本文主要包括:
- maven编译Hudi与Flink源码
maven编译hudi源码
到github上下载hudi源码,本文选择0.11.0版本
git clone https://github.com/apache/hudi.git -b release-0.11.0 集群环境
Flink-1.13.6
Scala-2.12
CDH-6.2.0
Hadoop-3.0.0
Hive-2.1.1
Hudi-0.11(release-0.11.0 )
maven-3.6.3
jdk-1.8
配置maven并编译源代码
为了加快下载速度,修改maven的settings.xml,添加aliyun远程仓库
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>注意: 这里是https,原本从自己电脑上复制下来是http,然后一直报如下错误: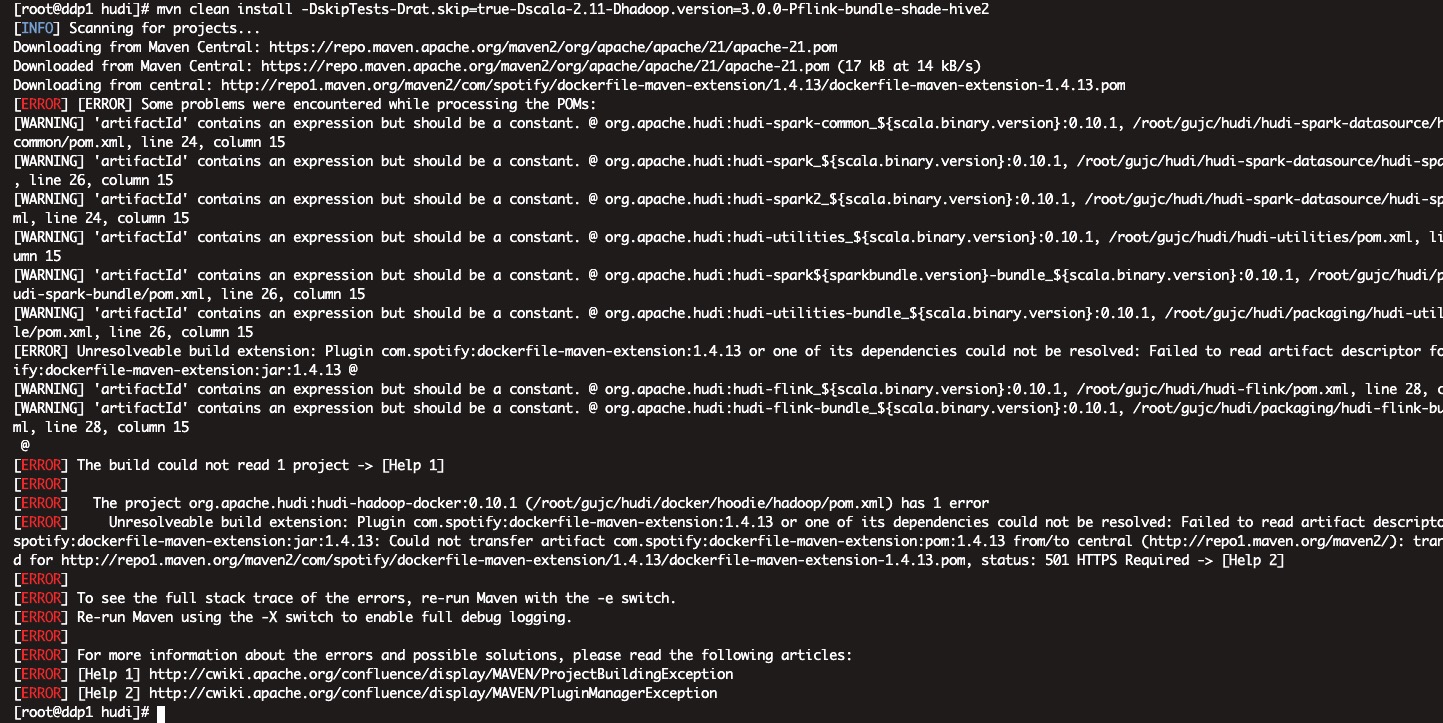
编译时报错,显示连接中央仓库501
经过百度得知,原来中央仓库不再支持http访问,需要将路径更改为https
进入hudi源代码目录,并执行一下语句:
mvn clean install -DskipTests -Dmaven.test.skip=true -Dscala-2.12 -Dhadoop.version=3.0.0-cdh6.2.0 -Pflink1.13 -Pflink-bundle-shade-hive2 -T20C开始的时候没有指定跳过检查,导致一直报错,编译的时候,一定要跳过检查
- -DskipTests
- -Dmaven.test.skip=true
hudi-0.11.0默认用的flink版本是1.14.4,但是,官方给留了一个参数,可以在编译的时候指定flink版本为1.13
即加上参数-Pflink1.13
这里的参数可以在hudi最外层的pom文件里看到,配置如下:
<profile>
<id>flink1.13</id>
<properties>
<flink.version>${flink1.13.version}</flink.version>
<flink.runtime.artifactId>flink-runtime_${scala.binary.version}</flink.runtime.artifactId>
<flink.table.runtime.artifactId>flink-table-runtime-blink_${scala.binary.version}</flink.table.runtime.artifactId>
<flink.table.planner.artifactId>flink-table-planner-blink_${scala.binary.version}</flink.table.planner.artifactId>
<hudi.flink.module>hudi-flink1.13.x</hudi.flink.module>
<flink.bundle.version>1.13</flink.bundle.version>
<skipITs>true</skipITs>
</properties>
<activation>
<property>
<name>flink1.13</name>
</property>
</activation>
</profile>这种profile在编译的时候,就可以指定-P,后面跟
报错与踩坑
找不到合适的构造器 [ERROR] 构造器
Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.8.0:compile (default-compile) on project hudi-common: Compilation failure [ERROR] /opt/hudi/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java:[111,44] 对于FSDataOutputStream(java.io.ByteArrayOutputStream), 找不到合适的构造器 [ERROR] 构造器 org.apache.hadoop.fs.FSDataOutputStream.FSDataOutputStream(java.io.OutputStream,org.apache.hadoop.fs.FileSystem.Statistics)不适用 [ERROR] (实际参数列表和形式参数列表解决办法:
FSDataOutputStream outputStream = new FSDataOutputStream(baos, null) 把报错的地方第二个参数加上java.lang.NoSuchMethodError: org.apache.parquet.bytes.BytesInput.toInputStream()Lorg/apache/parquet/bytes/ByteBufferInputStream;
2022-05-10 15:41:49,463 WARN org.apache.flink.runtime.taskmanager.Task [] - split_reader -> NotNullEnforcer(fields=[uuid]) (3/4)#0 (de4312b557275e636b33cacdeca84148) switched from RUNNING to FAILED with failure cause: java.lang.NoSuchMethodError: org.apache.parquet.bytes.BytesInput.toInputStream()Lorg/apache/parquet/bytes/ByteBufferInputStream; at org.apache.flink.formats.parquet.vector.reader.AbstractColumnReader.readPageV1(AbstractColumnReader.java:211) at org.apache.flink.formats.parquet.vector.reader.AbstractColumnReader.readToVector(AbstractColumnReader.java:156) at org.apache.hudi.table.format.cow.vector.reader.ParquetColumnarRowSplitReader.nextBatch(ParquetColumnarRowSplitReader.java:311) at org.apache.hudi.table.format.cow.vector.reader.ParquetColumnarRowSplitReader.ensureBatch(ParquetColumnarRowSplitReader.java:287) at org.apache.hudi.table.format.cow.vector.reader.ParquetColumnarRowSplitReader.reachedEnd(ParquetColumnarRowSplitReader.java:266) at org.apache.hudi.table.format.mor.MergeOnReadInputFormat$BaseFileOnlyFilteringIterator.reachedEnd(MergeOnReadInputFormat.java:509) at org.apache.hudi.table.format.mor.MergeOnReadInputFormat.reachedEnd(MergeOnReadInputFormat.java:245) at org.apache.hudi.source.StreamReadOperator.consumeAsMiniBatch(StreamReadOperator.java:186) at org.apache.hudi.source.StreamReadOperator.processSplits(StreamReadOperator.java:166) at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:50) at org.apache.flink.streaming.runtime.tasks.mailbox.Mail.run(Mail.java:90) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMailsNonBlocking(MailboxProcessor.java:359) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.processMail(MailboxProcessor.java:323) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:202) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:684) at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:639) at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:650) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:623) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:779) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)flink写数据到hudi没有问题,数据同步到hive也没问题,从hive里可以正常查询,但是,通过flink查询就会报以上错误。
