本文主要包括:
- 实时架构方案设计
- 实时架构方案可行性验证
项目背景
随着企业的数字化转型越来越深入,企业生产交付业务对于实时数据的需求在不断膨胀,实时数据能够帮助企业以最快速度收集来自传感器(日志)、传统数据库(业务系统)等的数据,通过管理数据实时变化迅速建立起对市场需求的形势判断,并最终将其转化为能够提升企业业绩的决策工具
当前现状
现状描述
当前数据采集系统,分为业务数据采集与日志数据采集,日志数据采集已经是实时采集,业务数据采集即传统数据库采集目前采用的是离线采集,技术选用datax,每天凌晨抽取一次数据到hive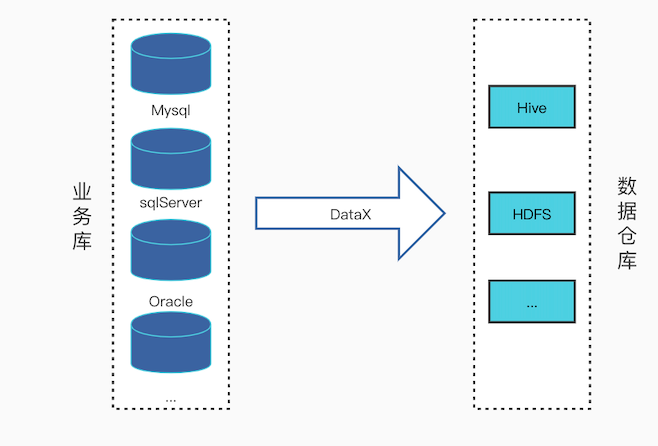
痛点问题
- 离线采集数据更新延迟,无法及时获取业务数据
- 凌晨采集任务集中,集群资源消耗大(目前公司还没这个问题,但是任务多了以后,存在隐患)
设计目标
通过对现状和痛点问题的分析,实时采集平台的建设应实现以下目标:
- 通过页面配置的方式创建采集任务,并支持数据的实时采集
- 支持多种数据源,例如Mysql、sqlServer、Oracle、MongoDB、PostgreSQL等
- 支持分库分表的数据源
- 数据源字段名/字段类型自动映射,并打通元信息管理
- 集成监控系统,例如实时监控Kakfa数据消费情况,是否存在堆积、背压等情况
- 业务方数据源发生变动,实时采集系统可以自动兼容,或者实时告警。例如,采集的某张Mysql表新增/修改字段,这时候目标HIve可以自动添加/修改,如果mysql表删除字段,采集系统可以及时告警,通知任务创建人员以及时修改
- 支持对敏感数据脱敏
- 实时采集的任务纳入调度系统
- 采集数据源权限管控,有项目权限的人才能创建该数据源的任务
- 资源管控,使用实时资源队列
架构设计原则
实时采集平台是数据中台的重要组成部分,其建设、设计和系统实现过程中,应遵循如下指导原则:
- 高性能: 从计算和存储等方面考虑,如何达到更高的处理能力,例如采用分布式架构原理
- 高可靠: 设计实现更高的容错能力,例如灰度设计、风险隔离、备份恢复、提供降级方案等等
- 高可扩展性: 架构设计与功能划分模块化,考虑各接口的开放性、可扩展性,便于系统的快速扩展与维护,便于第三方系统的快速接入。并从集群层面对高性能和高可靠性提供支持,例如集群负载、容器化设计等等
- 高安全性: 保证信息安全和系统稳定,例如传输加密、认证授权,还有防DDOS、XSS、SQL注入等等。
- 高可维护性: 产品的开发只是一阵子,上线之后的运维和运营那才是一辈子的。因此,除了功能的设计,还需要考虑监控运营、运维工具、自动化运维能力等方面的设计。
系统技术架构
本次项目根据建设目标和设计原则构建实时采集系统,在现有大数据平台基础上,新增实时采集系统,该系统通过Hadoop、Hudi/Iceberg、Kafka来存储数据,用Flink CDC采集业务库数据,集成权限管理系统、监控系统,打通元数据管理系统
系统架构设计
本次实时采集平台建设,平台结构上分为业务数据源层、数据中台stage层、以及数据中台贴源层三个层次,规划将一步到位,但具体实施将采用分期方式进行,第一期主要集中在业务数据源层到数据中台stage层的打通,整体规划如下图: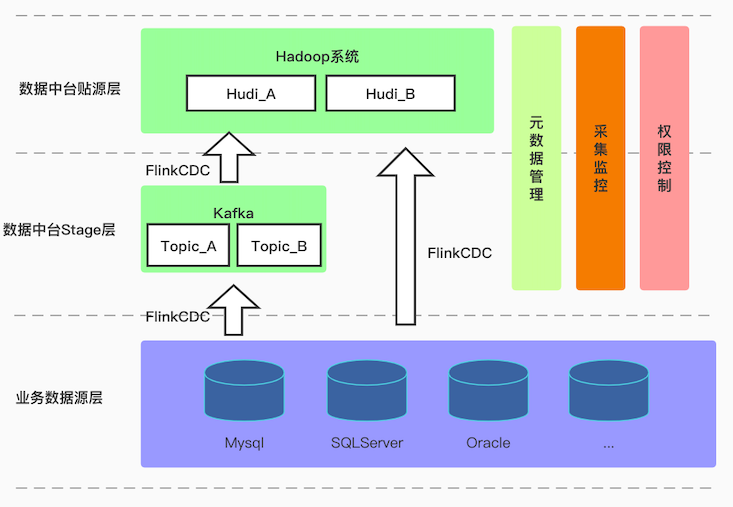
每个层次的主要功能和使用的产品:
业务数据源层
该层是指业务方各系统数据源,即要采集的数据源,该层数据采用的存储组件不一,包含Mysql、SQLServer、Oracle、MongoDB、PostgreSQL等
这里需要考虑一下在采集平台部署采集任务,如何让业务方数据源自动支持CDC?目前还没找到,只能手动操作,后期可以考虑一下
数据中台stage层
该层的主要作用就是缓冲业务数据源与数据中台贴源层之间的数据,以防止数据源波动较大,给上层写数据造成压力,并且可以对上下游解耦,将一个数据源分发给多个下游。考虑到数据的实时性,该层采用Kafka作为存储组件
这里讲解一下Kafka层的必要性:
业务数据源以Mysql为例,数据中台贴源层以Hudi为例:
MySQL 数据通过 Flink CDC 进入到 Kafka。之所以数据先入 Kafka 而不是直接入 Hudi
- 实现多个实时任务复用 MySQL 过来的数据,避免多个任务通过 Flink CDC接 MySQL表以及Binlog,对MySQL库的性能造成影响。
- 防止数据源波动较大的情况下,会对给上层写数据造成压力
数据中台贴源层
该层是数据中台贴源层,用于存储实时采集过来的数据,由于数据是实时更新,所以存储组件需要支持行级更新,这里考虑引入数据湖组件,Hudi/Iceberg,具体Hudi还是Iceberg还需后期考量
采集监控
为了保证系统稳定,需要对采集任务做实时监控,例如业务方数据源是否发生变动,是否加字段或者该字段,kafka数据的消费情况,是否背压等
