本文主要包括:
- hdfs块文件丢失
hdfs块文件丢失
最近公司集群扩容,运维那边不知道怎么操作的,导致hdfs的block块文件丢失了。
个人猜测,公司的五台节点,都新挂载了一个新盘,datanode上配置了新盘,重启之后,hadoop集群肯定是要负载均衡一下的,迁移一些文件到新盘
这时候namenode会可能会进入安全模式,CM上很多组件都会报红,这时候我们的运维强制退出了安全模式,重启了hadoop集群,但是只是猜测,具体原因找不到了
先说问题描述:
启动hive的时候,报如下报错日志:
Caused by: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/root/eceb6690-1510-4703-8a4b-60ea03c3fcec. Name node is in safe mode.
The reported blocks 10427 needs additional 4373 blocks to reach the threshold 0.9990 of total blocks 14815.
The number of live datanodes 3 has reached the minimum number 1. Safe mode will be turned off automatically once the thresholds have been reached. NamenodeHostName:ddp2
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.newSafemodeException(FSNamesystem.java:1448)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1435)
... 12 more很明显,报错就是丢失了4373个block,导致namenode进入安全模式
原因分析
出现前面提到的问题主要原因是客户端写入的数据没有及时保存到磁盘中,从而导致数据丢失;又因为数据块丢失达到一定的比率,导致hdfs启动进入安全模式。
为了弄清楚导致安全模式的原因,下面主要对hdfs安全模式和如何退出安全模式进行分析。
安全模式
当 hdfs的NameNode节点启动时,会进入安全模式阶段。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。
在此阶段,NameNode加载fsimage(Filesystem image:文件meta信息的持久化的检查点)文件到内存中,然后在editlog中执行相应的操作。加载fsimage文件包含文件metadata信息,但是不包含文件块位置的信息。
DataNode启动的时候扫描本地磁盘,保存的block信息,然后将这些信息汇报给NameNode,让 NameNode得到块的位置信息,并对每个文件对应的数据块副本进行统计。
如果hdfs数据量很大时,进入至退出安全模式时间较长。
安全模式退出条件
当最小副本条件满足时,即一定比例(dfs.safemode.threshold.pct缺省值0.999f)的数据块都达到最小副本数,系统就会退出安全模式。当最小副本条件未达到要求时,就会对副本数不足的数据块安排DataNode进行复制,直至达到最小副本数。如果datanode丢失的block达到一定的比例(1-dfs.safemode.threshold.pct),则系统会一直处于安全模式状态即只读状态。而在安全模式下,系统会处于只读状态,NameNode不会处理任何块的复制和删除命令。
