本文主要包括:
- flink资源管理
flink资源管理
本文主要讲述flink的资源管理,flink通过yarn申请资源,通过提交的参数,如何计算出整体所消耗的资源
Flink的Slot和并行度
并行度
一个Flink程序由多个任务(Task)组成(source、transformation和 sink)。 一个任务由多个并行的实例(线程)来执行(SubTask), 一个任务的并行实例(线程)数目就被称为该任务的并行度。
Flink中的程序本质上是并行的和分布式的。在执行期间,一个流具有一个或多个流分区,并且每个算子具有一个或多个算子子任务。算子子任务之间彼此独立,并可以在在不同的线程(甚至服务器)中执行,算子的并行度决定了算子子任务数量,同一程序的不同算子可设置不同的并行度。
Slot
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。每个 task slot 代表 TaskManager 中资源的固定子集。
每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。
总结:
- Flink中slot是任务执行所申请资源的最小单元,同一个TaskManager上的所有slot都只是做了内存分离,没有做CPU隔离。
- 每一个TaskManager都是一个JVM进程,如果某个TaskManager 上只有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行,如果有多个 slot 就意味着更多 subtask 共享同一 JVM。
- 一般情况下有多少个subtask,就是有多少个并行线程,而并行执行的subtask要发布到不同的slot中去执行。
- Flink 默认会将能链接的算子尽可能地进行链接,也就是算子链,flink 会将同一个算子链分组内的subtask都发到同一个slot去执行,也就是说一个slot可能要执行多个subtask,即多个线程。
- flink 可以根据需要手动地将各个算子隔离到不同的 slot 中。
- 一个任务所用的总共slot为所有资源隔离组所占用的slot之和,同一个资源隔离组内,按照算子的最大并行度来分配slot。
个人理解,flink的slot就和spark的container类型,类似一个jvm虚拟机,但是它和container的不通指出在于,它只对内存隔离,不对cpu隔离
可以参考Flink 中 slot ,task,并行度的概念以及与CPU,内存的关系
通过提交的参数,如何计算出整体所消耗的资源
这里整理了一下资源数的计算方法,总结来说:
taskmanager个数 = 并行度/slot个数
总内存 = jobmanager的内存 + taskmanager个数*taskmanager内存注意:
参数里的-yjm和-ytm都指的是每个jobmanager/taskmanager的内存,不是整体的内存数
举个例子:
一个Flink作业,设置了20个并行度,10个slot,yjm=1G,ytm=2G,此时需要启动20/10=2个taskmanager进程,同时还需要启动一个jobmanager进程,因此需要启动2+1=3个容器,核数为并行度+1=20+1=21,对应的截图如下
总内存数:1G + 2 * 2G = 5G
flink run -m yarn-cluster -yjm 1024m -ytm 2048m -yqu root.users.service-cloud -ynm warning1.2 -p 3 WarningStreamAnalysisService-1.2.jar这个任务申请了资源为:1G的jobmanager内存,2G的taskmanager内存,3个并行度,slot数没有指定,所以是默认1个
如果要指定slot数,可以使用-ys
所以,这里的taskmanager数为 3/1 = 3个
总内存数为: 1G + 3 * 2G = 7G,整体申请了7G
如何降低flink任务的资源