元数据管理
从大数据平台的角度来看,实时采集系统只是平台的一个功能模块,采集所设计的元数据都需与大数据平台的元数据管理系统交互,例如采集的表的元数据应当被存储在元数据管理系统,上下游依赖关系也需要在元数据管理系统内体现
权限管控
从数据安全角度来看,业务库的权限不应该对所有人开放,应仅对有项目权限的用户开放对应库/表的权限
技术方案选型
采集工具选择
对于采集工具,这里需要引入一个新的概念,CDC(Change Data Capture),在广义的概念上,只要是能捕获数据变更的技术,我们都 可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中 数据变更的技术,CDC 技术应用场景也非常广泛,包括:
- 数据分发,将一个数据源分发给多个下游,常用于业务解耦、微服务。
- 数据集成,将分散异构的数据源集成到数据仓库中,消除数据孤岛,便于后续的分析。
- 数据迁移,常用于数据库备份、容灾等。
目前业界主流的 CDC 实现机制可以分为两种:
- 基于查询的 CDC:
1.1 离线调度查询作业,批处理。依赖表中的更新时间字段,每次执行查询去获取表中最新的数据; 无法捕获删除事件,从而无法保证数据一致性;
1.2无法保障实时性,基于离线调度存在天然的延迟。 - 基于日志的 CDC:
2.1 实时消费日志,流处理。例如MySQL的binlog日志完整记录了数据库中的变更,可以把binlog文件当作流的数据源;
2.2 保障数据一致性,因为binlog文件包含了所有历史变更明细;
2.3 保障实时性,因为类似binlog的日志文件是可以流式消费的,提供的是实时数据。
对比常见的开源CDC方案,我们可以发现:
| DataX | Sqoop | Kettle | Canal | Maxwell | Flink CDC | Debezium | Oracle Goldengate | |
|---|---|---|---|---|---|---|---|---|
| CDC机制 | 查询 | 查询 | 查询 | 日志 | 日志 | 日志 | 日志 | 日志 |
| 增量同步 | × | × | × | √ | √ | √ | √ | √ |
| 断点续传 | × | × | × | √ | √ | √ | √ | √ |
| 全量同步 | √ | √ | √ | × | √ | √ | √ | √ |
| 架构 | 单机 | 分布式 | 分布式 | 单机 | 单机 | 分布式 | 单机 | 分布式 |
| 生态 | ☆☆☆ | ☆☆ | ☆ | ☆☆ | ☆☆☆ | ☆☆☆☆☆ | ☆☆☆ | ☆☆☆ |
实时采集不仅需要采集增量数据,也需要在采集之初做一次初始化,为了尽可能的统一技术栈,在采集工具的选择上,需要选择支持全量+增量一体化的工具,而在全量+增量一体化同步方面,只有Flink CDC、Debezium、MaxWell、Oracle Goldengate支持较好。 |
- 而
Oracle Goldengate是商业软件,不是开源的,业内使用较少。 MaxWell仅支持Mysql的采集,支持的数据源太少- 而
Debezium的锁表操作是一个挺大的痛点,在初始化数据的时候,会影响业务更新Mysql数据
综合考虑,选用Flink CDC2.x作为我们的采集工具
Flink CDC底层封装了Debezium,在FlinkCDC2.x出来之前,其实选择Flink CDC还是Debezium都可以,但是,Flink CDC2.x出来之后,解决了3个痛点问题:
- 全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过全局锁保证,但是加锁容易 对在线业务造成影响,且
DBA一般不给锁权限。 - 不支持水平扩展,因为
Flink CDC底层是基于Debezium,其架构是单节点,所以Flink CDC1.x的数据源只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天 级别,用户无法通过增加资源去提升作业速度。 - 全量读取阶段不支持
checkpoint:CDC读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持checkpoint的,因此会存在一个问题:当我们同步全量数据时,假设需要5个小时,当我们同步了4小时的时候作业失败,这时候就需要重新开始,再读取5个小时。Flink CDC支持的数据源
Stage层技术选型
考虑到Stage层的主要作用就是缓冲业务数据源与数据中台贴源层之间的数据,并且数据的实时性要求较高,这里采用Kafka作为该层的存储组件
数据中台贴源层技术选型
