at java.sql.DriverManager.getConnection(DriverManager.java:270) at com.digiwin.escloud.phoenix.Phoenix.main(Phoenix.java:18)<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> - 开启
phoenix.schema.isNamespaceMappingEnabled=true之后,再用jdbc方式连接phoenix报如下错误: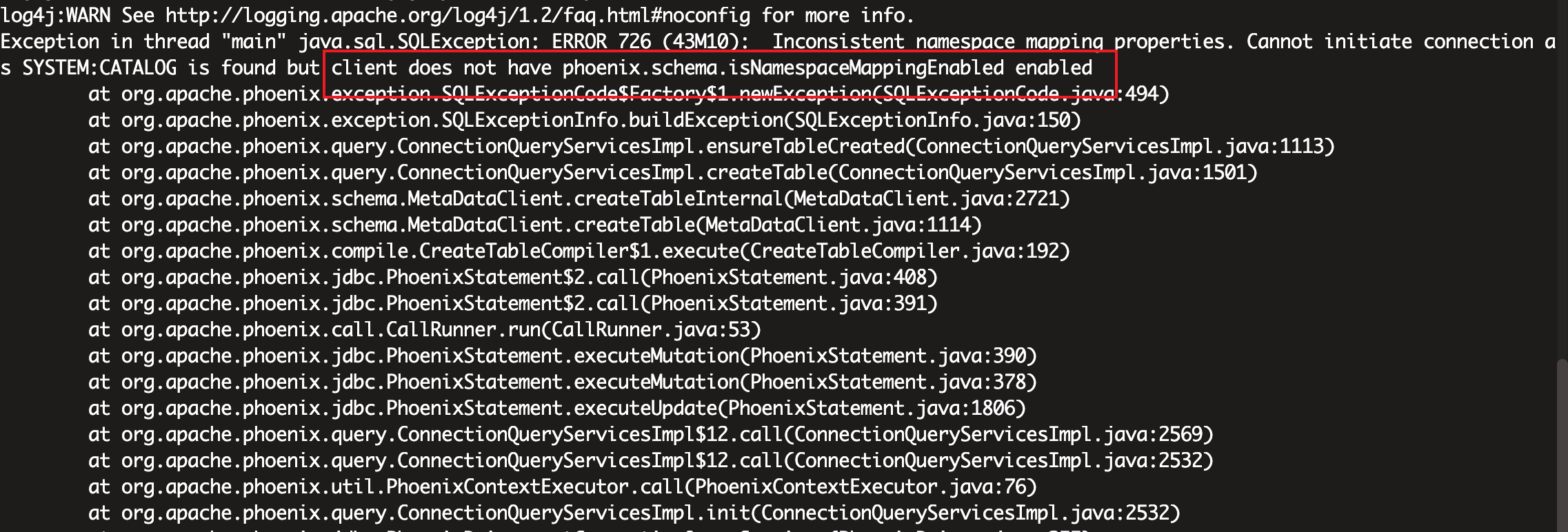
原因:
开启这个配置以后,sqlline的方式可以默认映射过去,但是jdbc方式需要再手动指定一下
解决办法:// 再代码里加配置条件 Properties properties = new Properties(); properties.put("phoenix.schema.isNamespaceMappingEnabled","true"); Connection con = DriverManager.getConnection("jdbc:phoenix:ddp5.hadoop:2181",properties);利用Phoenix创建hbase的二级索引
配置:
安装完 Phoenix 后,需要做一些必要配置才能使用 Phoenix,CDH HBase 配置界面配置如下两处: - hbase-site.xml 的 HBase 服务高级配置代码段(安全阀)
- hbase-site.xml 的 HBase 客户端高级配置代码段(安全阀)
添加如下参数配置:
然后,按照提示重启HBase服务并重新部署客户端配置即可。<!-- 二级索引支持 --> <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property>
创建二级索引:
create index phoneix_index on "phoenix" ("info"."name");需要注意的是: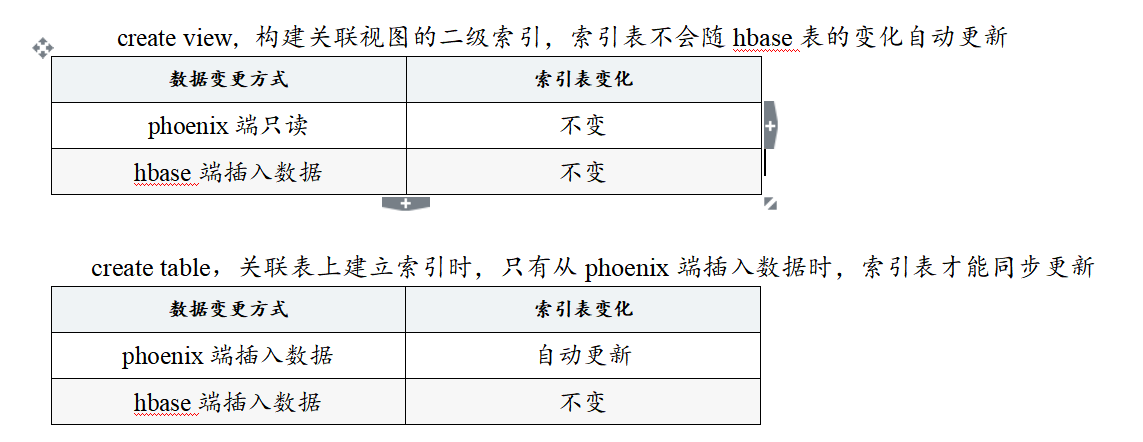
所以如果想用hbase的二级索引,只能从phoenix中插入数据
允许Phoenix创建namespace
CDH HBase 配置界面配置如下两处:
- hbase-site.xml 的 HBase 服务高级配置代码段(安全阀)
- hbase-site.xml 的 HBase 客户端高级配置代码段(安全阀)
注意:<!-- 命名空间映射开启,Phoenix4.8.0开始支持 --> <property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property> <property> <name>phoenix.schema.mapSystemTablesToNamespace</name> <value>true</value> </property>
开启了命名空间以后,通过jdbc方式连接phoenix,需要在代码里配置一下这个参数:
如果不添加如上配置,会报如下错误:// 再代码里加配置条件 Properties properties = new Properties(); properties.put("phoenix.schema.isNamespaceMappingEnabled","true"); Connection con = DriverManager.getConnection("jdbc:phoenix:ddp5.hadoop:2181",properties);
Phoenix允许自定义UDF
CDH HBase 配置界面配置如下两处:
- hbase-site.xml 的 HBase 服务高级配置代码段(安全阀)
- hbase-site.xml 的 HBase 客户端高级配置代码段(安全阀)
下面写一个UDF来实现CRC32加密功能:<!-- 启用用户自定义函数(UDF) --> <property> <name>phoenix.functions.allowUserDefinedFunctions</name> <value>true</value> <description>enable UDF functions</description> </property> <!-- 自定义函数,存储jar的hdfs目录 --> <property> <name>hbase.dynamic.jars.dir</name> <value>/hbase/lib/udf</value> </property>
添加maven配置
<dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-core</artifactId> <version>5.0.0-HBase-2.0</version> </dependency>编写java代码:
package com.digiwin.escloud.phoenix; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.util.Bytes; import org.apache.phoenix.expression.Expression; import org.apache.phoenix.expression.function.ScalarFunction; import org.apache.phoenix.parse.FunctionParseNode; import org.apache.phoenix.schema.tuple.Tuple; import org.apache.phoenix.schema.types.PDataType; import org.apache.phoenix.schema.types.PVarchar; import java.sql.SQLException; import java.util.List; import