公司的数据量特别小,但是,每次flink任务的启动,最低都要启动2G的内存,很浪费,这里研究一下如何把任务启动的资源降到最低
首先,公司线上的任务都是提交到yarn上,所以,资源管理这块,需要从yarn和flink本身两个方面来考虑
从flink方面降低资源
通过查找官网,我们知道,Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。 其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)。
配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:
| 配置项 | TaskManager 配置参数 | JobManager 配置参数 |
|---|---|---|
| Flink 总内存 | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| 进程总内存 | taskmanager.memory.process.size | jobmanager.memory.process.size |
其中,有两种内存是可以通过指定在总内存中所占比例的方式进行配置,同时受限于相应的的最大/最小值范围。
- JVM 开销:可以配置占用进程总内存的固定比例
- 网络内存:可以配置占用 Flink 总内存的固定比例(仅针对 TaskManager)
这里需要注意的是,它们不是直接通过总内存的固定比例计算的,还需要和相应的最大值和最小值做比较,这里我们想要降低使用内存,所以需要关心它们的最低内存是多少,参数如下
这里,我们把他们全部设置成0mb## jvm开销 taskmanager.memory.jvm-overhead.min: 192 mb jobmanager.memory.jvm-overhead.min: 192 mb # 网络内存 taskmanager.memory.network.min: 64mb
然后执行一下命令:
${FLINK_HOME}/bin/flink run -m yarn-cluster -yjm 512m -ytm 512m -ynm gjc_test -c com.digiwin.test.FlinkTest FlinkTest-1.0-SNAPSHOT-jar-with-dependencies.jar然后报如下错误:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: TaskManager memory configuration failed: Sum of configured Framework Heap Memory (128.000mb (134217728 bytes)), Framework Off-Heap Memory (128.000mb (134217728 bytes)), Task Off-Heap Memory (0 bytes), Managed Memory (81.920mb (85899346 bytes)) and Network Memory (20.480mb (21474836 bytes)) exceed configured Total Flink Memory (204.800mb (214748364 bytes)).翻译过来就是:主方法导致错误:TaskManager内存配置失败:配置的框架堆内存(128.000mb(134217728字节))、框架堆外内存(128.000mb(134217728字节))、任务堆外内存(0字节)、托管内存(81.920mb(85899346字节))和网络内存(20.480mb(21474836字节))的总和超过配置的Flink内存总量(204.800mb(214748364字节))。
剩下的就是把这几个内存的参数都调整一下就好了:
| 参数名 | 配置参数 | 默认值 |
|---|---|---|
| Framework Heap Memory | taskmanager.memory.framework.heap.size | 128 mb |
