本文主要包括:
- Centos7.x安装Oracle12c
- 初尝Oracle遇到的坑
- Ocacle基本操作
- Oracle开启CDC功能
Centos7.x安装Oracle12c
这里安装完全参考了CENTOS7.3静默安装ORACLE12C
需要注意的是
- 在配置ORACLE环境变量并验证–需要把
export ORACLE_HOSTNAME=liuxiaobai改成自己的 - 安装ORACLE–这里采取命令行安装,文档里的
\换行不对,这里全部放到一行里成功了 - 创建数据库–
-gdbname需要改成-gdbName,换行去掉,都放在一行 - 配置数据库监听 ,这里看初尝Oracle遇到的坑
启动Oracle
# 进入oracle用户
su - oracle
# 进入sqlplus
sqlplus / as sysdba
# startup 数据库
startup
# 查看数据库中pdb列表:
show pdbs;
# 可以看到,默认是MOUNTED,需要手动打开
alter pluggable database all open;
# 再次查看状态
show pdbs;
# 退出sqlplus
exit
# 启动监听
lsnrctl start初尝Oracle遇到的坑
配置数据库监听
未配置监听前执行
lsnrctl status
## 因为没配置过,所以会报错,具体日志看参考文档使用默认的netca.rsp文件,执行命令
netca -silent -responseFile /home/oracle/database/response/netca.rsp这里执行命令以后,没有出现文档里成功的日志,通过查看日志,报错如下:
为此监听程序提供的端口1521当前正在使用。可以按现状继续配置,但只有在解决冲突之后才能启动该监听程序。是否仍然继续配置?网上说是因为host配置不对,我这里通过lsnrctl stop把监听停掉,然后手动执行
/usr/local/products/oracle12c/bin/lsnrctl start LISTENER这样虽然报日志成功了,但是并没有文档里说的会对服务cdb1监听的日志,这里根据文档里提示,修改listener.ora文件
vim /usr/local/products/oracle12c/network/admin/listener.ora
## 文件内容修改如下:
# listener.ora Network Configuration File: /usr/local/products/oracle12c/network/admin/listener.ora
# Generated by Oracle configuration tools.
## 这里不动
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = golden-cloud)(PORT = 1539))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
)
## 以下为新增
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = orcl)
(SID_NAME = orcl)
)
(SID_DESC =
(GLOBAL_DBNAME = orclpdb1)
(SID_NAME = orclpdb1)
)
)
注意:
这里的监听需要开启2个,一个是CDB一个是PDB,否则flink连接的时候,会有问题
再次执行:
lsnrctl stop
lsnrctl start终于成功了
使用navicat连接oracle
首先在腾讯云开启端口,这次安装的端口换成1539了。
这里要注意,Service Name和SID都是一样的,都是之前创建的数据库cdb1,选哪个都可以的
密码就是之前-systemPassword的内容,连接界面如下: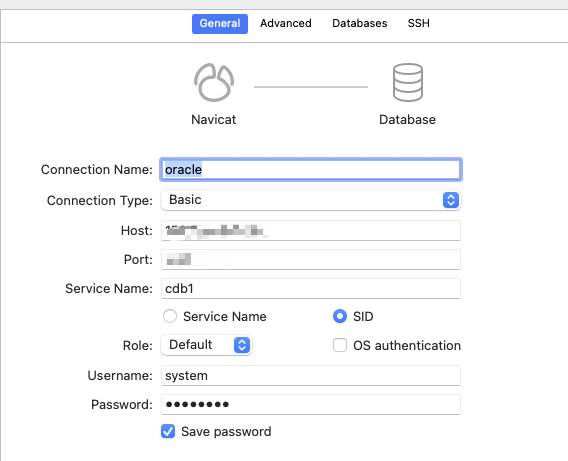
还需要注意的是,通过第三方工具连接,必须要开启监听服务,否则连不上的
创建用户失败
主要有2个问题:
- 用户名不合法,具体可以参考ORA-65096: 公用用户名或角色名无效
- 找不到表命名空间
不管是在sqlplus还是在Navicat创建都报错,大致的意思就是用户名不合法,通过网上的资料查看,oracle12版本,普通用户名必须要以c##开头
找不到表命名空间的解决办法就是重启oracle服务:
# 1. su – oralce —-切换到oracle用户
# 2.lsnrctl stop —-停止监听
# 3.sqlplus /as sysdba —-以sysdba用户登录oracle
# 4.shutdown immediate —-关闭数据库
# 5.startup —-启动数据库
# 6.exit —-退出sqlplus
# 7.lsnrctl start —-启动监听
# 3,4,5是在sqlplus里执行的重启过后就可以找到命名空间了
通过sqlplus创建命名空间与用户的语句如下:
create tablespace testspace datafile '/usr/local/products/oradata/testspace.dbf' size 300m;
--创建用户名
CREATE USER c##test IDENTIFIED BY 123456 DEFAULT TABLESPACE "golden" TEMPORARY TABLESPACE TEMP;
-- 查看用户名与其默认的表空间
select username, default_tablespace from dba_users where username = 'C##TEST'但是还是感觉使用navicat来创建更方便
如果想要用新创建的用户登陆,需要给新用户授权:
--这个在navicat里也可以操作
grant connect, resource to c##test; // 用户授权ORA-01950: 对表空间 ‘golden’ 无权限
以新用户登陆oracle,并创建表都没有问题,但是,往表里写数据的时候,报错:
ORA-01950: 对表空间 'golden' 无权限需要再次赋权:
ALTER USER C##TEST QUOTA UNLIMITED ON "golden"Ocacle基本操作
这里操作Oracle都在Navicat里操作,通过命令行操作Oracle,太费事了
schema是什么?可以参考oracle之schema
schema和用户是一一对应的。每个用户都有一个schema,并且和用户名是一样的
数据库的启动步骤:
- nomount –根据参数文件启动实例(instance)
- mount –加载控制文件,让实例和数据库相关联
- open –根据控制文件找到并打开数据文件和日志文件,从而打开数据库
Oracle开启CDC功能
您必须为 Oracle 数据库启用日志归档,并定义一个对 Debezium Oracle 连接器监控的所有数据库具有适当权限的 Oracle 用户
Oracle启用日志归档,根据数据库类型有2种方式
对于Non-CDB database
Non-CDB概念:
Non-CDB 是指任何不是 CDB 的东西。即 12c 之前的任何数据库,或在没有启用可插入数据库子句的情况下创建的 12c 数据库。如果您创建非 CDB,则它不是 Multitentant,而是像 12c 之前的数据库一样的单实例独立数据库。
看网上的说法,12C之前的版本都是Non-CDB,12C之后的版本,都是CDB的
那么,我们这次采集的目标是12C,所以是CDB版本的
查询Oracle数据库是CDB还是Non-CDB?