java.util.zip.CRC32; @FunctionParseNode.BuiltInFunction( name = CRC32Function.NAME, args = {@FunctionParseNode.Argument()} ) public class CRC32Function extends ScalarFunction { public static final String NAME = "CRC32"; public static final Integer LENGTH = 19; public CRC32Function() throws SQLException { } public CRC32Function(List<Expression> children) throws SQLException { super(children); } public static void main(String[] args) { CRC32 crc32 = new CRC32(); crc32.update("lake".getBytes()); System.out.println(crc32.getValue()); } @Override public boolean evaluate(Tuple tuple, ImmutableBytesWritable ptr) { if (!getChildExpression().evaluate(tuple, ptr)) { return false; } if (ptr.getLength() == 0) { return true; } CRC32 crc32 = new CRC32(); crc32.update(ptr.get(), ptr.getOffset(), ptr.getLength()); ptr.set(Bytes.toBytes(String.valueOf(crc32.getValue()))); return true; } @Override public PDataType getDataType() { return PVarchar.INSTANCE; } @Override public Integer getMaxLength() { return LENGTH; } @Override public boolean isNullable() { return getChildExpression().isNullable(); } @Override public String getName() { return NAME; } private Expression getChildExpression() { return children.get(0); } }上传jar包到hdfs
hadoop fs -put CalculationRealtime-1.0-SNAPSHOT-jar-with-dependencies.jar /hbase/lib/udf在sqlline创建udf
create function CRC32(varchar) returns varchar as 'com.digiwin.escloud.phoenix.CRC32Function' using jar '/hbase/lib/udf/CalculationRealtime-1.0-SNAPSHOT-jar-with-dependencies.jar'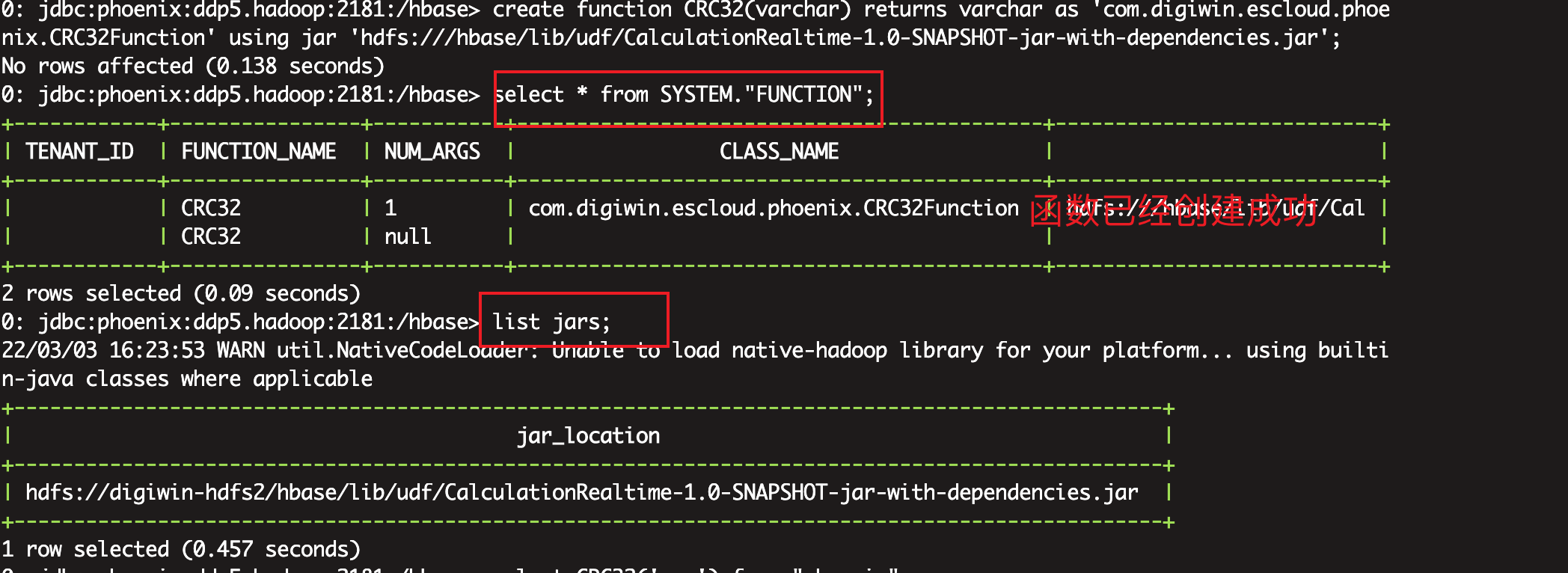
注意:
这里的路径因为公司hadoop集群配置了hdfs的开头,所以不要以hdfs:///开头使用udf
select CRC32('aaa') from "phoenix";
通过JDBC使用自定义UDF
如果是JDBC中使用到了UDF函数,需要在hbase-site.xml中添加参数
<property>
<name>hbase.local.dir</name>
<value>/tmp/hbase-hbase/local/</value>
<description>UDF 本地文件系统路径</description>
</property>这里虽然在CM上客户端和服务端都设置了上面的参数,但是,还是报如下错误:
这里不知道为啥,我把配置到hbase-site.xml的参数都通过Properties的方式加到代码里了,但是不生效
解决办法:
在代码里的resource文件夹添加hbase-site.xml,重新打包,就可以了
解决通过Flink调用phoenix jdbc创建schema失败
原始pom文件
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>${phoenix-spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>java代码:
package com.digiwin.flink.cdc2kafka;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Properties;
public class FlinkPhoenixTest2 {
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "ddp3.hadoop:9092,ddp4.hadoop:9092,ddp5.hadoop:9092");
properties.setProperty("group.id", "fink-test");
properties.setProperty("auto.offset.reset","earliest");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
String inputTopic = "gjc_test";
// Source
FlinkKafkaConsumer<String> consumer =