| Framework Off-Heap Memory | taskmanager.memory.framework.off-heap.size | 128 mb |
| Task Off-Heap Memory | taskmanager.memory.task.off-heap.size | 0 bytes |
| Managed Memory | taskmanager.memory.managed.size,taskmanager.memory.managed.fraction | (none),(0.4) |
| Network Memory | taskmanager.memory.network.min,taskmanager.memory.network.max,taskmanager.memory.network.fraction | 64 mb/1gb/0.1 |
所以,我们这里需要把以下几个参数调整以下:
taskmanager.memory.framework.heap.size: 32mb
taskmanager.memory.framework.off-heap.size: 32mb这次把tm和jm内存都调整到256m,命令如下:
${FLINK_HOME}/bin/flink run -m yarn-cluster -yjm 256m -ytm 256m -ynm gjc_test -c com.digiwin.test.FlinkTest FlinkTest-1.0-SNAPSHOT-jar-with-dependencies.jar又报如下错误:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: JobManager memory configuration failed: Sum of configured JVM Metaspace (256.000mb (268435456 bytes)) and JVM Overhead (25.600mb (26843546 bytes)) exceed configured Total Process Memory (256.000mb (268435456 bytes)).这里的意思是,主方法导致错误:JobManager内存配置失败:配置的JVM元空间(256.000mb(268435456字节))和JVM开销(25.600mb(26843546字节))的总和超过配置的总进程内存(256.000mb(268435456字节))。
这里主要是JVM Metaspace的内存过大,需要调整以下参数:
jobmanager.memory.jvm-metaspace.size: 64mb
taskmanager.memory.jvm-metaspace.size: 64mb完整的调整参数如下 :
taskmanager.memory.jvm-overhead.min: 0mb
jobmanager.memory.jvm-overhead.min: 0mb
taskmanager.memory.framework.heap.size: 32mb
taskmanager.memory.framework.off-heap.size: 32mb
jobmanager.memory.jvm-metaspace.size: 64mb
taskmanager.memory.jvm-metaspace.size: 64mb通过如上的参数设置完成以后,任务提交到yarn上,可以看到,tm和jm的内存确实降低了,效果如图:
jobmanager的内存使用情况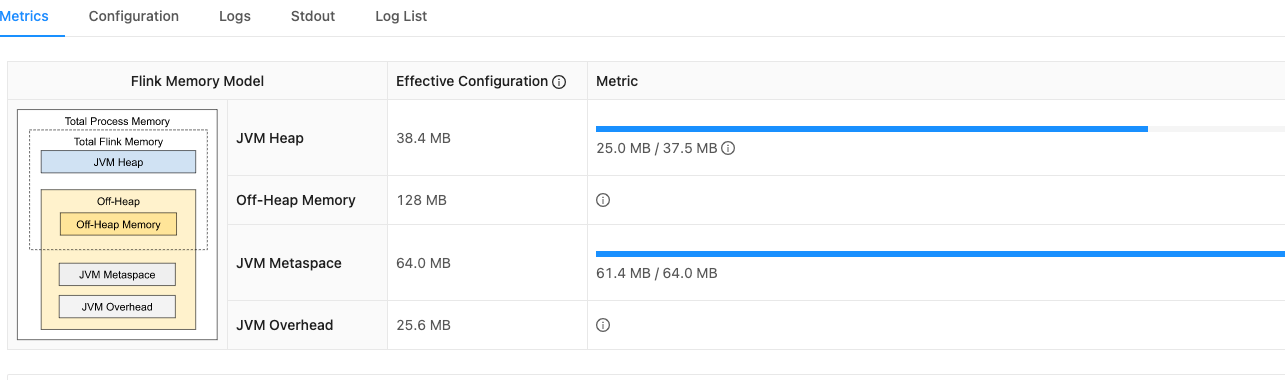
taskmanager的内存使用情况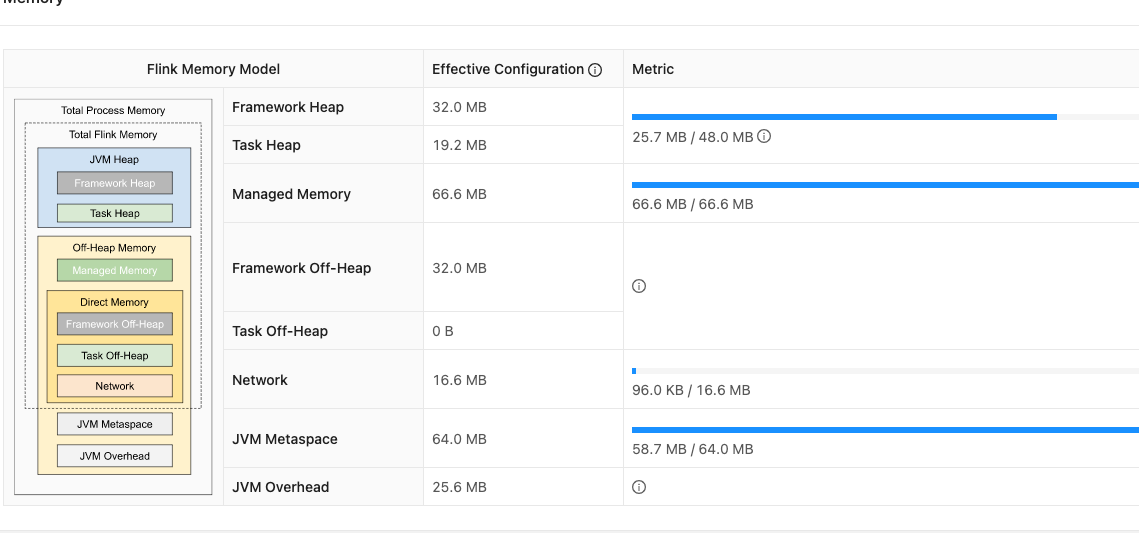
但是yarn上的申请竟然还是2个G,效果如图: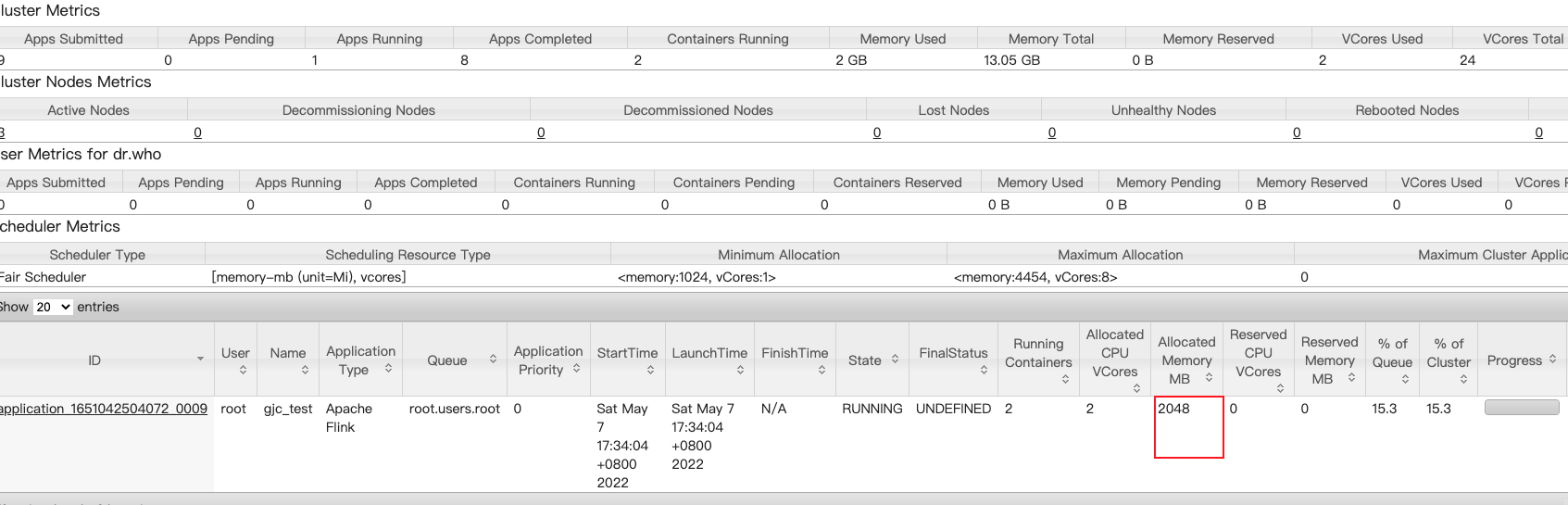