这里很明显可以看出,这个报错是parquet jar包冲突了
解决办法:
修改packaging/hudi-flink-bundle/pom.xml
在relocations里添加以下参数:<relocation> <pattern>org.apache.parquet.</pattern> <shadedPattern>${flink.bundle.shade.prefix}org.apache.parquet.</shadedPattern> </relocation>问题解决
最终编译成功: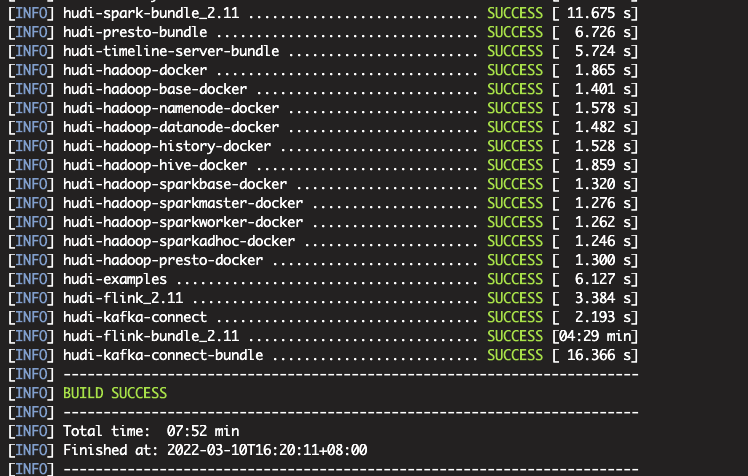
编译结果说明
packaging/hudi-flink-bundle/target下的hudi-flink-bundle jar 是 flink 用来写入和读取数据
补充maven相关知识
Maven如何配置多个远程仓库
常用配置:我们常用的配置是在maven的配置文件的 mirrors 标签中去配置远程仓库,但是 mirrors 标签中配置多个远程仓库的时候,只有第一个会生效,只有第一个仓库无法访问的时候才会使用第二个仓库,如果第一个仓库能访问,但是没有你所需要的依赖,那它是不会去第二个仓库中下载依赖的。所以如果在这里配置远程仓库的话,因为不同项目用到的依赖不一样,不是每个仓库中都有,这时候就需要你手动切换远程仓库。
<mirror>
<id>alimaven</id>
<mirrorOf>central,!cloudera</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>多个远程仓库配置:在Maven的配置文件中的 profiles 标签下面配置多个远程仓库,这样配置之后,如果第一个仓库中如果没有你需要的依赖,或者第一个仓库无法访问,那么会自动的去第二个仓库中下载你需要的依赖,就不需要手动切换远程仓库了。
<profiles>
<profile>
<id>myProfile</id>
<repositories>
<repository>
<id>myRepository</id>
<name>Repository for me</name>
<url>http://xxxx:8081/nexus/content/groups/public</url>
</repository>
<repository>
<id>deploymentRepo</id>
<name>deploymentRepo</name>
<url>https://repo.digiwincloud.com.cn/maven/repository/releases/</url>
</repository>
</repositories>
</profile>
</profiles>
<activeProfiles>
<activeProfile>myProfile</activeProfile>
</activeProfiles>注意:
- 在 profiles 标签中配置过远程仓库之后,mirrors 标签中就不需要再配置了,原先配置过也可以删掉或者注释掉。
- settings.xml配置文件中最好不要写中文注释,一定要记得将中文注释删掉。
maven编译Flink源码
环境还是上面的环境,这里选用flink-1.13.6进行编译
wget https://dlcdn.apache.org/flink/flink-1.13.6/flink-1.13.6-src.tgz --no-check-certificate
tar zxvf flink-1.13.6-src.tgz -C .以前需要先编译flink-shaded-hadoop这个包,将hadoop和hive指定你对应生产的版本编译出flink-shaded-hadoop-2-uber_xxx包,然后将这个包放在lib的目录下,flink启动任务的时候去lib加载。
自从1.11.0版本以后,Flink官方为了让Flink变得Hadoop Free,现在能支持hadoop2和hadoop3,同时可以指定不同的Hadoop环境
为了达到这一目标,通过设置export HADOOP_CLASSPATH=hadoop classpath即可,不用编译flink-shaded包。
