本文主要包括:
- Flink-CDC实时采集Mysql入Kafka
- Flink-CDC实时采集Sqlserver入Kafka
Flink-CDC实时采集Mysql入Kafka
环境信息:
flink-1.13.6
mysql-5.7.26
kafka_2.11-2.1.0-cdh6.2.0
Mysql开启binlog
binlog的三种模式比较
binlog的格式也有三种:STATEMENT、ROW、MIXED。
STATMENT模式: 基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的sql语句会记录到binlog中。
优点: 不需要记录每一条SQL语句与每行的数据变化,这样子binlog的日志也会比较少,减少了磁盘IO,提高性能。
缺点: 在某些情况下会导致master-slave中的数据不一致 。
ROW基于行的复制(row-based replication, RBR)格式: 不记录每一条SQL语句的上下文信息,仅需记录哪条数据被修改了,修改成了什么样子了。
优点: 不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。
缺点: 会产生大量的日志,尤其是alter table的时候会让日志暴涨。
MIXED混合模式复制(mixed-based replication, MBR):以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
具体参考MySQL如何开启binlog?binlog三种模式的分析
我们实时采集mysql数据,需要开启ROW模式
binlog开启步骤
这里参考我的另外一篇博客Centos安装Mysql
测试案例
通过简单的sqlClient读取mysqlBinlog数据
在测试之前,需要把flink-sql-connector-mysql-cdc-2.1.1.jar放到${FLINK_HOME}\lib下
首先需要启动flink的集群,因为sqlClient貌似无法提交代码到yarn上,如果不启动集群,会报
Connect Refused,找了很久的原因在sqlClient创建一个表来映射mysql表
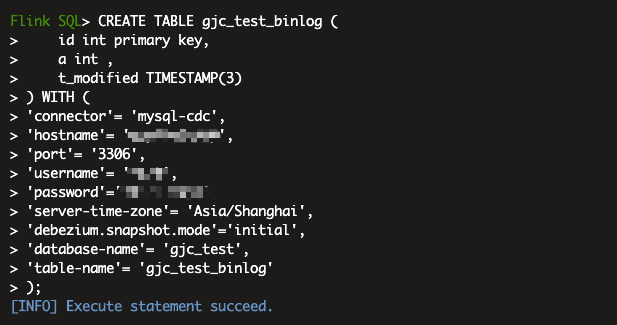
查询数据
验证没问题通过DataStream方式编写CDC代码
pom.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>FlinkCDCTest</artifactId> <version>1.0-SNAPSHOT</version> <properties> <flink.version>1.13.6</flink.version> <java.version>1.8</java.version> <!--scala版本,用于flink框架内部通信,它自己用 --> <scala.binary.version>2.12</scala.binary.version> <cdc.version>2.1.1</cdc.version> <slf4j.version>1.7.30</slf4j.version> </properties> <dependencies> <dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <!-- the dependency is available only for stable releases. --> <version>${cdc.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>2.4.1</version> <configuration> <!-- get all project dependencies --> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <!-- bind to the packaging phase --> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> </plugins> </build> </project>编写代码如下:
package com.digiwin.flink.cdc2kafka; import com.ververica.cdc.connectors.mysql.source.MySqlSource; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.*; public class Mysql2Kakfa { private static final Logger log = LoggerFactory.getLogger(Mysql2Kakfa.class); private static String hostName ; private static int yourPort; private static String dbName; private static String tableName; private static String userName; private static String password; private static boolean isTest = false; private static void parseArgs(String[] args) { log.info("begin export data! args={}", Arrays.toString(args)); List<String> argsLeft = new ArrayList<>(); for (int i = 0; i < args.length; i++) { if ("-isTest".equals(args[i])) { isTest = true; } else { argsLeft.add(args[i]); } } if (argsLeft.size() % 2 != 0) { log.error("输入参数个数异常,请检查!"); System.exit(1); } //判断错误参数的标记,如果有错误参数,异常退出 int error = 0; for (int i = 0; i < argsLeft.size(); i = i + 2) { if ("-hostName".equals(argsLeft.get(i))) { hostName = argsLeft.get(i + 1); } else if ("-yourPort".equals(argsLeft.get(i))) { yourPort = Integer.parseInt(argsLeft.get(i + 1)); } else if ("-dbName".equals(argsLeft.get(i))) { dbName = argsLeft.get(i + 1); } else if ("-tableName".equals(argsLeft.get(i))) { tableName = argsLeft.get(i + 1); } else if ("-userName".equals(argsLeft.get(i))) { userName = argsLeft.get(i + 1); } else if ("-password".equals(argsLeft.get(i))) { password = argsLeft.get(i + 1); } } if (error > 0) { System.exit(1); } } public static void main(String[] args) throws Exception { //parseArgs(args); hostName = "localhost"; yourPort = 3306; dbName = "test"; tableName = "test.gjc_test_binlog"; userName = "root"; password = "Hive123!