用于存储实时采集过来的数据,由于数据是实时更新,所以存储组件需要支持行级更新,还要支持SQl做ETL分析,这里考虑引入数据湖组件,Hudi/Iceberg,Hudi/Iceberg依托于HDFS以保证整体大数据架构的兼容性,具体Hudi还是Iceberg还需后期考量。Hudi对上下游生态的开放、对全局索引的 支持、对Flink 1.13版本的支持比Iceberg更好
采集流程
根据是否需要Kafka缓存有两种采集流程:
默认情况下不接入Kafka,数据经FlinkCDC从业务库采集后直接入Hudi,具体流程图如下:
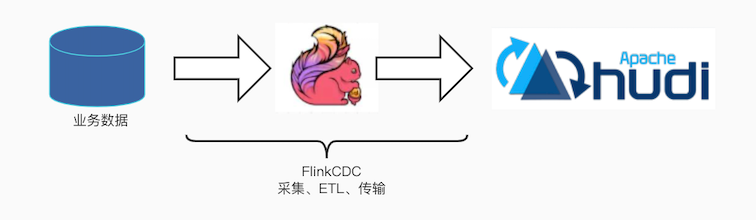
这种采集流程有如下优点:
1)减少维护的组件,简化实时链路,减轻部署成本
2)减小端到端延迟
3)数据不落地,减少存储成本
有如下缺点:
1)数据仅能做到分钟级别的准实时。对实时性要求不是特别高的,可以使用这种方式
2)数据源波动较大的情况下,会对给上层写数据造成压力
3)业务方数据和下游数据中台耦合性比较强当用户指定需要Kafka做数据缓存时,数据经FlinkCDC先写入kafka,之后再有一个FlinkCDC程序实时读取kafka数据写入Hudi中。具体流程图如下:

这种采集方案有如下优点:
1)数据纯实时采集,实时性高
2)利用Kafka消息队列做解耦,binlog可供任何其他业务系统使用
3)数据量大的情况下,不会对上层写数据造成压力
有如下缺点:
1)中间多了一层kafka组件,实时链路更长,部署成本稍高
2)数据多在kafka中存储一份,增加了存储成本
3)kafka的数据需要定期删除,不会存储全量的数据,只能从kafka里读取增量数据,数据源变更频率低的情况,这种不适合,会丢数据
系统流程
由于本次的采集系统是支持页面可配置的,所以需要和前端页面做交互,具体的流程图如下: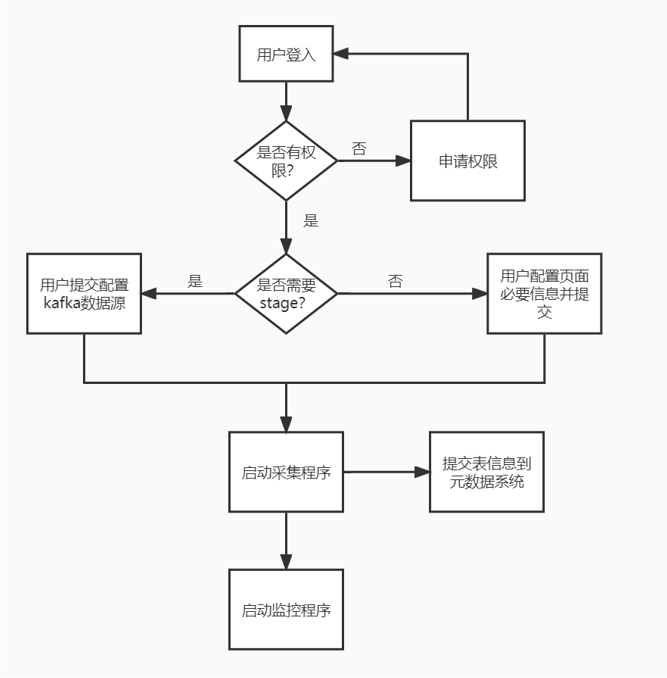
- 用户检查是否有目标表所在项目权限,如无先申请项目权限
- 用户根据目标表数据波动以及是否存在多个流计算任务消费该目标表选择采集流程
- 在页面选择实时采集的必要参数
- 前端页面返回参数,在元数据系统记录该表的信息,并启动实时采集程序
- 启动监控程序
方案可行性验证
环境准备
Flink CDC2.x需要使用Flink1.13.x及以上的版本,首先需要替换集群的Flink版本,由于公司的大部分软件为CDH版本,这里的Flink需要下载源码指定CDH版本的Hadoop重新编译
mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.2.0 -Pvendor-repos -Dinclude-hadoop -Dscala-2.11 -T10C
# -Dfast #在flink根目录下pom.xml文件中fast配置项目中含快速设置,其中包含了多项构建时的跳过参数. #例如apache的文件头(rat)合法校验,代码风格检查,javadoc生成的跳过等,详细可阅读pom.xml
# install maven的安装命令
# -T10C #支持多处理器或者处理器核数参数,加快构建速度,推荐Maven3.3及以上
# -Pinclude-hadoop 将hadoop的 jar包,打入到lib/中
# -Pvendor-repos # 如果需要指定hadoop的发行商,如CDH,需要使用-Pvendor-repos
# -Dscala-2.12 # 指定scala的版本为2.12
# -Dhadoop.version=3.0.0-cdh6.2.0 指定 hadoop 的版本,这里的版本与CDH集群版本的Hadoop一致就行在集群安装编译好的Flink软件,并配置环境变量
export FLINK_HOME=/opt/soft/flink-1.13.6
export PATH=$PATH:${FLINK_HOME}/bin
export HADOOP_CLASSPATH=`hadoop classpath`这里可以参考我的博客maven编译Hudi与Flink源码
Flink CDC实时采集Mysql入Kafka
这里只是简单介绍一下测试流程和测试结果,具体可以参考我的博客flink-cdc实时采集数据库入Kafka
Mysql开启binlog
在/etc/my.cnf中mysqld节添加开启binlog的配置:
#设置日志路径,注意路经需要mysql用户有权限写
## /data/mysql/logs/是binlog存储路径,mysql-bin是文件名
## 在该文件夹下会生成 mysql-bin.000001、 mysql-bin.index文件
log-bin = /data/mysql/logs/mysql-bin
#选择row模式
binlog_format=ROW