出现这种问题,是因为任务提交到yarn上,资源也会收到yarn的控制,yarn上有参数控制每个container的最小内存,查看当前集群的设置
yarn.scheduler.minimum-allocation-mb = 1024mb;
yarn.scheduler.minimum-allocation-vcores=1;所以,需要再降低一下yarn.scheduler.minimum-allocation-mb
注意: yarn的这两个配置,只能在yarn的配置文件里改,貌似不能通过传惨的方式去设置,试了很多次都不行,后面再留意以下看看
每个任务设置不同的参数提交
- 设置FLINK_CONF_DIR
当前都是再flink-conf.yml里设置的,会导致所有的任务都会使用这些参数,在线上肯定是不能这么设置的,一开始通过提交命令-D和-yD,但是,参数提交不成功,最后在官网找到解决办法
- 在自己的工程目录创建一个 conf 目录
- 复制${FLINK_HOME}/conf/flink-conf.yaml以及log4j.properties/log4j-cli.properties/log4j-console.properties到该目录
- 在执行
flink run之前,先export FLINK_CONF_DIR=${myDir}
完整的提交脚本:export FLINK_CONF_DIR=/root/conf ${FLINK_HOME}/bin/flink run -m yarn-cluster -yjm 256m -ytm 256m -ynm gjc_test -c com.digiwin.test.FlinkTest FlinkTest-1.0-SNAPSHOT-jar-with-dependencies.jar
- 通过命令行参数设置
最终内存优化:flink run -m yarn-cluster -ys 1 -ynm MoreTableCollection -yjm 1G -ytm 3G -yqu yfdl -p 1 -sae -yD env.java.opts="-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 -XX:+UseG1GC" -yD taskmanager.memory.managed.fraction=0.1 -yD taskmanager.memory.task.heap.size=2048m -yD taskmanager.memory.network.fraction=0.05 -yD taskmanager.memory.jvm-overhead.min=10m -yD taskmanager.memory.jvm-overhead.fraction=0.05 -c com.digiwin.ocean.OceanStarter ocean-1.0.jar -shost xxx -sport 1521 xxx
这样优化,可以让Task Heap达到最大,因为每次OOM都是在Task Heap不足,可用于实时采集。其他flink程序,需要看状态大小,适当调整taskmanager.memory.managed.fractionjobmanager.memory.jvm-overhead.min: 10m jobmanager.memory.jvm-metaspace.size: 128m taskmanager.memory.managed.fraction : 0.05 taskmanager.memory.network.fraction : 0.05 taskmanager.memory.jvm-overhead.fraction : 0.05 taskmanager.memory.jvm-overhead.min : 10m taskmanager.memory.framework.heap.size: 32m taskmanager.memory.framework.off-heap.size: 32m taskmanager.memory.jvm-metaspace.size: 128mFlink内存模型