重点: 编译好的Flink的jar里面是没有包含Hadoop和Hive的代码。当Flink任务启动的时候,JM和TM都是通过HADOOP_CLASSPATH环境变量获取Hadoop的相关变量。
因为之前都已经配置过maven环境了,所以编译起来还是很方便的,直接运行编译代码:
mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.2.0 -Pvendor-repos -Dinclude-hadoop -Dscala-2.12 -T10C
# -Dfast #在flink根目录下pom.xml文件中fast配置项目中含快速设置,其中包含了多项构建时的跳过参数. #例如apache的文件头(rat)合法校验,代码风格检查,javadoc生成的跳过等,详细可阅读pom.xml
# install maven的安装命令
# -T10C #支持多处理器或者处理器核数参数,加快构建速度,推荐Maven3.3及以上
# -Pinclude-hadoop 将hadoop的 jar包,打入到lib/中
# -Pvendor-repos # 如果需要指定hadoop的发行商,如CDH,需要使用-Pvendor-repos
# -Dscala-2.12 # 指定scala的版本为2.12
# -Dhadoop.version=3.0.0-cdh6.2.0 指定 hadoop 的版本,这里的版本与CDH集群版本的Hadoop一致就行maven 编译Flink-1.15.0
总是报如下错误
Running 'npm install --cache-max=0 --no-save' in /opt/gitrepo/flink-runtime-web/web-dashboard在flink的源码里,找到flink-runtime-web模块,里面的README.md有单独的编译方法,按照如下流程编译
cd flink-runtime-web/web-dashboard
npm install
npm run build但是,在执行npm install的时候,一直报如下错误:
npm ERR! path /root/flink/flink-runtime-web/web-dashboard/node_modules/@angular/cli
npm ERR! command failed
npm ERR! command sh -c node ./bin/postinstall/script.js
npm ERR! node:internal/modules/cjs/loader:936
npm ERR! throw err;
npm ERR! ^
npm ERR!
npm ERR! Error: Cannot find module '/root/flink/flink-runtime-web/web-dashboard/node_modules/@angular/cli/bin/postinstall/script.js'
npm ERR! at Function.Module._resolveFilename (node:internal/modules/cjs/loader:933:15)这是因为这里用的是root权限编译的。npm对root权限管控很厉害。不能使用root权限编译
这里切换到非root用户重新编译flink源码(不需要单独执行flink-runtime-web/web-dashboard了)
mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.2.0 -Pvendor-repos -Dinclude-hadoop -Dscala-2.12 -T10C解决办法:
修改flink源码flink-runtime-web的pom,把里面的npm.proflile给成以下内容
-registry=https://registry.npm.taobao.org
报错:
[ERROR] Failed to execute goal org.apache.rat:apache-rat-plugin:0.13:check (default) on project flink-parent: Too many files with unapproved license: 1 See RAT report in: /root/flink-bak/target/rat.txt -> [Help 1]错误原因:
由于添加了apache-rat-plugin插件,所以项目中新添加的文件如果没有加上License头,会在检查时报错。
解决方案:
文件打包时跳过检查,添加: -Drat.skip=true