@#"; System.out.println("hostName:" + hostName + ",port:" + yourPort + ",dbName:" + dbName + ",tableName:" + tableName + ",userName:" + userName + ",password:" + password ); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); MySqlSource<String> mySqlSource = MySqlSource.<String>builder() .hostname(hostName) .port(yourPort) .databaseList(dbName) // set captured database .tableList(tableName) // set captured table .username(userName) .password(password) .startupOptions(StartupOptions.initial()) .deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String .build(); env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source") //.setParallelism(4) .print(); env.execute("Print MySQL Snapshot + Binlog"); } }StartupOptions可选的模式含义:
initial:
第一次启动时 读取原表已有的历史数据, 操作类型为READ, 之后不断做检查点存储
第二次启动时 一定要指明检查点文件的具体位置, 这样就可以断点续传; 即使Flink宕机了, 重启后是从上次offset开始读, 而不是latest
检查点在打包部署后才有用, 因为那样才可以指明检查点的具体位置这种模式下,因为读取的存量数据,数据写入kafka是乱序的,但是这个应该是不受影响的,因为,每条数据都是唯一的,而且数据都是存量的,不会出现数据的值不对的情况
earliest:
从BinLog第一行数据开始读, 最好先给这个数据库加上BinLog后, 再去读取创建数据库latest:
读取最新变更数据, 从Flink程序启动后开始算timestamp:
可以从BinLog某一时刻的数据开始读specificOffset:
指明BinLog文件位置和从哪个offset开始读
这个一般来说不怎么用, 因为本地没存offset的信息, 很难知道offset读到哪了
<!--在IDEA里执行需要添加以下依赖,但是,打包到yarn上执行,貌似会有问题,但是,后面又测试了几次,又可以了-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>在idea里可以执行,结果如图:
但是通过打成jar包上传到集群中,就开始报错了,执行命令如下
flink run -c com.digiwin.flink.cdc2kafka.Mysql2Kakfa FlinkCDCTest-1.0-SNAPSHOT-jar-with-dependencies.jar报错如下:
Caused by: java.lang.RuntimeException: Failed to get driver instance for jdbcUrl=jdbc:mysql://ddp5.hadoop:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL
at com.zaxxer.hikari.util.DriverDataSource.<init>(DriverDataSource.java:114)
at com.zaxxer.hikari.pool.PoolBase.initializeDataSource(PoolBase.java:331)
at com.zaxxer.hikari.pool.PoolBase.<init>(PoolBase.java:114)
at com.zaxxer.hikari.pool.HikariPool.<init>(HikariPool.java:108)
at com.zaxxer.hikari.HikariDataSource.<init>(HikariDataSource.java:81)
at com.ververica.cdc.connectors.mysql.source.connection.PooledDataSourceFactory.createPooledDataSource(PooledDataSourceFactory.java:54)
at com.ververica.cdc.connectors.mysql.source.connection.JdbcConnectionPools.getOrCreateConnectionPool(JdbcConnectionPools.java:51)
at com.ververica.cdc.connectors.mysql.source.connection.JdbcConnectionFactory.connect(JdbcConnectionFactory.java:53)
at io.debezium.jdbc.JdbcConnection.connection(JdbcConnection.java:872)
at io.debezium.jdbc.JdbcConnection.connection(JdbcConnection.java:867)
at io.debezium.jdbc.JdbcConnection.connect(JdbcConnection.java:413)
at com.ververica.cdc.connectors.mysql.debezium.DebeziumUtils.openJdbcConnection(DebeziumUtils.java:62)
... 31 more
Caused by: java.sql.SQLException: No suitable driver
at java.sql.DriverManager.getDriver(DriverManager.java:315)
at com.zaxxer.hikari.util.DriverDataSource.<init>(DriverDataSource.java:106)
... 42 more期间换了cdc的版本,换成2.0.0和2.1.1都可以执行,但是2.1.0就是不行就是报No suitable driver
最终找到原因:
因为${FLINK_HOME}/lib下我放的cdc jar包是2.1.1的,但是,我pom文件里写的是2.1.0,两个版本不一样导致的
解决方法:
- 可以把pom文件里的cdc版本换成2.1.1的
- 或者把lib文件夹下的cdc jar包换成2.1.0的(其实,如果要是使用java写代码的方式,lib下不需要放cdc的jar包,配置lib文件夹,主要是为了给sqlClient方式使用,经过测试,不配置lib下的cdc jar也能执行)
中间还遇到一个问题:
因为代码里写了setParallelism(4),然后使用的又是standalone方式启动任务,然后就报错了:
Caused by: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:607)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
... 33 more
Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.