具体可以参考flink官网的内存配置
着重看一下内存配置的taskmanager的内存模型详解 和jobmanager的内存模型详解jobmanager内存模型
jobmanager的内存模型详解在官网的位置:
| 参数名 | 配置参数 | 描述 | 默认值 |
|---|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。 | (none) |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存)。 | 128mb |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 | 256mb |
| JVM 开销 | jobmanager.memory.jvm-overhead.min/max/fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 | 192 mb/1gb/0.1 |
这里举个例子:
提交flink程序的时候,-yjm 256m 代表 flink的jobmananger总内存为256m
在flink-conf.yaml里添加以下参数:
jobmanager.memory.jvm-metaspace.size: 110mb
jobmanager.memory.jvm-overhead.min: 0mb这时候,还有默认的参数没有指定,即jobmanager.memory.jvm-overhead.fraction = 0.1以及jobmanager.memory.off-heap.size=128mb
这时候,程序会自动计算出total memory,
totalMemory = JVM对内存 + 堆外内存,但是,JVM堆内存没有默认值,只有堆外内存128M。所以,这里的totalMemory不应该直接用这两者相加,而应该是:
totalMemory = -yjm 256m - JVM Metaspace - JVM 开销
即 256mb - 110mb(metaspace) - 256*0.1(jvm-overhead) = 120.4
但是,120.4小于堆外内存(128m),所以会报错:
Caused by: org.apache.flink.configuration.IllegalConfigurationException: JobManager memory configuration failed: The configured Total Flink Memory (120.400mb (126248550 bytes)) is less than the configured Off-heap Memory (128.000mb (134217728 bytes)).
at org.apache.flink.runtime.jobmanager.JobManagerProcessUtils.processSpecFromConfigWithNewOptionToInterpretLegacyHeap(JobManagerProcessUtils.java:78)
at org.apache.flink.client.deployment.AbstractContainerizedClusterClientFactory.getClusterSpecification(AbstractContainerizedClusterClientFactory.java:43)taskmanager内存模型
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 其中,Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)、托管内存(Managed Memory)以及其他直接内存(Direct Memory)或本地内存(Native Memory)。
taskmanager的内存模型详解在官网的位置: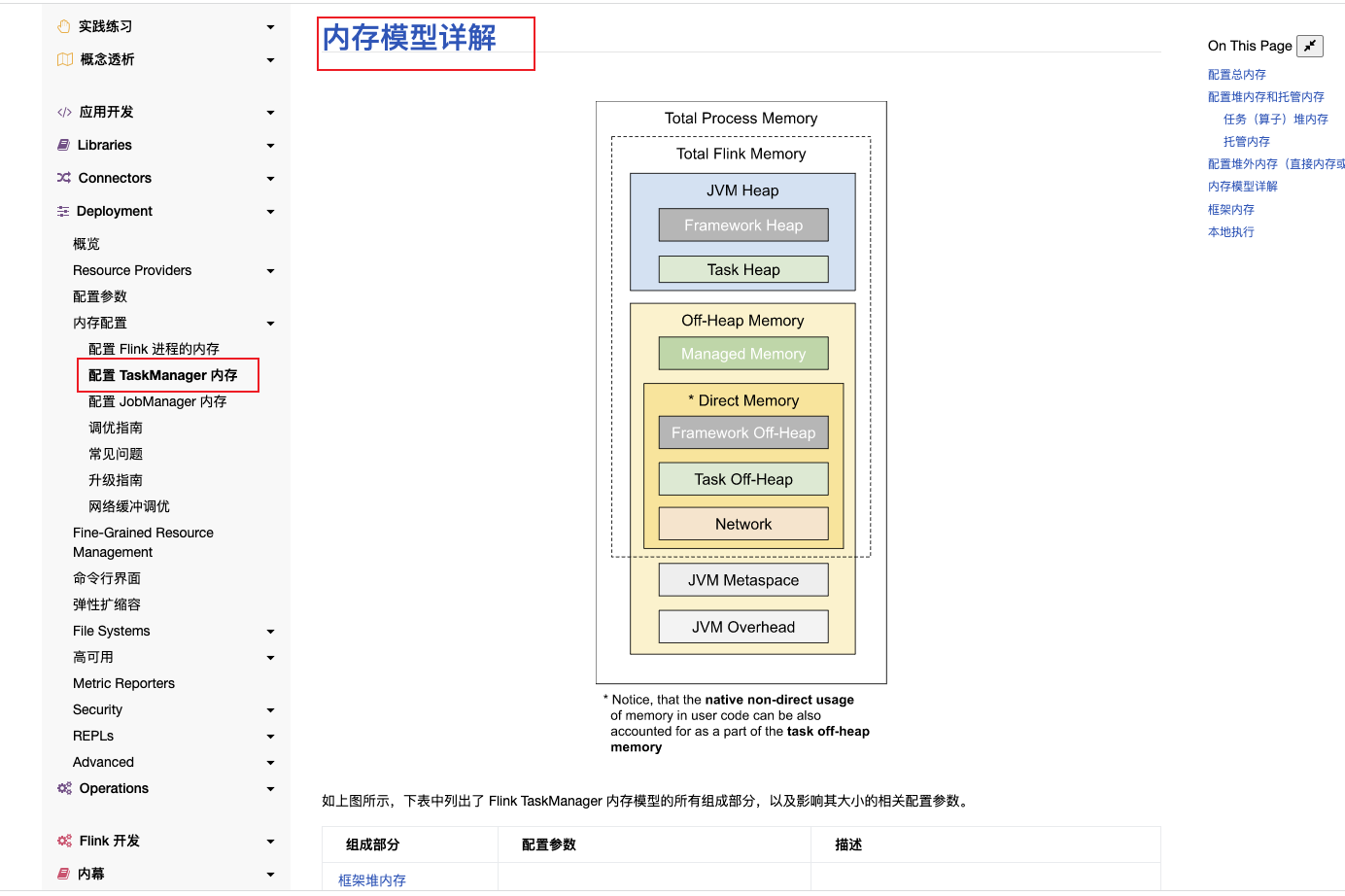