new FlinkKafkaConsumer<String>(inputTopic, new MyKafkaDeserializationSchema(), properties);
SingleOutputStreamOperator<Tuple2<String, Long>> aaa = env.addSource(consumer).flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] arr = s.split(",");
for (String str : arr) {
collector.collect(new Tuple2<>(str, 1L));
}
}
})
.keyBy(x -> x.f0)
.process(new KeyedProcessFunction<String, Tuple2<String, Long>, Tuple2<String, Long>>() {
String phoenixServer = "jdbc:phoenix:ddp5.hadoop:2181";
@Override
public void open(Configuration parameters) throws Exception {
if (phoenixServer == null) {
throw new RuntimeException("Config of phoenix server is null");
}
Class.forName(PHOENIX_DRIVER);
Properties props = new Properties();
props.put("phoenix.schema.isNamespaceMappingEnabled","true");
Connection connection = DriverManager.getConnection(phoenixServer, props);
connection.setAutoCommit(true);
String sql1 = "create schema IF NOT EXISTS \"aaa\"";
System.out.println("-----sql1"+sql1);
boolean execute = execute(connection, sql1);
System.out.println("-----execute1"+execute);
}
@Override
public void processElement(Tuple2<String, Long> value, KeyedProcessFunction<String, Tuple2<String, Long>, Tuple2<String, Long>>.Context ctx, Collector<Tuple2<String, Long>> out) throws Exception {
out.collect(value);
}
});
aaa.print();
env.execute();
}
private static boolean execute(Connection connection, String sql) throws Exception {
PreparedStatement preparedStatement = null;
try {
preparedStatement = connection.prepareStatement(sql);
boolean execute = preparedStatement.execute();
return execute;
} catch (Exception e) {
e.printStackTrace();
throw e;
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}报错如下:
Caused by: org.apache.phoenix.exception.PhoenixIOException: java.lang.NoClassDefFoundError: org/apache/hadoop/tracing/SpanReceiverHost
at org.apache.phoenix.util.ServerUtil.parseServerException(ServerUtil.java:138)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.ensureNamespaceCreated(ConnectionQueryServicesImpl.java:1046)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.createSchema(ConnectionQueryServicesImpl.java:4559)
at org.apache.phoenix.schema.MetaDataClient.createSchema(MetaDataClient.java:4074)
at org.apache.phoenix.compile.CreateSchemaCompiler$1.execute(CreateSchemaCompiler.java:46)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:408)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:391)
at org.apache.phoenix.call.CallRunner.run(CallRunner.java:53)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:390)
at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:378)