... 29 more经过测试,把setParallelism(4)去掉就可以了
这里需要测试一下,以yarn的方式,设置多个并行度是否可行,总感觉设置多个并行度是可以的,应该是哪里没配置好
解决了很多问题,终于成功消费到mysql binlog,不容易: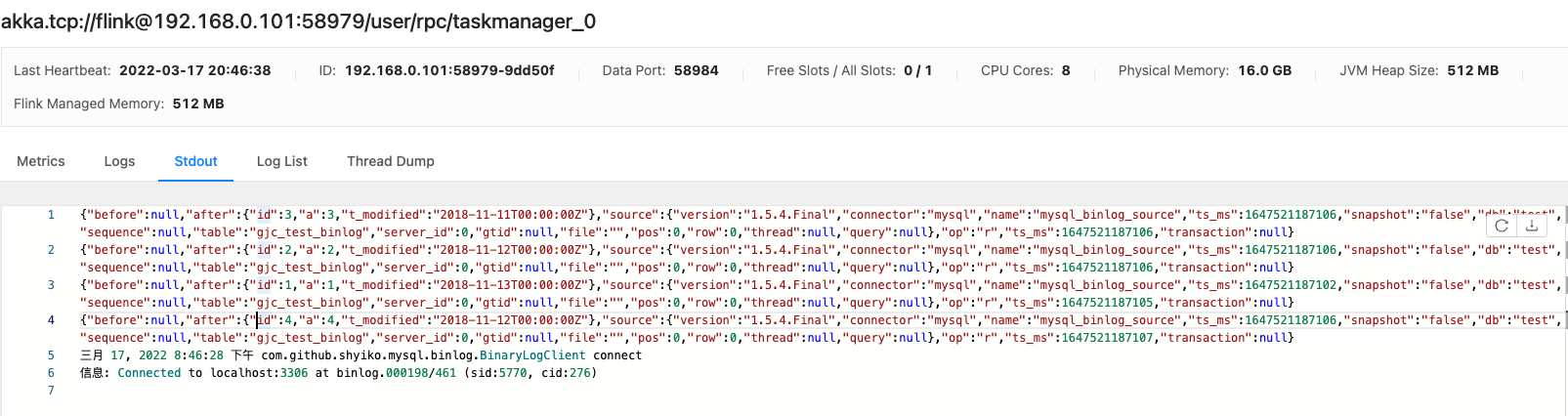
通过FlinkSQL方式编写CDC代码
Java代码在下文 测试采集没有主键的表的位置
这里的pom文件需要好好考虑一下
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- 在idea里执行任务,需要添加下面的依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-client_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>这两个依赖是和其他的依赖是互相冲突的,planner添加provided,kafka的我暂时直接去掉了
这里如果planner不provided,会报如下错误:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: Unable to instantiate java compiler
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132)
Caused by: java.lang.IllegalStateException: Unable to instantiate java compiler
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:428)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.load3(JaninoRelMetadataProvider.java:374)
at org.apache.calcite.rel.metadata.JaninoRelMetadataProvider.lambda$static$0(JaninoRelMetadataProvider.java:109)
at org.apache.flink.calcite.shaded.com.google.common.cache.CacheLoader$FunctionToCacheLoader.load(CacheLoader.java:165)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$LoadingValueReference.loadFuture(LocalCache.java:3529)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$Segment.loadSync(LocalCache.java:2278)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$Segment.lockedGetOrLoad(LocalCache.java:2155)
at org.apache.flink.calcite.shaded.com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2045)Flink 1.10把客户端的ClassLoader解析顺序调整为了Child优先,这就导致用户的Jar包不能包含Flink框架的classes,比如常见的Calcite、Flink-Planner依赖、Hive依赖等等。用户需要把有冲突classes的jar放到flink-home/lib下,或者调整策略为Parent优先
这里参考flink sql包冲突异常
如果不去除kafka的依赖,会报如下错误:
Caused by: java.lang.NoClassDefFoundError: org/apache/kafka/common/utils/ThreadUtils
at com.ververica.cdc.debezium.internal.FlinkOffsetBackingStore.start(FlinkOffsetBackingStore.java:152)
at com.ververica.cdc.debezium.internal.FlinkOffsetBackingStore.configure(FlinkOffsetBackingStore.java:71)
at io.debezium.embedded.EmbeddedEngine.run(EmbeddedEngine.java:690)
at io.debezium.embedded.ConvertingEngineBuilder$2.run(ConvertingEngineBuilder.java:188)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.common.utils.ThreadUtils
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)提交flinkcdc任务到yarn上
添加checkpoint
报错如下:
Caused by: org.apache.flink.util.FlinkRuntimeException: Failed to create checkpoint storage at checkpoint coordinator side.
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.<init>(CheckpointCoordinator.java:325)
Caused by: java.io.IOException: Cannot instantiate file system for URI: hdfs://flink/checkpoint/cdc/gjc_test_Mysql2Kakfa
at org.apache.flink.runtime.fs.hdfs.HadoopFsFactory.create(HadoopFsFactory.java:196)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:526)
Caused by: java.lang.IllegalArgumentException: java.net.UnknownHostException: flink
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:445)
at org.apache.hadoop.hdfs.NameNodeProxiesClient.createProxyWithClientProtocol(NameNodeProxiesClient.java:132)
Caused by: java.net.UnknownHostException: flink
... 34 moreCaused by: java.sql.SQLNonTransientConnectionException: Data source rejected establishment of connection, message from server: "Too many connections"
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:110)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:836)
at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:456)
at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:246)
at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:197)
at com.zaxxer.hikari.util.DriverDataSource.getConnection(DriverDataSource.java:138)
at com.zaxxer.hikari.pool.PoolBase.newConnection(PoolBase.java:364)
貌似flinkcdc没有及时关闭mysql链接,这里把mysql的最大连接数调大了,在my.cnf里添加max_connections = 1000,然后重启mysql服务
Caused by: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeout
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:593)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:577)
... 33 more
Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeout
at org.apache.flink.runtime.jobmaster.slotpool.PhysicalSlotRequestBulkCheckerImpl.lambda$schedulePendingRequestBulkWithTimestampCheck$0(PhysicalSlotRequestBulkCheckerImpl.java:86)
... 26 more
Caused by: java.util.concurrent.TimeoutException: Timeout has occurred: 300000 ms
... 27 more这里乍一看,以为是资源不够,然后我加大资源,换资源队列,最后还是解决不了
最终在网上找到原因,是因为当时方便在idea里测试代码,在pom文件里添加了如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>这里给依赖加上<scope>provided</scope>,或者去掉clients的依赖即可
然后又遇到以下问题:
Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
Diagnostics from YARN: Application application_1640152414594_2461 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1640152414594_2461_000001 exited with exitCode: 1
...