| 参数名 | 配置参数 | 描述 | 默认值 |
|---|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存(进阶配置)。 | 128mb |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存。 | none |
| 托管内存(Managed memory) | taskmanager.memory.managed.size/fraction | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。 | none/0.4 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存)(进阶配置)。 | 128mb |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。 | 0 bytes |
| 网络内存(Network Memory) | taskmanager.memory.network.min/max/fraction | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分。这块内存被用于分配网络缓冲 | 64 mb/1 gb/0.1 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 | 256 mb |
| JVM 开销 | taskmanager.memory.jvm-overhead.min/max/fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 | 192mb/1gb/0.1 |
举个例子:
提交flink程序的时候,-ytm 256m 代表 flink的taskmananger总内存为256m
和jobmanager的内存计算方法一样,taskmanager的totalMemory计算方法应该如下:
totalMemory = 256mb - 128mb(metaspace) - 256*0.1(jvm-overhead) = 102.4mb
然后,内存模型里的networkMem和managedMem的比例都是根据这个totalMemory计算出来的
即networkMem = 102.4 * 0.1 = 10.24m
managedMem = 102.4 * 0.4 = 40.960m
因此,会报如下错误:
Caused by: org.apache.flink.configuration.IllegalConfigurationException: Sum of configured Framework Heap Memory (32.000mb (33554432 bytes)), Framework Off-Heap Memory (32.000mb (33554432 bytes)), Task Off-Heap Memory (0 bytes), Managed Memory (40.960mb (42949673 bytes)) and Network Memory (10.240mb (10737418 bytes)) exceed configured Total Flink Memory (102.400mb (107374182 bytes)).
at org.apache.flink.runtime.util.config.memory.taskmanager.TaskExecutorFlinkMemoryUtils.deriveFromTotalFlinkMemory(TaskExecutorFlinkMemoryUtils.java:178)Flink内存调优
找到taskmanager的java进程id
ps -ef | grep flinkjmap -heap 152481
jmap -histo:live 152481 | more