dfs.safemode.threshold.pct(缺省值0.999f)表示HDFS启动的时候,如果DataNode上报的block个数达到了元 数据 记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
解决方法
比较粗暴的方式,删除损坏掉的block
- 执行命令退出安全模式:
hadoop dfsadmin -safemode leave - 执行健康检查,删除损坏掉的block。
这里的路径虽然写的是hdfs fsck / -delete/,但是不是删除所有文件,是删除根目录以下的所有的损坏的块文件
生产环境一般考虑先恢复: 找到数据块的位置和丢失的数据信息
- 查看/所有分区信息:
hdfs hdfs fsck / -files -blocks -locations - 恢复数据文件,前提是,datanode里的block文件还存在,如果不存在了,虽然信息提示SUCCESS,但是其实还是没有恢复成功
我这里使用恢复命令没有效果,直接到datanode的文件存储目录查看了以下,报找不到的block都找不到hdfs debug recoverLease -path ${path}cd /data/dfs/dn/current ## 通过查看hdfs-site.xml查看datanode的文件实际存储位置 find . -name "blk_1073743358_2534*" ## 查看当前目录及以下,文件名包含blk_1073743358_2534的文件。
通过查看hdfs-site.xmhjl找到datanode的日志文件路径:/var/log/hadoop-hdfs
查看datanode日志文件: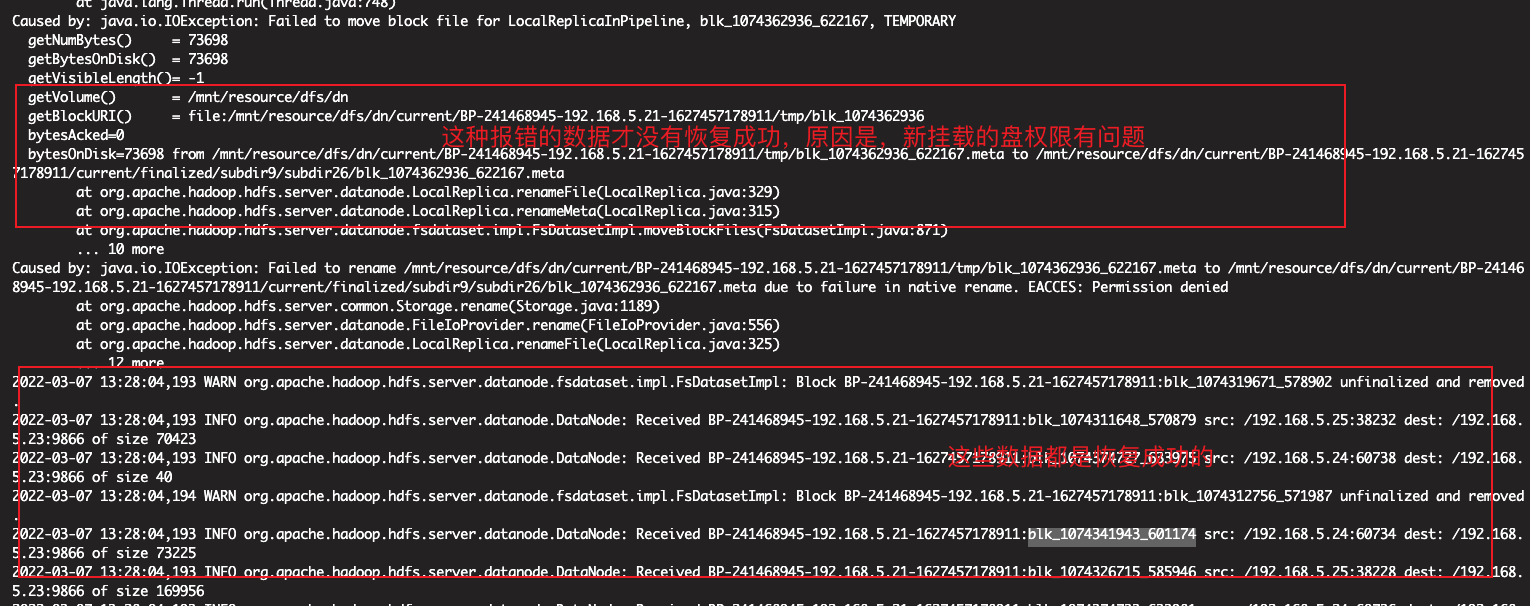
通过日志可以看出,之前的恢复命令有的成功,有的失败,这里分别找了成功和失败的block查看了一下,发现成功日志的block块是恢复成功了,但是失败的确实没有成功
## 以下文件是成功的block块的文件,查看block块所属哪个文件路径,可以通过hdfs hdfs fsck / -files -blocks -locations命令查看
[root@ddp3 tmp]# hadoop fs -ls /tmp/logs/digiwin/logs/application_1645166873581_4910/ddp4_8041
-rw-r----- 3 digiwin hadoop 70423 2022-03-01 11:13 /tmp/logs/digiwin/logs/application_1645166873581_4910/ddp4_8041查看datanode3的log,找其中一块block查看具体的生成时间,已经从哪台节点复制过来的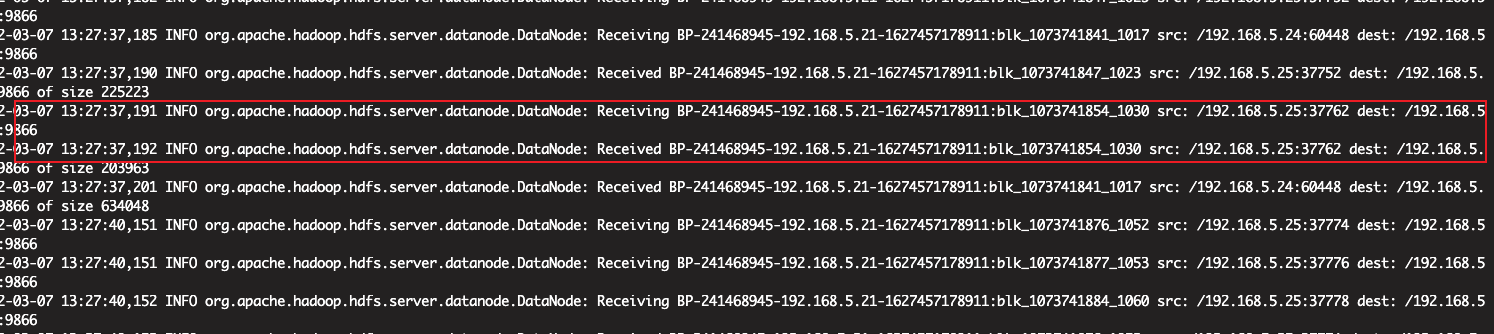
可以看出,blk_1073741854是2022-03-07 13:27:37从192.168.5.25复制过来的。
查看datanode3的blk_1073741854生成时间: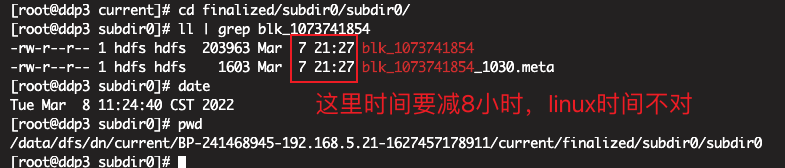
查看datanode5的blk_1073741854生成时间:
可以很明显的看出,blk_1073741854在dn5上是2022-03-04的时候生成的,但是dn3是2022-03-07新复制的
所以,数据恢复操作,要有一个前提,丢失的块不能没有副本,需要从其他副本节点复制过来
这里也可以参考一下HDFS中datanode节点block损坏后的自动恢复过程