您可以在V$DATABASE视图中查询 CDB 列以查看数据库是否为 CDB。如果当前数据库是 CDB,则列值为 YES,否则 CDB 列值为 NO
SQL> SELECT CDB FROM V$DATABASE;
CDB
------
YES
--您可以通过如下查询获取有关 CDB 中容器的信息。
--使用 SQLPlus 连接,确保您位于根容器中,然后运行查询。
SQL> SHOW CON_NAME;
CON_NAME
------------------------------
CDB$ROOT
SQL> COLUMN NAME FORMAT A8;
SQL> SELECT NAME, CON_ID, DBID, CON_UID, GUID FROM V$CONTAINERS ORDER BY CON_ID;
NAME CON_ID DBID CON_UID GUID
-------- ---------- ---------- ---------- --------------------------------
CDB$ROOT 1 1081227694 1 4700A987085A3DFAE05387E5E50A8C7B
PDB$SEED 2 4250516830 4250516830 E187C82E49CD2E91E055000000000001
PDB1 3 913056142 913056142 E187D563EBD3375EE055000000000001可以看到,我们的版本确实是CDB的
CDB与PDB区别
Oracle 12C引⼊了CDB与PDB的新特性,在ORACLE 12C数据库引⼊的多租⽤户环境(Multitenant Environment)中,允许⼀个数据库容
器(CDB)承载多个可插拔数据库(PDB)。CDB全称为Container Database,中⽂翻译为数据库容器,PDB全称为Pluggable
Database,即可插拔数据库。在ORACLE 12C之前,实例与数据库是⼀对⼀或多对⼀关系(RAC):即⼀个实例只能与⼀个数据库相关
联,数据库可以被多个实例所加载。⽽实例与数据库不可能是⼀对多的关系。当进⼊ORACLE 12C后,实例与数据库可以是⼀对多的关
系。
公共用户与本地用户
公共用户需要以C##开头
具体可以参考Oracle 12C R2 公共用户和本地用户
如果想创建非C##开头的用户名,可以设置
alter session set "_ORACLE_SCRIPT"=true;
数据库开启CDC功能
flinkcdc是通过读取Oracle的日志来做到实时采集的,所以,这里需要了解一下Oracle的日志相关知识
具体可以参考Oracle数据库开启归档日志和补充日志
Oracle开启cdc功能,根据数据库类型有CDB数据库和Non-CDB数据库两种,Non-CDB数据库比较好操作,但是,CDB数据库创建用户必须要用C##开头,导致赋权限一直报错,而且,flinksql连接不到数据库
这里先使用Non-CDB数据库做测试。
有点奇怪,为什么flinkcdc官网上创建
CDB数据库的用户不需要使用C##开头?
Non-CDB数据库开启cdc
- 启用日志归档
mkdir -p /data/oracle/oradata/recovery_area chown -R oracle:dba /data/oracle/oradata/recovery_area CONNECT sys/Oracle123 AS SYSDBA
注意:alter system set db_recovery_file_dest_size = 60G; alter system set db_recovery_file_dest = '/opt/soft/oracle12c/oradata/oradb/archive_log' scope=spfile; shutdown immediate; startup mount; alter database archivelog; alter database open; -- 检查是否启用了日志归档 -- Should now "Database log mode: Archive Mode" archive log list; - 启用日志归档需要重启数据库,尝试时注意
- 归档日志会占用大量磁盘空间,建议定期清理过期日志
- 必须为捕获的表或数据库启用补充日志记录,以便数据更改捕获已更改数据库行的之前状态
-- 为特定表启用补充日志记录:
ALTER TABLE flinkuser.GJC_TEST_CDC ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-- 为数据库启用补充日志记录
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; - 创建用户并赋权限
-- Create Tablespace CREATE TABLESPACE logminer_tbs DATAFILE '/data/oracle/oradata/orcl/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS; GRANT CREATE SESSION TO flinkuser; GRANT SET CONTAINER TO flinkuser; GRANT SELECT ON V_$DATABASE to flinkuser; GRANT FLASHBACK ANY TABLE TO flinkuser; GRANT SELECT ANY TABLE TO flinkuser; GRANT SELECT_CATALOG_ROLE TO flinkuser; GRANT EXECUTE_CATALOG_ROLE TO flinkuser; GRANT SELECT ANY TRANSACTION TO flinkuser; GRANT LOGMINING TO flinkuser; GRANT CREATE TABLE TO flinkuser; GRANT LOCK ANY TABLE TO flinkuser; GRANT ALTER ANY TABLE TO flinkuser; GRANT CREATE SEQUENCE TO flinkuser; GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser; GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser; GRANT SELECT ON V_$LOG TO flinkuser; GRANT SELECT ON V_$LOG_HISTORY TO flinkuser; GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser; GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser; GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser; GRANT SELECT ON V_$LOGFILE TO flinkuser; GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser; GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser; - 在Navicat里创建Oracle表,并插入几条数据
- 在sql-client创建表映射
遇到的问题:-- 注意,这里的字段名需要和oracle里保持一样,区分大小写的 CREATE TABLE gjc_test_oracle ( id INT, name STRING, age INT, PRIMARY KEY(id) NOT ENFORCED ) WITH ( 'connector' = 'oracle-cdc', 'hostname' = 'xxxx', 'port' = '1521', 'username' = 'flinkuser', 'password' = 'flinkpw', 'database-name' = 'orcl', 'schema-name' = 'FLINKUSER', 'table-name' = 'GJC_TEST_CDC' ); select * from gjc_test_oracle;
- 一开始Oracle字段是小写的,但是,flinksql里创建的字段是大写的,导致数据能够识别到(日志里能看到有几条记录),但是控制台没有数据输出(其实是字段名映射不上去)
- flinkcdc可以正常采集没有主键的表,增删改查都可以
CDB数据库开启cdc
- 启用日志归档