##配置serverid
server_id=1
#设置binlog清理时间
expire_logs_days = 7
##binlog每个日志文件大小
max_binlog_size = 100m
##binlog缓存大小
binlog_cache_size = 4m
##最大binlog缓存大小
max_binlog_cache_size = 512m修改完配置后,重启mysql。执行SHOW VARIABLES LIKE ‘log_bin’; Value 值为 ON即可
service mysqld restart通过DataStream方式编写CDC代码
- 配置maven依赖
<dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <!-- the dependency is available only for stable releases. --> <version>2.1.1</version> </dependency> - 编写java代码
以per-job方式提交Flink任务到yarn上package com.digiwin.flink.cdc2kafka; import com.ververica.cdc.connectors.mysql.source.MySqlSource; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.*; public class Mysql2Kakfa { private static final Logger log = LoggerFactory.getLogger(Mysql2Kakfa.class); private static String hostName ; private static int yourPort; private static String dbName; private static String tableName; private static String userName; private static String password; public static void main(String[] args) throws Exception { //parseArgs(args); hostName = "localhost"; yourPort = 3306; dbName = "test"; tableName = "test.gjc_test_binlog"; userName = "root"; password = "Hive123!@#"; System.out.println("hostName:" + hostName + ",port:" + yourPort + ",dbName:" + dbName + ",tableName:" + tableName + ",userName:" + userName + ",password:" + password ); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname(hostName) .port(yourPort) .databaseList(dbName) // set captured database .tableList(tableName) // set captured table .username(userName) .password(password) .startupOptions(StartupOptions.initial()) .deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String .build(); DataStreamSource<String> dataStreamSource = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source"); dataStreamSource.addSink(new FlinkKafkaProducer<String>("golden-02:9092", "test.gjc_test_binlog", new SimpleStringSchema())); env.execute("Print MySQL Snapshot + Binlog"); } }
数据很成功的采集到kafka了${FLINK_HOME}/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 -yqu root.default -ynm gjc_test_flink-cdc-mysql -c com.digiwin.flink.cdc2kafka.Mysql2Kakfa target/FlinkCDCTest-1.0-SNAPSHOT-jar-with-dependencies.jar