For more detailed output, check the application tracking page: http://ddp2.hadoop:8088/cluster/app/application_1640152414594_2461 Then click on links to logs of each attempt.
. Failing the application.
If log aggregation is enabled on your cluster, use this command to further investigate the issue:
yarn logs -applicationId application_1640152414594_2461通过查看application_1640152414594_2461的日志:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.commons.cli.Option.builder(Ljava/lang/String;)Lorg/apache/commons/cli/Option$Builder;
at org.apache.flink.runtime.entrypoint.parser.CommandLineOptions.<clinit>(CommandLineOptions.java:27)
at org.apache.flink.runtime.entrypoint.DynamicParametersConfigurationParserFactory.options(DynamicParametersConfigurationParserFactory.java:43)
at org.apache.flink.runtime.entrypoint.DynamicParametersConfigurationParserFactory.getOptions(DynamicParametersConfigurationParserFactory.java:50)
at org.apache.flink.runtime.entrypoint.parser.CommandLineParser.parse(CommandLineParser.java:42)
at org.apache.flink.runtime.entrypoint.ClusterEntrypointUtils.parseParametersOrExit(ClusterEntrypointUtils.java:63)
at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(YarnJobClusterEntrypoint.java:89)这里在网上查了以下原因,说是因为缺少commons.cli相关的jar,按照网上的说法,去下载了一个commons-cli的jar包放到${FLINK_HOME}\lib下
但是,还是没有解决这个问题。
最终解决办法:
去掉hadoop相关的依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-common.version}</version>
</dependency>这里的根本原因是,1.11.0版本之后,Flink不用编译flink-shaded包,不需要再把flink-shaded里的flink-shaded-hadoop-XXX.jar放入flink的lib文件夹下了
而是直接通过设置export HADOOP_CLASSPATH=hadoop classpath,但是,这种方式里就已经包含了commons-cli,但是,hadoop-common里也有commons-cli,这就导致版本冲突了
完美的解决方案是:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-common.version}</version>
<exclusions>
<exclusion>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
</exclusion>
</exclusions>
</dependency>原先的依赖不变,但是排除commons-cli,这样就完美解决了
添加断点续传
首先在代码里添加checkpoint相关代码:
//配置ck的状态后端
env.setStateBackend(new HashMapStateBackend());
//设置系统异常退出或人为 Cancel 掉,不删除checkpoint数据
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置checkpoint存储目录
env.getCheckpointConfig().setCheckpointStorage("hdfs://flink/checkpoint/cdc/gjc_test_Mysql2Kakfa");
env.enableCheckpointing(3000);启动任务后,在hdfs上查看checkpoint文件夹:
[root@ddp2 ~]# hadoop fs -ls /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/
Found 3 items
drwxr-xr-x - root supergroup 0 2022-03-19 11:51 /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/chk-27
drwxr-xr-x - root supergroup 0 2022-03-19 11:49 /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/shared
drwxr-xr-x - root supergroup 0 2022-03-19 11:49 /flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/taskowned- 手动取消flink任务
- 重新启动flink,需要注意的是,任务启动的时候,需要指定checkopint地址
${FLINK_HOME}/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 -yqu root.default -ynm gjc_test_flink-cdc-mysql -s hdfs:///flink/checkpoint/cdc/gjc_test_Mysql2Kakfa/f24d4a641988987a47e2b6754b26481d/chk-27 -c com.digiwin.flink.cdc2kafka.Mysql2Kakfa target/FlinkCDCTest-1.0-SNAPSHOT-jar-with-dependencies.jar -hostName ddp5.hadoop -yourPort 3306 -dbName gjc_test -tableName gjc_test.gjc_test_binlog -userName root -password root123456这里注意:-s 需要在jar包之前指定,在jar包之后指定就不生效了
- 在mysql中添加数据
insert into gjc_test_binlog values(8,8,'2018-11-10'); insert into gjc_test_binlog values(9,9,'2018-11-10'); - 在flink监控页面查看日志

可以查看到,数据是从8,9开始的。断点续传测试成功
数据写入Kafka
给flink代码添加KafkaSink
//数据写入kafka
dataStreamSource.addSink(new FlinkKafkaProducer<String>("golden-02:9092",
"test.gjc_test_binlog",
new SimpleStringSchema()))
;设置多个并行度
Flinkcdc任务在standalone模式下(这里只是在一台节点上启动了standalone),设置多并行度,报如下错误:
Caused by: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:607)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
... 33 more
Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.