sqlplus /nolog CONNECT sys/password AS SYSDBA alter system set db_recovery_file_dest_size = 10G; -- should exist alter system set db_recovery_file_dest = '/opt/soft/oracle12c/oradata/recovery_area' scope=spfile; alter system set archive_lag_target=600 scope=both; --解决ORA-04036: 实例使用的 PGA 内存超出 PGA_AGGREGATE_LIMIT shutdown immediate startup mount alter database archivelog; alter database open; -- Should show "Database log mode: Archive Mode" archive log list exit; - 创建用户并赋权限
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/soft/oracle12c/oradata/orcl/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS; GRANT CREATE SESSION TO flinkuser CONTAINER=ALL; GRANT SET CONTAINER TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$DATABASE to flinkuser CONTAINER=ALL; GRANT FLASHBACK ANY TABLE TO flinkuser CONTAINER=ALL; GRANT SELECT ANY TABLE TO flinkuser CONTAINER=ALL; GRANT SELECT_CATALOG_ROLE TO flinkuser CONTAINER=ALL; GRANT EXECUTE_CATALOG_ROLE TO flinkuser CONTAINER=ALL; GRANT SELECT ANY TRANSACTION TO flinkuser CONTAINER=ALL; GRANT LOGMINING TO flinkuser CONTAINER=ALL; GRANT CREATE TABLE TO flinkuser CONTAINER=ALL; GRANT LOCK ANY TABLE TO flinkuser CONTAINER=ALL; GRANT CREATE SEQUENCE TO flinkuser CONTAINER=ALL; GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser CONTAINER=ALL; GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$LOG TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$LOG_HISTORY TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$LOGFILE TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser CONTAINER=ALL; GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser CONTAINER=ALL;CREATE TABLE gjc_test_oracle ( id INT, name STRING, PRIMARY KEY(id) NOT ENFORCED ) WITH ( 'connector' = 'oracle-cdc', 'hostname' = 'xxxx', 'port' = '1521', 'username' = 'c##flinkuser', 'password' = 'dbz', 'database-name' = 'orcl', 'schema-name' = 'C##FLINKUSER', 'table-name' = 'GJC_TEST_CDC', 'debezium.log.mining.strategy' = 'online_catalog', 'debezium.log.mining.continuous.mine' = 'true' );
遇到的问题:
- cdb默认创建普通用户需要c##开头,如果实在不想c##开头,可以通过设置
alter session set "_ORACLE_SCRIPT"=true;后再创建用户 - 创建c##用户,再flinksql中也是可以正常使用的,这个没什么关系,只是名字看起来别扭
- 默认pdb未启动,需手动启动pdb,不启动pdb,会报如下错误
启动pdb命令:Sink: Collect table sink (1/1)#1 (2663b9a93aca6d06f44204c23b976492) switched from RUNNING to FAILED with failure cause: com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.ConnectException: An exception occurred in the change event producer. This connector will be stopped. at io.debezium.pipeline.ErrorHandler.setProducerThrowable(ErrorHandler.java:42) at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:208) at io.debezium.pipeline.ChangeEventSourceCoordinator.streamEvents(ChangeEventSourceCoordinator.java:152) at io.debezium.pipeline.ChangeEventSourceCoordinator.lambda$start$0(ChangeEventSourceCoordinator.java:119) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.sql.SQLException: ORA-65024: 可插入数据库 未打开。 ORA-06512: 在 "SYS.DBMS_LOGMNR_INTERNAL", line 7750 ORA-06512: 在 "SYS.DBMS_LOGMNR_INTERNAL", line 4812 ORA-06512: 在 "SYS.DBMS_LOGMNR_INTERNAL", line 4999 ORA-06512: 在 "SYS.DBMS_LOGMNR_INTERNAL", line 7601 ORA-06512: 在 "SYS.DBMS_LOGMNR_INTERNAL", line 7764 ORA-06512: 在 "SYS.DBMS_LOGMNR_INTERNAL", line 7920 ORA-06512: 在 "SYS.DBMS_LOGMNR_D", line 12 ORA-06512: 在 line 1
然后再在flink的sql-client里执行命令,就可以正常读取oracle数据了,数据增删改查也都可以看到--查看数据库中pdb列表: show pdbs; -- CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- -- 2 PDB$SEED READ ONLY NO -- 3 DGWORCL MOUNTED -- 可以看到,默认是MOUNTED,需要手动打开 alter pluggable database all open; --报错:Warning: PDB altered with errors.,这个是因为PDB$SEED --再次查看状态 show pdbs; -- CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- -- 2 PDB$SEED READ ONLY NO -- 3 DGWORCL READ WRITE YES
flinkcdc采集oracle数据延迟大
官网给出解决方案:
在flinksql中加入以下参数:
'debezium.log.mining.strategy' = 'online_catalog',
'debezium.log.mining.continuous.mine' = 'true'oracle-cdc会调用一个checkpoint的锁,如果checkpoint频率很慢,就会导致数据有延迟,如果想要降低数据延迟,最好是降低ck时间
实际测试,在PDB方式的数据库,可以正常执行,并且,速度明显加快,但是,在CDB数据库,会报如下错误:
com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.ConnectException: An exception occurred in the change event producer. This connector will be stopped.
