本文主要包括:
- clickhouse学习笔记
clickhouse简介
clickhouse架构
clickhouse安装与配置
略,可以参考[clickhouse安装与配置][1]
clickhouse客户端命令
连接命令
clickhouse-client --host=xxxx --port=9123 --user=default --password=root123456
# --host, -h – 服务端的 host 名称, 默认是 'localhost'。 您可以选择使⽤ host 名称或者 IPv4 或 IPv6 地址。
# --port – 连接的端⼝,默认值: 9000。注意 HTTP 接⼝以及 TCP 原⽣接⼝是使⽤不同端⼝的。
# --user, -u – ⽤户名。 默认值: default。
# --password – 密码。 默认值: 空字符串。
# --query, -q – ⾮交互模式下的查询语句.
# --database, -d – 默认当前操作的数据库. 默认值: 服务端默认的配置 (默认是 default )。
# --multiline, -m – 如果指定,允许多⾏语句查询(Enter 仅代表换⾏,不代表查询语句完结)。
# --multiquery, -n – 如果指定, 允许处理⽤逗号分隔的多个查询,只在⾮交互模式下⽣效。
# --format, -f – 使⽤指定的默认格式输出结果。
# --vertical, -E – 如果指定,默认情况下使⽤垂直格式输出结果。这与 '--format=Vertical' 相同。在这种格式中,每个值都在单独的⾏上打印,这种⽅式对显示宽表很有帮助。
# --time, -t – 如果指定,⾮交互模式下会打印查询执⾏的时间到 'stderr' 中。
# --stacktrace – 如果指定,如果出现异常,会打印堆栈跟踪信息。
# -config-file – 配置⽂件的名称。具体可以参考clickhouse客户端命令
SQL语法
-- 查看数据库列表
show databases;
--查看当前使用的数据库
select currentDatabase();
-- 查看数据库中表列表
show tables;
-- 创建数据库
create database test;
-- 创建一个表(建表的时候指定数据类型,建表的时候一定要指定表引擎,要么使用-m,要么使用反斜杠,不然不能写多行)
create table if not exists test.t1 ( id UInt16,name String) ENGINE = MergeTree;
-- 查看表结构
desc test.t1;
--删除表
drop table if exists test.t1;
--删除库
drop database test;
--清空数据
truncate table test.t1;
--插入数据
insert into test.t1 (id, name) values (1, 'zhangsan'), (2, 'lishi');
--查询
select * from test.t1;
--重命名表
rename table tab1 to tab2;
--添加列
alter table tbl add column cost UInt32 default 0;
--查看分区信息
select partition, name, active from system.parts WHERE table = 't1';
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]- 建表的时候指定数据类型,建表的时候一定要指定表引擎
- 如果想写多行,要么使用-m,要么使用反斜杠
删除分区
--删除分区
alter table xxx drop partition '2018-08-08';默认情况下,Clickhouse 不允许删除分区或表的大小大于 50GB 的分区或表。可以通过修改server的配置文件来永久配置,也可以临时设置一下来删除而不用重启服务。
永久配置:更改config.xml配置文件。
<!-- <max_table_size_to_drop>0</max_table_size_to_drop> -->
<!-- <max_partition_size_to_drop>0</max_partition_size_to_drop> -->0表示不限制,或者你可以设置为你想限制的最大的大小。
flinksql写数据到clickhouse
由于flink的官网没有实现flink-connector-clickhosue,这里需要自己实现
在github上找到一个现成的,实际测试了一把,发现可以正常使用,项目地址在flink-connector-clickhosue
实现步骤:
# clone源代码到本地,并编译代码,我们的flink版本是1.13.6,这里指定代码版本
git clone https://github.com/gujincheng/flink-connector-clickhouse.git -b release-1.13
cd flink-connector-clickhouse && mvn clean packageflinkcdc采集mysql并写入clickhouse
使用sql-client
- 首先把编译的connector的jar放到${FLINK_HOME}/lib下
mv target/flink-connector-clickhouse-1.13.2-SNAPSHOT.jar /opt/soft/flink-1.13.6/lib - 启动flink-standalone,并启动sql-client
- 执行sql语句
实现效果:set sql-client.execution.result-mode=tableau; set execution.checkpointing.interval=3sec; CREATE TABLE users_source_mysql ( uuid string , name STRING, age int, ts timestamp(3), part string ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '150.158.190.192', 'port' = '3306', 'username' = 'root', 'password' = 'Gjc123!@#', 'server-time-zone' = 'Asia/Shanghai', 'debezium.snapshot.mode' = 'initial', 'database-name' = 'test', 'table-name' = 'users_source_mysql' ); CREATE TABLE if not exists gjc_test_binlog ( uuid string primary key , name STRING, age int, ts timestamp(3), part string ) WITH ( 'connector' = 'clickhouse', 'url' = 'clickhouse://xxxx:8123', 'username' = 'default', 'password' = 'root123456', 'database-name' = 'default', 'table-name' = 'gjc_test_binlog', 'sink.batch-size' = '1000', 'sink.max-retries' = '3', 'sink.partition-strategy' = 'balanced', 'sink.ignore-delete' = 'true' ); insert into gjc_test_binlog select uuid,name,age,ts,part from users_source_mysql;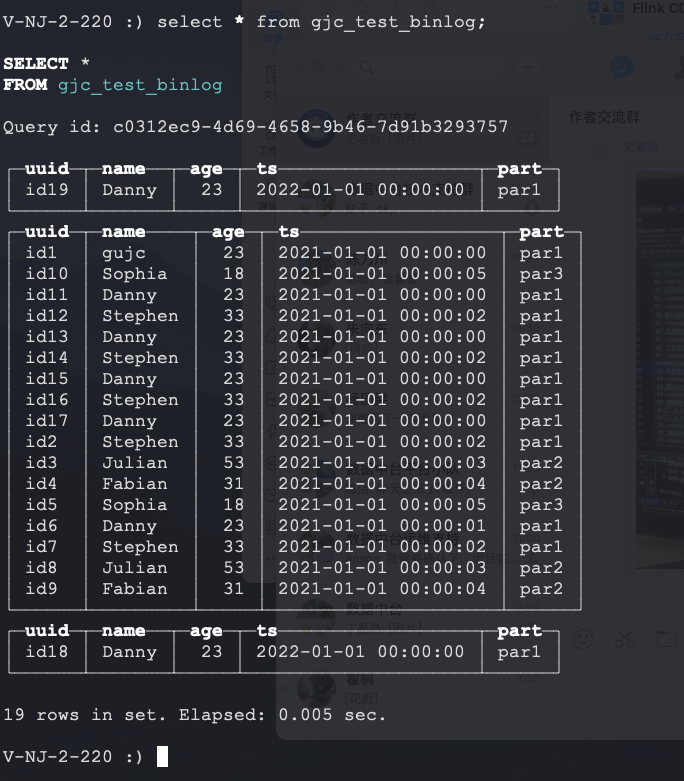
注意:
这里在测试数据的增删改查过程中,针对修改与删除数据,总结以下几点:
- clickhouse必须有主键才能支持修改和删除数据
- 如果clickhouse表是分区表,那么在flinksql中创建的映射表也必须要有分区,否则,修改操作会不生效