... 29 more
这是因为,只有一个节点的flink集群,这里只有一个slot,启动不了3个并行度
这种情况在yarn上运行的时候不存在这种问题
测试采集没有主键的表
采集没有主键的表,通过DataStream的方式没找到办法,但是通过StreamTableEnvironment的方式,可以采集
下面是代码:
package com.digiwin.flink.cdc2kafka;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
/**
* 主要测试FlinkCDC采集Mysql,包含断点续传,提交任务到yarn上
*/
public class FlinkSqlMysql2Kakfa {
private static final Logger log = LoggerFactory.getLogger(FlinkSqlMysql2Kakfa.class);
private static String hostName ;
private static int yourPort;
private static String dbName;
private static String tableName;
private static String userName;
private static String password;
public static void main(String[] args) throws Exception {
hostName = "golden-01";
yourPort = 3306;
//dbName = "[a-zA-Z\\d]+_test";
//tableName = "[a-zA-Z\\d]+_test.gjc_test_binlog_[0-9][0-9]";
dbName = "test";
tableName = "test.gjc_test_binlog_noprimary";
userName = "root";
password = "123456";
System.out.println("hostName:" + hostName
+ ",port:" + yourPort
+ ",dbName:" + dbName
+ ",tableName:" + tableName
+ ",userName:" + userName
+ ",password:" + password
);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
tableEnvironment.executeSql(
"CREATE TABLE gjc_test_binlog ( " +
" id INTEGER, " +
" a INTEGER, " +
" t_modified STRING " +
") WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'hostname' = 'golden-01', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = '123456', " +
" 'database-name' = 'test', " +
" 'table-name' = 'gjc_test_binlog_noprimary', " +
" 'scan.incremental.snapshot.enabled'='false'" + //主要是这个参数起的作用
") ");
Table table = tableEnvironment.sqlQuery("select * from gjc_test_binlog");
tableEnvironment.toRetractStream(table, Row.class).print();
env.execute();
}
}主要是通过设置scan.incremental.snapshot.enabled=false来达到这种目的
采集分表分库
dbName = "[a-zA-Z\\d]+_test";
tableName = "[a-zA-Z\\d]+_test.gjc_test_binlog_[0-9][0-9]";把表明和库名改成正则表达式即可,这里没啥问题
修改mysql字段,检查代码兼容性
手动清理mysqlbinlog,测试cdc全量读取数据的能力
这里需要测试一下mysqlbinlog全量读取数据库的能力,因为没有清理binlog的话,就不知道程序里的数据到底是从binlog里获取到的还是从mysql里获取到的
- 手动删除mysql之前的binlog
- 启动任务,测试是否会读取全量数据
- 往mysql里写入新的数据
这里还没测试过,后期手动测试一下看看
多并行度测试的各种问题
- 把flink的并行度设置大于1,然后数据写入kafka,程序跑起来之后,能把存量的数据写入到kafka,但是,在mysql里新增的数据,貌似flinkcdc就不消费了,这种情况在并行度为1的时候没有
- 查看了一下kafka的数据是乱序的
数据写入Hudi
Flink-CDC实时采集Sqlserver入Kafka
在SQLServer上启用CDC
具体可以参考sqlserver开启cdc功能和SQL server 2016 开启CDC功能 捕获变更数据
为了让FlinkCDC从SQL Server表中捕获更改事件,需要用SQL Server管理员权限为要采集的每个表开启一下CDC权限SQL Server管理员通过运行系统存储过程来启用 CDC。 系统存储过程可以使用 SQL Server Management Studio 或 Transact-SQL运行。
先决条件:
- 您是 SQL Server 的 sysadmin 固定服务器角色的成员。
- 您是数据库的 db_owner。
- SQL Server 代理正在运行。
SQL Server CDC 功能仅处理用户创建的表中发生的更改。您不能在 SQL Server 主数据库上启用 CDC。
CDC适用的环境:
- SQL server 2008版本以上的企业版、开发版和评估版中可用;
- 需要开启代理服务(作业)。
- CDC需要业务库之外的额外的磁盘空间。
- CDC的表需要主键或者唯一主键。
CDC的表不能truncate操作,truncate是物理删除数据不能捕获变更的数据。
启用CDC分为两步:
- 对目标数据库启用CDC。
- 对目标表启用CDC。
启动步骤:
- 确保开启SQL server agent服务:
这里这样设置了没有用,需要用下面的方式设置:--若不开启的话会报错: SQLServerAgent is not currently running so it cannot be notified of this action. --解决办法: sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'Agent XPs', 1; GO RECONFIGURE GO
也可以通过图形界面操作:#启用SQL Server代理 sudo /opt/mssql/bin/mssql-conf set sqlagent.enabled true #需要重启服务生效 sudo systemctl restart mssql-server
开始–> [win + R] –> services.msc – 启动SQL server 代理服务。这里实测,如果不开启agent服务,虽然表最终能开启cdc,但是,往表里添加数据等操作,cdc并没有生效

验证agent是否开启:
-- 查看agent状态
EXEC master.dbo.xp_servicecontrol N'QUERYSTATE', N'SQLSERVERAGENT'
-- 结果为running/Stopped,running就正常了- 开启数据库级别的CDC功能:
想要开启表的CDC功能,就必须开启该表所在库的CDC功能
if exists(select 1 from sys.databases where name='ERP' and is_cdc_enabled=0) begin exec sys.sp_cdc_enable_db end --或者 USE test GO -- 开启: EXEC sys.sp_cdc_enable_db -- 关闭: EXEC sys.sp_cdc_disable_db GO --注释: 如果在禁用变更数据捕获时为数据库定义了很多捕获实例,则长时间运行事务可能导致 sys.sp_cdc_disable_db 的执行失败。 --通过在运行 sys.sp_cdc_disable_db 之前使用 sys.sp_cdc_disable_table 禁用单个捕获实例,可以避免此问题。 --示例: USE AdventureWorks2012; GO EXECUTE sys.sp_cdc_disable_table @source_schema = N'HumanResources', @source_name = N'Employee', @capture_instance = N'HumanResources_Employee'; - 查询验证数据是否开启CDC功能:
--若返回的值是0 表示CDC是禁用的,1表示CDC是开启的。 select is_cdc_enabled from sys.databases where name='test'; - 添加CDC专用的文件组和文件:
如果不添加CDC专用的文件组和文件,会报如下错误:-- 查询某个库的物理文件: SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('test'); go ----------------------------- --name physical_name --test /var/opt/mssql/data/test.mdf --test_log /var/opt/mssql/data/test_log.ldf ----------------------------- --1.添加文件组: ALTER DATABASE test ADD FILEGROUP CDC; go ALTER DATABASE test ADD FILE(NAME= 'TEST_CDC',FILENAME = '/var/opt/mssql/data/TEST_CDC.ndf') TO FILEGROUP CDC; go --再次执行SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('test');结果如下: --test /var/opt/mssql/data/test.mdf --test_log /var/opt/mssql/data/test_log.ldf --TEST_CDC /var/opt/mssql/data/TEST_CDC.ndfMsg 22973, Level 16, State 1, Server golden-02, Procedure sys.sp_cdc_enable_table_internal, Line 361 The specified filegroup 'CDC' is not a valid filegroup for database 'test'. Specify a valid existing filegroup or create the named filegroup, and retry the operation. - 开启表级别的CDC:
EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', -- source_schema @source_name = 'table_name', -- table_name @capture_instance = NULL, -- capture_instance @supports_net_changes = 1, -- supports_net_changes @role_name = NULL, -- role_name @index_name = NULL, -- index_name @captured_column_list = NULL, -- captured_column_list @filegroup_name = 'CDC' -- filegroup_name; --由于使用sqlcmd,换行会报错,这里测试的时候都写到一行里: EXEC sys.sp_cdc_enable_table @source_schema = 'dbo',@source_name = 'gjc_test_binlog',@capture_instance = NULL, @supports_net_changes = 1,@role_name = NULL, @index_name = NULL,@captured_column_list = NULL, @filegroup_name = 'CDC';注意: 这里的source_schema = ‘dbo’,schema不是数据库名称