at io.debezium.pipeline.ErrorHandler.setProducerThrowable(ErrorHandler.java:42) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1]
at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:208) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1]
at io.debezium.pipeline.ChangeEventSourceCoordinator.streamEvents(ChangeEventSourceCoordinator.java:152) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1]
at io.debezium.pipeline.ChangeEventSourceCoordinator.lambda$start$0(ChangeEventSourceCoordinator.java:119) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_291]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_291]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_291]
Caused by: java.sql.SQLException: ORA-01435: 用户不存在
ORA-06512: 在 "SYS.DBMS_LOGMNR", line 58
ORA-06512: 在 line 1为啥会报用户名不存在呢?而且,快照数据已经读取到了,数据能够正常输出的
问题原因:
在CDB内创建用户分配表空间时,所分配的表空间必须在PDB和CDB中同时存在,否则会报错。如果是在PDB与CDB有相同表空间的情况下给CDB用户分配表空间,则会分配CDB的表空间,给用户PDB的表空间并不受影响。所以要在PDB内创建相同的表空间,然后再回CDB创建用户这里在官网上其实是创建了2个相同的命名空间,但是,在测试的时候,把pdb的命名空间给忽略了,导致一直报错,正确的操作方法:
sqlplus / as sysdba
CREATE TABLESPACE logminer_tbs DATAFILE '/usr/local/products/oradata/orcl/logminer_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
-- 这里切换到pdb下,使用官网的方式,直接使用sqlplus sys/OraPasswd1@//150.158.190.192:1539/ORCLPDB1 as sysdba ,连接不进去,交互式输入用户名密码,其实连接还是CDB
-- 切换容器 这里需要权限
alter session set container = ORCLPDB1;
--在PDB下创建相同的表空间,并且,路径要和CDB的不一样
CREATE TABLESPACE logminer_tbs DATAFILE '/usr/local/products/oradata/orcl/orclpdb1/logminer_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
-- 然后再去创建用户名,给用户赋权报错:ORA-00257: archiver error. Connect internal only, until freed。
flink程序报错ORA-00257: archiver error. Connect internal only, until freed。
该错误是由于归档日志满了,造成的。
查看了下V$FLASH_RECOVERY_AREA_USAGE,看看归档目录使用的情况。果然是归档满了。
SELECT * FROM V$FLASH_RECOVERY_AREA_USAGE;
FILE_TYPE PERCENT_SPACE_USED PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES
------------ ------------------ ------------------------- ---------------
CONTROLFILE 0 0 0
ONLINELOG 0 0 0
ARCHIVELOG 99.9 0 255
BACKUPPIECE 0 0 0
IMAGECOPY 0 0 0
FLASHBACKLOG 0 0 0注:可以看出,ARCHIVELOG日志已经达到99.9%了。造成归档满的原因是因为有一个用户在做大量更新操作,由于更新操作产生大量重做日志,
归档日志切换频繁。解决方法是要把大量归档日志清除掉!
有两种方式可以解决该问题。
一使用RMAN清除归档日志。
二修改闪回恢复区的大小DB_RECOVERY_FILE_DEST_SIZE。
- 第一种使用RMAN清除归档日志。
删除以后再次查看使用率,正常了rman connect target / crosscheck archivelog all; -- 校验日志的可用性 list expired archivelog all; --->列出所有失效的归档日志 delete expired archivelog all; delete archivelog until sequence 16; --->删除log sequence为16及16之前的所有归档日志 delete archivelog all completed before 'sysdate-7'; --->删除系统时间7天以前的归档日志,不会删除闪回区有效的归档日志 delete archivelog all completed before 'sysdate - 1'; --->同上,1天以前的 delete archivelog from time 'sysdate-1'; --->注意这个命令,删除系统时间1天以内到现在的归档日志 delete noprompt archivelog all completed before 'sysdate'; delete noprompt archivelog all completed before 'sysdate - 3/24'; --->该命令清除所有的归档日志 delete noprompt archivelog all; --->同上一命令
直接删除报错:
archived log not deleted, needed for standby or upstream capture process 可以使用以下命令:
delete noprompt force archivelog until time 'sysdate-10'; - 第二种方法就是增大闪回恢复区的大小。如下:
当serivce_name与sid不一样,报错如下:
Caused by: oracle.net.ns.NetException: Listener refused the connection with the following error:
ORA-12514, TNS:listener does not currently know of service requested in connect descriptor
at oracle.net.ns.NSProtocolNIO.negotiateConnection(NSProtocolNIO.java:284)
at oracle.net.ns.NSProtocol.connect(NSProtocol.java:340)
at oracle.jdbc.driver.T4CConnection.connect(T4CConnection.java:1596)
at oracle.jdbc.driver.T4CConnection.logon(T4CConnection.java:588)
... 21 moreflinkcdc采集大数据量oracle数据(性能测试)
- 实时采集oracle数据延迟过大,平均延迟在3秒左右
通过设置以下参数提高实时采集的速度:--source端: 'debezium.log.mining.strategy' = 'online_catalog', 'debezium.log.mining.continuous.mine' = 'true', 'debezium.log.mining.batch.size.min' = '1', 'debezium.log.mining.batch.size.default' = '1', 'debezium.log.mining.sleep.time.default.ms' = '10', 'debezium.poll.interval.ms' = '10', --sink端: 'sink.buffer-flush.max-rows' = '1000000', 'sink.buffer-flush.max-bytes' = '300000000', 'sink.buffer-flush.interval-ms' = '1000', --主要是这个 - starrocks数据有换行符,数据错位:
'sink.properties.row_delimiter' = '^B', 'sink.properties.column_separator' = '^A', - 导入大表(扫描时间很长的表),任务自动重启:
这里简单解释一下flink ck的重启策略:set execution.checkpointing.interval = 2min; set execution.checkpointing.tolerable-failed-checkpoints =10000; -- 您需要设置num值来调整任务允许Checkpoint失败的次数。num需要为0或正整数。如果num为0时,则表示不允许存在任何Checkpoint异常或者失败。 set restart-strategy =fixed-delay; set restart-strategy.fixed-delay.attempts = 2147483647;
flink checkpoint 的重启策略:假如 restart-strategy: fixed-delay restart-strategy.fixed-delay.attempts=3 [default] restart-strategy.fixed-delay.delay=2s [default] 举个栗子: ===> 假如 delay=1s,attempts=1,那么重启的策略就为每2秒尝试重启一次,要么重启成功,要么失败进入下一次重启尝试,如果累计重试次数达到3次但是任然没有成功,那么这个task重启就算失败 Caused by: java.sql.SQLException: ORA-04036: 实例使用的 PGA 内存超出 PGA_AGGREGATE_LIMIT
具体报错:
查看oracle当前设置参数:com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.ConnectException: An exception occurred in the change event producer. This connector will be stopped. at io.debezium.pipeline.ErrorHandler.setProducerThrowable(ErrorHandler.java:42) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1] at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:208) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1] at io.debezium.pipeline.ChangeEventSourceCoordinator.streamEvents(ChangeEventSourceCoordinator.java:152) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1] at io.debezium.pipeline.ChangeEventSourceCoordinator.lambda$start$0(ChangeEventSourceCoordinator.java:119) ~[flink-sql-connector-oracle-cdc-2.2.1.jar:2.2.1] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_311] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_311] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_311] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_311] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_311] Caused by: java.sql.SQLException: ORA-04036: 实例使用的 PGA 内存超出 PGA_AGGREGATE_LIMIT
可以在oracle中设置:show parameter pga; -------------------------------- NAME TYPE VALUE --------------- --------------- ---------------------- pga_aggregate_limit big integer 6400M pga_aggregate_target big integer 3200M --查看日志归档频率时间 show parameter archive_lag; NAME TYPE VALUE --------------------- -------- -------------- archive_lag_target integer 600alter system set archive_lag_target=60 scope=both;
或者设置log.mining.session.max.xs = 300000
flinkcdc引用的debeziem1.5,还没有log.mining.session.max.xs参数,在1.9版本才能使用。所以,还是得在oracle中设置alter system set archive_lag_target=1200 scope=both;
原因:
对于低容量系统,当长时间使用同一会话时,LogMiner 会话可能会消耗过多的 PGA 内存。默认行为是仅在检测到日志切换时使用新的 LogMiner 会话
这里同时启动多个实时采集任务,还是会报这个错误,这里网上给的办法是:
#1. 设置 PGA_AGGREGATE_LIMIT = 0 , 消除每个会话使用PGA的限制(如11g)
alter system set pga_aggregate_limit=0 scope=both;
#2. 增大PGA_AGGREGATE_LIMIT
alter system set pga_aggregate_limit=16384M scope=both;这里先把上面1200秒给更低的时间试试
多个flinkcdc任务共同采集oracle,数据延迟巨大
单个任务采集oracle,速度已经可以控制在1秒以内了,但是,多个任务采集oracle,这边的延迟变得很大,具体原因还不太清楚
但是,这里猜测有以下几种原因:
- 每个任务都会起一个进程去读取logminer,而logminer的数据是存在pga内存里的,就会导致pga内存很高
- 这里通过查看服务器的cpu使用情况,发现每个cdc任务占用cpu特别高,19个任务就可能导致任务玩不转了
根本原因:
oracle-cdc底层调用的是oracle的Logminer,而每个cdc任务启动以后,都会调用Logminer,这会往redolog里写大量的日志,一开始的设置的微批步长太小了,导致在任务刚开始启动的时候,读取的日志远远追不上日志生成的速度
之前的设置:
'debezium.log.mining.strategy' = 'online_catalog',
'debezium.log.mining.continuous.mine' = 'true',
'debezium.poll.interval.ms' = '5',
'debezium.log.mining.batch.size.min' = '1',
'debezium.log.mining.batch.size.default' = '1',
'debezium.log.mining.sleep.time.default.ms' = '10',
'debezium.log.mining.session.max.xs' = '300000',
'debezium.lob.enabled' = 'true',
'debezium.snapshot.fetch.size' = '5000',
'debezium.snapshot.delay.ms' = '3000'优化后的设置:
'debezium.log.mining.strategy' = 'online_catalog',
'debezium.log.mining.continuous.mine' = 'true',
'debezium.poll.interval.ms' = '5',
'debezium.log.mining.batch.size.min' = '50',
'debezium.log.mining.batch.size.default' = '100',
'debezium.log.mining.batch.size.max' = '10000',
'debezium.log.mining.sleep.time.default.ms' = '10',
'debezium.log.mining.sleep.time.max.ms' = '2000',
'debezium.log.mining.sleep.time.increment.ms' = '50',
'debezium.log.mining.view.fetch.size' = '500',
'debezium.lob.enabled' = 'true',
'debezium.snapshot.fetch.size' = '5000',
'debezium.snapshot.delay.ms' = '3000'具体可以参考最系统掌握Flink CDC系列之实时抽取Oracle数据(排雷和调优实践)