添加断点续传
首先在代码里添加checkpoint相关代码:
//配置ck的状态后端
env.setStateBackend(new HashMapStateBackend());
//设置系统异常退出或人为 Cancel 掉,不删除checkpoint数据
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置checkpoint存储目录
env.getCheckpointConfig().setCheckpointStorage("hdfs://flink/checkpoint/cdc/gjc_test_Mysql2Kakfa");
env.enableCheckpointing(3000);启动任务后,在hdfs上查看checkpoint文件夹:
[root@ddp2 ~]# hadoop fs -ls /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/
Found 3 items
drwxr-xr-x - root supergroup 0 2022-03-19 11:51 /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/chk-27
drwxr-xr-x - root supergroup 0 2022-03-19 11:49 /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/shared
drwxr-xr-x - root supergroup 0 2022-03-19 11:49 /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/taskowned- 手动取消flink任务
- 重新启动flink,需要注意的是,任务启动的时候,需要指定checkopint地址
${FLINK_HOME}/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 -yqu root.default -ynm gjc_test_flink-cdc-mysql -s hdfs:///flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/chk-27 -c com.digiwin.flink.cdc2kafka.Mysql2Kakfa target/FlinkCDCTest-1.0-SNAPSHOT-jar-with-dependencies.jar - 在mysql中添加数据
insert into gjc_test_binlog values(8,8,'2018-11-10'); insert into gjc_test_binlog values(9,9,'2018-11-10'); - 在flink监控页面查看日志
可以查看到,数据是从8,9开始的。断点续传测试成功
测试采集没有主键的表
采集没有主键的表,通过DataStream的方式没找到办法,但是通过StreamTableEnvironment的方式,可以采集
主要是通过设置scan.incremental.snapshot.enabled=false来达到这种目的
这种方式下,在数据全量采集(初始化)阶段,会锁表,还是有风险的,尽量保证有主键
采集分表分库
这里相对简单,只要把表明和库名以正则的方式输入即可
dbName = "[a-zA-Z\\d]+_test";
tableName = "[a-zA-Z\\d]+_test.gjc_test_binlog_[0-9][0-9]";修改mysql字段,检查代码兼容性
Flink CDC实时采集Mysql入Hudi
待验证。。
Flink CDC实时采集Sqlserver入Kafka
待验证。。。
Flink CDC实时采集Sqlserver入Hudi
待验证。。。
开发计划于未来规划
开发计划
- 开发FlinkCDC程序,使其满足实时采集Mysql入Kafka/Hudi、断点续传、分库分表等功能
- 和服务端联调,支持可配置化
- 支持表结构改变自动同步下游目标表结构,并修改元数据系统信息
- 开发实时采集监控程序
- 开发程序支持采集SqlServer等数据源实时采集
未来规划
未来规划开发FlinkSQL平台,这样采集可以直接通过在页面写SQL的方式直接入数据湖组件,并且可以在采集的过程中就把ETL做了,像一些维表的关联等等