验证cdc成功了没?
select * from test.cdc.dbo_gjc_test_binlog_CT;开启agent服务后,cdc服务正常启动了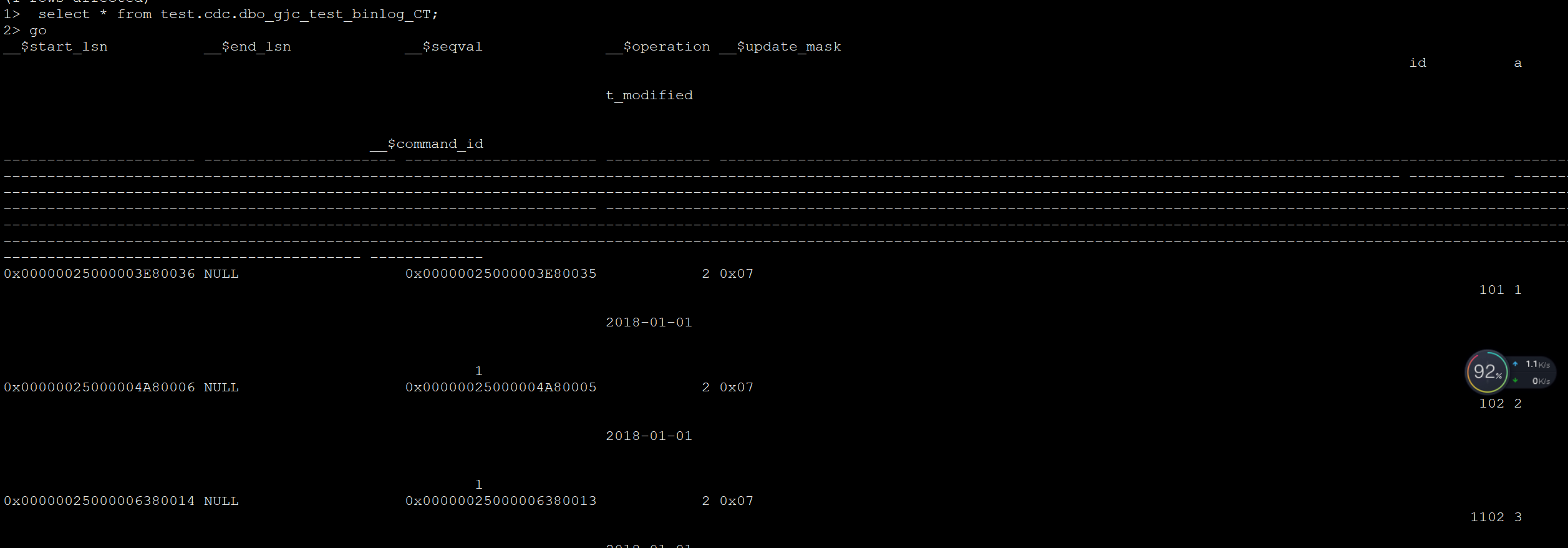
sql-client方式验证flinkcdc读取sqlserver
和mysql一样的操作,首先把cdc的jar放到${FLINK_HOME}/lib下,并开启flink-cluster
CREATE TABLE gjc_test_binlog (
id INT,
a INT,
t_modified STRING
) WITH (
'connector' = 'sqlserver-cdc',
'hostname' = '192.168.233.129',
'port' = '1433',
'username' = 'sa',
'password' = 'Gjc123!@#',
'database-name' = 'test',
'schema-name' = 'dbo',
'table-name' = 'gjc_test_binlog'
);
select * from gjc_test_binlog;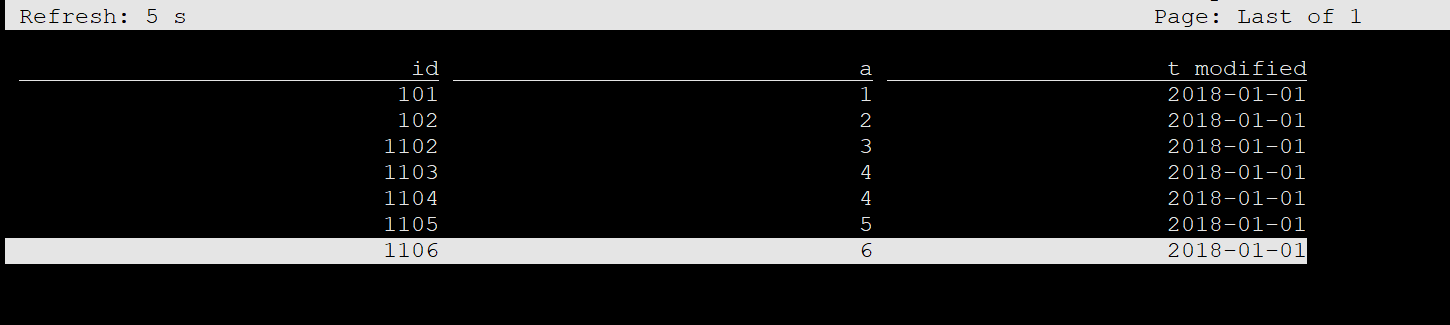
FlinkSQL方式验证flinkcdc读取sqlserver
pom文件添加如下依赖
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-sqlserver-cdc</artifactId>
<version>${cdc.version}</version>
</dependency>JAVA代码如下:
package com.digiwin.flink.cdc2kafka;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 主要测试FlinkCDC采集Mysql,包含断点续传,提交任务到yarn上
*/
public class FlinkSqlServer2Kakfa {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
tenv.executeSql(
"CREATE TABLE gjc_test_binlog ( " +
" id INTEGER, " +
" a INTEGER, " +
" t_modified STRING " +
") WITH ( " +
" 'connector' = 'sqlserver-cdc', " +
" 'hostname' = '192.168.233.129', " +
" 'port' = '1433', " +
" 'username' = 'sa', " +
" 'password' = 'Gjc123!@#', " +
" 'database-name' = 'test', " +
" 'schema-name' = 'dbo', " +
" 'table-name' = 'gjc_test_binlog' " +
") ");
Table table = tenv.sqlQuery("select id,a,t_modified from gjc_test_binlog ");
tenv.toRetractStream(table, Row.class).print();
env.execute();
}
}提交的standalone报如下错:
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: Unable to create a source for reading table 'default_catalog.default_database.gjc_test_binlog'.
Table options are:
'connector'='sqlserver-cdc'
'database-name'='test'
'hostname'='192.168.233.129'
'password'='Gjc123!@#'
'port'='1433'
'schema-name'='dbo'
'table-name'='gjc_test_binlog'
'username'='sa'
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
Caused by: org.apache.flink.table.api.ValidationException: Unable to create a source for reading table 'default_catalog.default_database.gjc_test_binlog'.
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:137)
... 8 more
Caused by: org.apache.flink.table.api.ValidationException: Cannot discover a connector using option: 'connector'='sqlserver-cdc'
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'sqlserver-cdc' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.
Available factory identifiers are:
blackhole
datagen
filesystem
mysql-cdc
print
at org.apache.flink.table.factories.FactoryUtil.discoverFactory(FactoryUtil.java:319)
at org.apache.flink.table.factories.FactoryUtil.enrichNoMatchingConnectorError(FactoryUtil.java:463)
... 34 more
这里很奇怪,在idea里能直接执行,以sqlClient的方式也能正常执行,但是,写java代码就不能执行了
数据库配置已经读取到了,但是,还是报 Unable to create a source for reading table 'default_catalog.default_database.gjc_test_binlog'.