关于Oracle补充日志
概述
- Oracle 补充日志(supplemental log)又叫附加日志,可以指示数据库在日志中添加额外信息到日志流中,以支持基于日志的工具,如逻辑standby、streams、GoldenGate、LogMiner。
- 补充日志不是独立的一种日志,是对重做记录中变更矢量的补充信息,增加了变更矢量记载的记录量,Oracle数据库某些功能要求启用补充日志才能正常地或更好的工作,如logminer、DG、闪回事务查询、闪回事务。
- 补充日志可以在数据库级别和表级别上启用
说明
- Oracle中insert、delete命令在默认情况下产生的重做记录足以表明被修改的行的每个字段在被修改前后的值是什么,insert,变更前行不存在,产生的重做记录会记载新行的每个字段的值,delete,变更后不存在,但是由于重做记录也要负责产生撤销数据块的变更,所以行被删除之前的各字段的值也记录在撤销数据块的变更矢量中,也就是insert和delete命令的重做记录中,能找到整行的所有信息。
- update不同于insert和delete一定会涉及一行的所有字段,常常只是更改一个或几个字段,处于对性能的考虑,Oracle没必要把修改的字段的值也保存在变更矢量中,事实上是在撤销块的比昂矢量中只记载被修改的字段的更改前的值,而在数据块的变更矢量中则记载了被修改的字段的新值,同一行中其他没有被修改的字段,不会记载其修改前的值,因为没有被修改。
- 补充日志主要就是为update服务,补充的目的就是要高度还原真实的update命令。
操作命令
- 数据库级别
无论需要启用哪一种标识关键字段补充日志,都需要启用最小补充日志,4种标识关键字段的效果可以累加,不冲突。
查看是否启用补充日志
若结果返回YES或IMPLICIT则说明已开启对应的补充日志,当使用ALL,PRIMARY,UNIQUE或FOREIGN补全日志时最小补充日志默认开启(即查询结果为IMPLICIT)。
启用/关闭补充日志(数据库级别)SELECT SUPPLEMENTAL_LOG_DATA_MIN MIN, --最小补充日志 SUPPLEMENTAL_LOG_DATA_PK PK, --主键补充日志 SUPPLEMENTAL_LOG_DATA_UI UI, --唯一索引补充日志 SUPPLEMENTAL_LOG_DATA_FK FK, --外键补充日志 SUPPLEMENTAL_LOG_DATA_ALL ALL_COLUMN --全字段补充日志 FROM V$DATABASE;
启用最小补充日志可以确保LogMiner(或其他任何基于LogMiner的产品)支持行链接、簇表、索引组织表等。
语法如下:--开启最小补充日志 alter database add supplemental log data; --关闭最小补充日志 alter database drop supplemental log data; --主键补充日志: alter database add supplemental log data (Primary key) columns ; alter database drop supplemental log data (Primary key) columns ; --唯一索引补充日志: alter database add supplemental log data (unique) columns; alter database drop supplemental log data (unique) columns; --外键补充日志: alter database add supplemental log data (foreign key ) columns ; alter database drop supplemental log data (foreign key ) columns ; --全字段补充日志 alter database add supplemental log data (all) columns ; alter database drop supplemental log data (all) columns ; - 表级别
只是针对某个表,没有必要在整个数据库范围启用补充日志功能,在启用表级补充日志之前,应该先启用数据库级最小补充日志。
表级补充日志分为主键、唯一索引、外键、全字段和自定义5种类型,前四种和数据级对应的类型特点一致,只是在特定的表上启用。
特定表上的表级补充日志的启用与关闭会导致所有引用该表的SQL游标非法,会引起一段时间的硬分析增加。
查看是否启用补充日志
SELECT G.LOG_GROUP_NAME,
G.OWNER || '.' || G.TABLE_NAME TABLE_NAME,
G.ALWAYS,
G.GENERATED,
C.COLUMN_NAME
FROM DBA_LOG_GROUPS G
LEFT JOIN DBA_LOG_GROUP_COLUMNS C
ON G.LOG_GROUP_NAME = C.LOG_GROUP_NAME
AND G.TABLE_NAME = C.TABLE_NAME
ORDER BY 1, 2, 3, 4;启用/关闭补充日志(表级别)
--可以通过以下语句启用/关闭所有列或主键/外键/唯一键组合日志组:
alter table table_name add supplemental log data(all,primary key,unique,foreign key) columns;
alter table table_name drop supplemental log data(all,primary key,unique,foreign key) columns;注意
- 试图从数据库中删除最少的补充日志记录,但失败并显示 ORA-32589。
ORA-32589 表示此时不能删除它,因为一些其他补充日志仍依赖于最小日志。SQL> alter database drop supplemental log data; alter database drop supplemental log data * ERROR at line 1: ORA-32589: unable to drop minimal supplemental logging
通过查询V$DATABASE来检查其他补充日志的状态。
为了从数据库中删除最少的补充日志,应该首先删除相关的补充日志。SQL> SELECT supplemental_log_data_min min, supplemental_log_data_pk pk, supplemental_log_data_ui ui,supplemental_log_data_fk fk,supplemental_log_data_all allc FROM v$database; MIN PK UI FK ALLC ______ ______ ______ _____ _______ YES YES YES NO YES
具体可以参考oracle补充日志SQL> alter database drop supplemental log data (all) columns; Database altered. SQL> alter database drop supplemental log data (unique) columns; Database altered. SQL> alter database drop supplemental log data (primary key) columns; Database altered. --再次检查他们的状态。 SQL> SELECT supplemental_log_data_min min, supplemental_log_data_pk pk, supplemental_log_data_ui ui,supplemental_log_data_fk fk,supplemental_log_data_all allc FROM v$database; MIN PK UI FK ALLC ______ ______ ______ _____ _______ YES NO NO NO NO --现在可以删除最小的补充日志。 SQL> alter database drop supplemental log data; Database altered.
oracle-cdc使用 xstream 采集 Oracle
首先需要先安装instantclient
安装instantclient
instantclient-basic-macos.x64-19.3.0.0.0dbru.zip 下载地址
官网下载真的难,找不到下载路径:
- mac 下载地址:
https://download.oracle.com/otn_software/mac/instantclient/193000/instantclient-basic-macos.x64-19.3.0.0.0dbru.zip - windows 下载地址:
https://download.oracle.com/otn_software/nt/instantclient/19300/instantclient-basic-windows.x64-19.3.0.0.0dbru.zip - centos 下载地址:
linux 没找到 zip 包,只能用 rpm 了
https://yum.oracle.com/repo/OracleLinux/OL7/oracle/instantclient/x86_64/getPackage/oracle-instantclient19.3-basic-19.3.0.0.0-1.x86_64.rpm