at org.apache.phoenix.jdbc.PhoenixPreparedStatement.execute(PhoenixPreparedStatement.java:173)
at org.apache.phoenix.jdbc.PhoenixPreparedStatement.execute(PhoenixPreparedStatement.java:183)
at com.digiwin.flink.cdc2kafka.FlinkPhoenixTest2.execute(FlinkPhoenixTest2.java:75)
at com.digiwin.flink.cdc2kafka.FlinkPhoenixTest2.access$000(FlinkPhoenixTest2.java:18)
at com.digiwin.flink.cdc2kafka.FlinkPhoenixTest2$1.open(FlinkPhoenixTest2.java:58)
at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(FunctionUtils.java:34)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.open(AbstractUdfStreamOperator.java:102)
at org.apache.flink.streaming.api.operators.KeyedProcessOperator.open(KeyedProcessOperator.java:55)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:442)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:585)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55)
at org.apache.flink.streaming.runtime.tasks.StreamTask.executeRestore(StreamTask.java:565)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:650)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:540)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:759)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.hadoop.hbase.DoNotRetryIOException: java.lang.NoClassDefFoundError: org/apache/hadoop/tracing/SpanReceiverHost
at org.apache.hadoop.hbase.client.RpcRetryingCallerImpl.translateException(RpcRetryingCallerImpl.java:221)
at org.apache.hadoop.hbase.client.RpcRetryingCallerImpl.callWithRetries(RpcRetryingCallerImpl.java:120)
...
Caused by: java.lang.NoClassDefFoundError: org/apache/hadoop/tracing/SpanReceiverHost
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:634)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:619)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:149)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3288)
...
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.tracing.SpanReceiverHost
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 50 more解决办法:
因为Phoenix版本是CDH版本的,但是pom文件里用的不是的,而且,仅仅需要Phoenix-client就可以了,多了,有jar包冲突
修改pom文件如下:
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-client</artifactId>
<version>5.0.0.7.2.2.6-2</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-common.version}</version>
<exclusions>
<exclusion>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
</exclusion>
</exclusions>
</dependency>然后重新打包,完美解决
还有一个问题:
创建schema的时候,java需要使用PreparedStatement,不能使用
Connection con = DriverManager.getConnection("jdbc:phoenix:ddp5.hadoop:2181");
stmt = con.createStatement();
String sql = "create schema if not exists \"aaa\"";
rs = stmt.executeQuery(sql);这种方式只能查询貌似,不能操作数据库