这里开启了sqlserver的angent服务以后,就成功了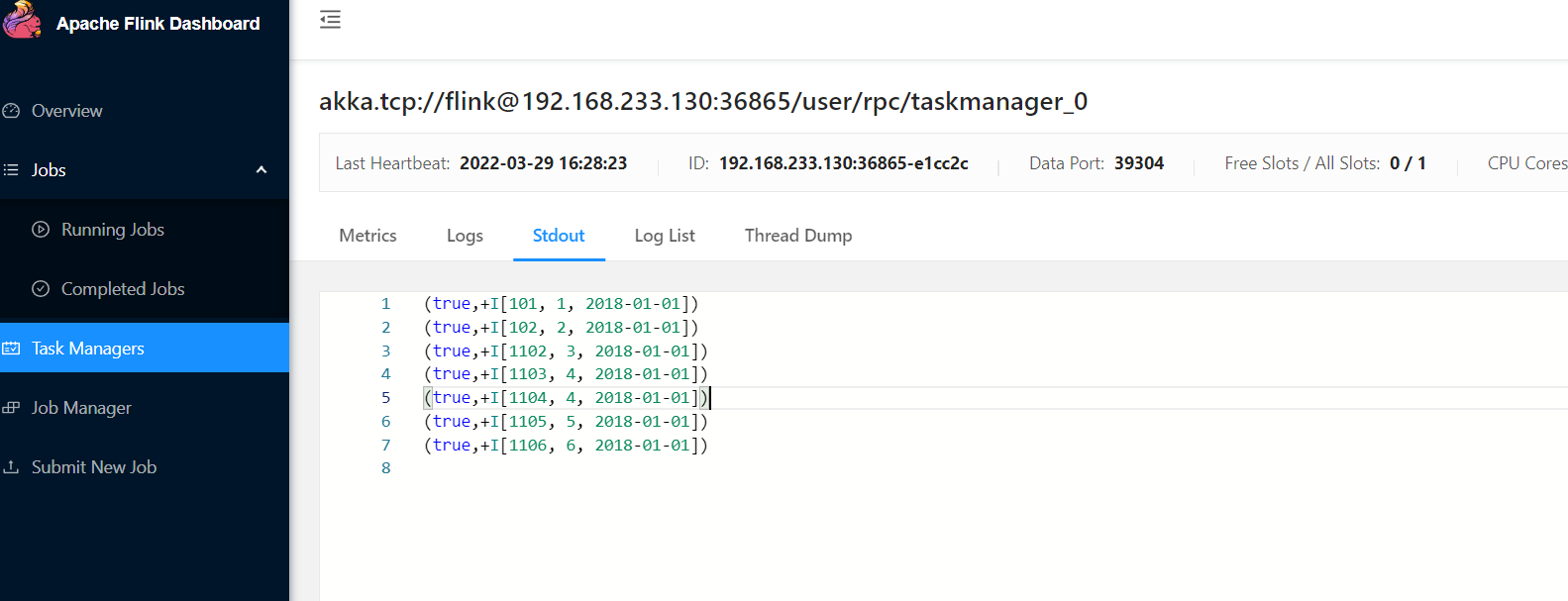
sqlserver中文乱码
ALTER DATABASE SMESPROD COLLATE Chinese_PRC_CI_AS注意
以flinksql方式测试mysql8.0.x,报错
Caused by: org.apache.flink.util.FlinkException: Global failure triggered by OperatorCoordinator for 'Source: TableSourceScan(table=[[default_catalog, default_database, gjc_test_binlog]], fields=[id, a, t_modified]) -> SinkConversionToTuple2 -> Sink: Print to Std. Out' (operator cbc357ccb763df2852fee8c4fc7d55f2). at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder$LazyInitializedCoordinatorContext.failJob(OperatorCoordinatorHolder.java:553) at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$QuiesceableContext.failJob(RecreateOnResetOperatorCoordinator.java:223) at org.apache.flink.runtime.source.coordinator.SourceCoordinatorContext.failJob(SourceCoordinatorContext.java:285) at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:133) at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.applyCall(RecreateOnResetOperatorCoordinator.java:291) at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.start(RecreateOnResetOperatorCoordinator.java:70) ... 13 more Caused by: org.apache.flink.util.FlinkRuntimeException: com.zaxxer.hikari.pool.HikariPool$PoolInitializationException: Failed to initialize pool: Access denied for user 'root'@'localhost' (using password: YES) at com.ververica.cdc.connectors.mysql.debezium.DebeziumUtils.openJdbcConnection(DebeziumUtils.java:65) at com.ververica.cdc.connectors.mysql.MySqlValidator.validate(MySqlValidator.java:68) at com.ververica.cdc.connectors.mysql.source.MySqlSource.createEnumerator(MySqlSource.java:174) at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:129) ... 30 more Caused by: com.zaxxer.hikari.pool.HikariPool$PoolInitializationException: Failed to initialize pool: Access denied for user 'root'@'localhost' (using password: YES) at com.zaxxer.hikari.pool.HikariPool.throwPoolInitializationException(HikariPool.java:596) at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:582) at com.ververica.cdc.connectors.mysql.debezium.DebeziumUtils.openJdbcConnection(DebeziumUtils.java:62) ... 33 more Caused by: java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES) at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:129) at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)但是,明明已经指定了数据库ip等信息,
navicat能连接sqlserver,但是jdbc连接不上sqlserver
根据网上的说法,检查了- SQL Server网络配置 –> TCP/IP已启用
- 再检查windows防火墙,是关闭
- sql server服务属性中,将默认的本账户改为“内置账户
这3种都正常,但是还是不行
最后,把jar包放到虚拟机里执行了一下,竟然成功了,问题就出在了虚拟机与本机的通信上,这里应该选用桥接模式,使用NAT模式就会出现上面的问题
- 驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接。错误:“sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target”。 ClientConnectionId:debbc10a-0619-4955-ad09-d6e35ba5d707
修复完问题2,再次执行flinkcdc程序,发现竟然不能采集了。
报错原因:可能是因为使用的JDBC驱动版本太高,之前使用了mssql-jdbc - 10.2.0.jre8版本,把这里的依赖去掉,直接使用flink-cdc自带的sqlserver依赖,就可以了