安装比较简单,就是把安装包解压,然后配置环境变量
export LD_LIBRARY_PATH=/opt/modules/oracle-cli/instantclient_19_3配置Oracle CDC(XStream)
---- Oracle为CDB数据库时的配置
alter system set enable_goldengate_replication=true;
--执行以下命令创建XStream管理员用户并配置权限。
sqlplus sys/digiwin@//localhost:1521/ORADB as sysdba
CREATE TABLESPACE xstream_adm_tbs DATAFILE '/opt/soft/oracle12c/oradata/oradb/xstream_adm_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
-- 需要在 PDB 里也执行
alter session set container = DGWORCL;
CREATE TABLESPACE xstream_adm_tbs DATAFILE '/opt/soft/oracle12c/oradata/oradb/dgworcl/xstream_adm_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
alter session set container = CDB$ROOT;
-- 创建用户
CREATE USER c##dbzadmin IDENTIFIED BY dbz
DEFAULT TABLESPACE xstream_adm_tbs
QUOTA UNLIMITED ON xstream_adm_tbs
CONTAINER=ALL;
GRANT CREATE SESSION, SET CONTAINER TO c##dbzadmin CONTAINER=ALL;
BEGIN
DBMS_XSTREAM_AUTH.GRANT_ADMIN_PRIVILEGE(
grantee => 'c##dbzadmin',
privilege_type => 'CAPTURE',
grant_select_privileges => TRUE,
container => 'ALL'
);
END;
/
exit;
-- 创建 xstream 用户
CREATE TABLESPACE xstream_tbs DATAFILE '/opt/soft/oracle12c/oradata/oradb/xstream_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
alter session set container = DGWORCL;
CREATE TABLESPACE xstream_tbs DATAFILE '/opt/soft/oracle12c/oradata/oradb/dgworcl/xstream_tbs.dbf'
SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
alter session set container = CDB$ROOT;
CREATE USER c##dbzuser IDENTIFIED BY dbz
DEFAULT TABLESPACE xstream_tbs
QUOTA UNLIMITED ON xstream_tbs
CONTAINER=ALL;
GRANT CREATE SESSION TO c##dbzuser CONTAINER=ALL;
GRANT SET CONTAINER TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ON V_$DATABASE to c##dbzuser CONTAINER=ALL;
GRANT FLASHBACK ANY TABLE TO c##dbzuser CONTAINER=ALL;
GRANT SELECT ANY TABLE to c##dbzuser CONTAINER=ALL;
GRANT LOCK ANY TABLE TO c##dbzuser CONTAINER=ALL;
grant select_catalog_role to c##dbzuser CONTAINER=ALL;
-- 创建出站服务器
--注意: 这里必须使用c##dbzadmin登录
sqlplus c##dbzadmin/dbz@localhost:1521/oradb
DECLARE
tables DBMS_UTILITY.UNCL_ARRAY;
schemas DBMS_UTILITY.UNCL_ARRAY;
BEGIN
tables(1) := NULL;
schemas(1) := 'C##FLINKUSER';
DBMS_XSTREAM_ADM.CREATE_OUTBOUND(
server_name => 'dbzxout',
table_names => tables,
schema_names => schemas);
END;
/
-- 删除出站服务器
BEGIN
DBMS_XSTREAM_ADM.DROP_OUTBOUND(
server_name => 'dbzxout'
);
END;
/
--允许c##dbzuser用户连接XStream出站服务器
BEGIN
DBMS_XSTREAM_ADM.ALTER_OUTBOUND(
server_name => 'dbzxout',
connect_user => 'system');
END;
/Xstream配置好后,在 flinkcdc 中无法捕捉到数据变化
通过查询 xstream 的日志:
-- 查看是否启用成功
SELECT capture_name, status,status_change_time, error_number, error_message FROM DBA_CAPTURE;
-- 具体可以参考:https://blog.csdn.net/iteye_4537/article/details/81596847看到这里的status 为ABORTED,error_message为:ORA-01031: 权限不足
并且观察到,每次启动 flinkcdc 程序的时候,这里的status_change_time都会刷新,可以定位到,这里捕捉不到数据就是因为flinkcdc 设置的用户的权限有问题
IDEA执行flink-cdc 实时采集的代码(xstream)
配置了环境变量以后,在 IDEA 启动采集程序,还是会报错:
java.lang.UnsatisfiedLinkError: no ocijdbc19 in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1860)
at java.lang.Runtime.loadLibrary0(Runtime.java:871)
at io.debezium.jdbc.JdbcConnection.lambda$patternBasedFactory$0(JdbcConnection.java:179)
at io.debezium.jdbc.JdbcConnection$ConnectionFactoryDecorator.connect(JdbcConnection.java:116)
at io.debezium.connector.oracle.OracleConnection.resolveOracleDatabaseVersion(OracleConnection.java:128)
at io.debezium.connector.oracle.OracleConnection.<init>(OracleConnection.java:70)
at io.debezium.connector.oracle.OracleConnectorTask.start(OracleConnectorTask.java:53)
at io.debezium.connector.common.BaseSourceTask.start(BaseSourceTask.java:130)
at io.debezium.embedded.EmbeddedEngine.run(EmbeddedEngine.java:759)解决办法:在 VM Options 里设置-Djava.library.path=/opt/modules/oracle-cli/instantclient_19_3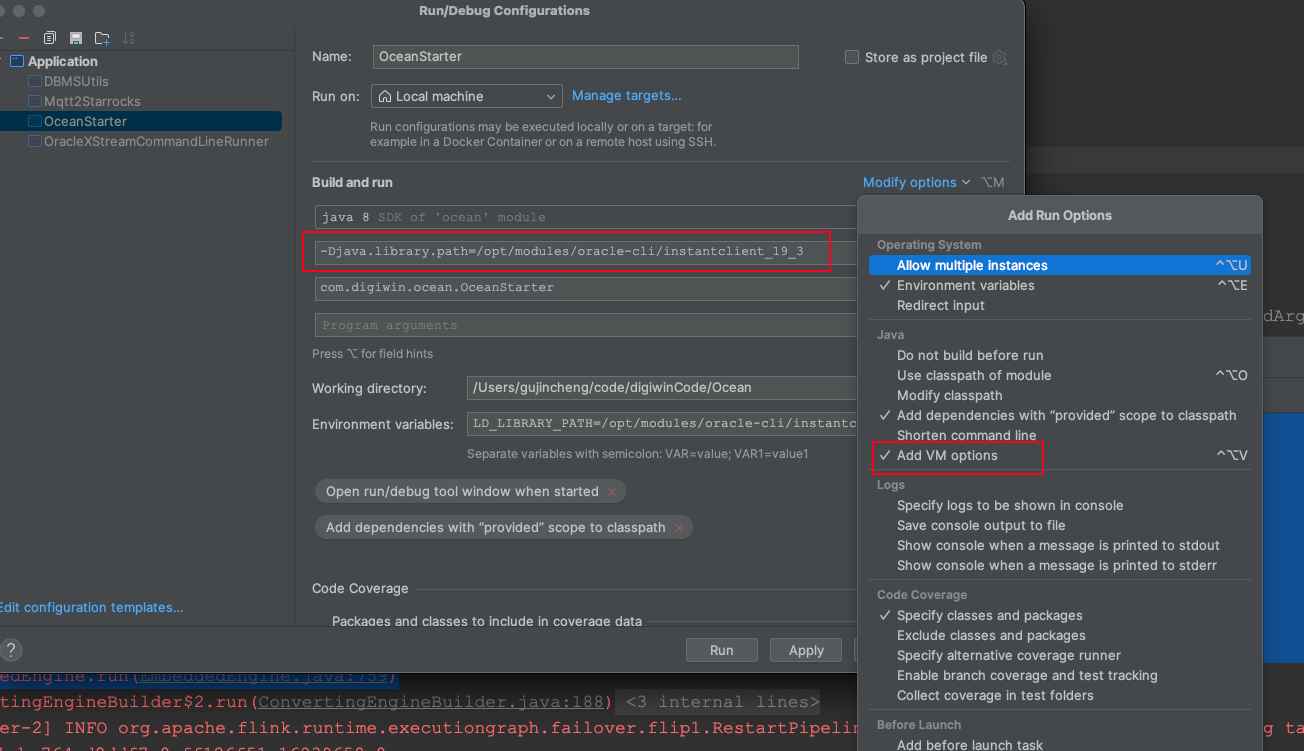
standalone集群启动oracle-cdc程序(xstream)
直接启动程序,会报以下报错:
Caused by: java.lang.UnsatisfiedLinkError: no ocijdbc19 in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1860) ~[?:1.8.0_311]
at java.lang.Runtime.loadLibrary0(Runtime.java:871) ~[?:1.8.0_311]
at java.lang.System.loadLibrary(System.java:1122) ~[?:1.8.0_311]
at oracle.jdbc.driver.T2CConnection$1.run(T2CConnection.java:4295) ~[ojdbc8.jar:19.3.0.0.0]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_311]
at oracle.jdbc.driver.T2CConnection.loadNativeLibrary(T2CConnection.java:4291) ~[ojdbc8.jar:19.3.0.0.0]
at oracle.jdbc.driver.T2CConnection.logon(T2CConnection.java:476) ~[ojdbc8.jar:19.3.0.0.0]
at oracle.jdbc.driver.PhysicalConnection.connect(PhysicalConnection.java:793) ~[ojdbc8.jar:19.3.0.0.0]需要在/etc/profile下配置export LD_LIBRARY_PATH=/usr/lib/oracle/19.3/client64/lib
oracle-cdc需要把xstream.jar打包到采集程序里,但是xstream.jar是个第三方jar,中间试了好几次打包打到最终的jar,都不行,会报oralce/sql/number的问题
最终使用的方案是,把xsteram.jar放到公司的maven私服,再把它打包进最终jar
还有一个报错:
java.lang.UnsatisfiedLinkError: Native Library /usr/lib/oracle/19.3/client64/lib/libocijdbc19.so already loaded in another classloade这里的报错原因是,java的类加载器有顺序。具体原因不明,解决方法是,把xstream.jar放到jre/lib/ext下,但是这样是有风险的
还有一个解决方法,不知道是否可行,设置classloader.check-leaked-classloader : false
这里一开始把xstream.jar放到jre/lib/ext下,解决了问题,但是,后来我把jre下的xstream删掉,还是没出问题,不知道为啥了
提交任务到yarn启动oracle-cdc程序(xstream)
虽然standalone启动oracle-cdc(xstream)成功,但是,直接提交任务到yarn上,还是会报错:
java.lang.UnsatisfiedLinkError: no ocijdbc19 in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1860) ~[?:1.8.0_311]
at java.lang.Runtime.loadLibrary0(Runtime.java:871) ~[?:1.8.0_311]
at java.lang.System.loadLibrary(System.java:1122) ~[?:1.8.0_311]
at oracle.jdbc.driver.T2CConnection$1.run(T2CConnection.java:4295) ~[ocean-1.0-jar-with-dependencies.jar:?]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_311]
at oracle.jdbc.driver.T2CConnection.loadNativeLibrary(T2CConnection.java:4291) ~[ocean-1.0-jar-with-dependencies.jar:?]
at oracle.jdbc.driver.T2CConnection.logon(T2CConnection.java:476) ~[ocean-1.0-jar-with-dependencies.jar:?]
at oracle.jdbc.driver.PhysicalConnection.connect(PhysicalConnection.java:793) ~[ocean-1.0-jar-with-dependencies.jar:?]
at oracle.jdbc.driver.T2CDriverExtension.getConnection(T2CDriverExtension.java:62) ~[ocean-1.0-jar-with-dependencies.jar:?]
at oracle.jdbc.driver.OracleDriver.connect(OracleDriver.java:750) ~[ocean-1.0-jar-with-dependencies.jar:?]
at oracle.jdbc.driver.OracleDriver.connect(OracleDriver.java:562) ~[ocean-1.0-jar-with-dependencies.jar:?]
at java.sql.DriverManager.getConnection(DriverManager.java:664) ~[?:1.8.0_311]
at java.sql.DriverManager.getConnection(DriverManager.java:208) ~[?:1.8.0_311]但是,明明已经配置了/etc/profile也还是不行
解决方法:
在flink-conf.yml配置一下参数:
containerized.master.env.LD_LIBRARY_PATH: "/usr/lib/oracle/19.3/client64/lib"
containerized.taskmanager.env.LD_LIBRARY_PATH: "/usr/lib/oracle/19.3/client64/lib"ora-28014:cannot drop administrative users
一套cdb环境的12.2库,开发人员想删掉当时建的一个用户,
报错如下:ora-28014:cannot drop administrative users
查了下解决方案:
alter session set “_oracle_script”=true;
然后再执行drop user xxx cascade操作即可。
实时采集启动的时候报错:Caused by: java.sql.SQLException: ORA-01435: 用户不存在
原因是创建flinkuser用户的时候是在cdb里创建的,其实它用到的是pdb,所以创建用户的时候,需要把pdb和cdb里都创建一个同名的用户
docker安装oracle19c
- pull images
docker pull registry.cn-hangzhou.aliyuncs.com/zhuyijun/oracle:19c - 启动docker
docker run -d -p 1525:1521 -p 5505:5500 -e ORACLE_SID=ORCL -e ORACLE_PDB=ORCLPDB -e ORACLE_PWD=digiwin@123 -e ORACLE_EDITION=standard -e ORACLE_CHARACTERSET=AL32UTF8 -v /opt/soft/oracle19c/oradata:/opt/oracle/oradata --name oracle19c registry.cn-hangzhou.aliyuncs.com/zhuyijun/oracle:19c # 查看日志,等待加载进度(初次加载比较慢) docker logs -tf oracle19c # 等待过程可能会比较漫长,成功的日志: ######################### DATABASE IS READY TO USE! #########################docker安装oracle12c
- pull images
docker pull registry.cn-hangzhou.aliyuncs.com/zhuyijun/oracle-12c - 启动docker
具体可参考docker安装oracledocker run --name oracle12c -d \ -p 1521:1521 -p 5500:5500 \ -e ORACLE_SID=ORCL \ -e ORACLE_PDB=ORCLPDB \ -e ORACLE_PWD=digiwin@123 \ -v /opt/soft/oracle12c/oradata:/opt/oracle/oradata \ registry.cn-hangzhou.aliyuncs.com/laowu/oracle:12.2.0.1.0 # 查看日志,等待加载进度(初次加载比较慢) docker logs -tf oracle12c # 等待过程可能会比较漫长,成功的日志: ######################### DATABASE IS READY TO USE! #########################
oracle实时采集
Oracle归档日志和重做日志
因为实时数据采集主要是作用在归档日志和重做日志上,如果对这两种日志不理解,将导致Logminer出现的错误无法有一个清晰的认知,从而无法解决现场实际面临的各种问题。
重做日志
也被称为redo log,主要是用来进行数据库恢复的,你对数据库表的任何数据操作,都会首先将变更写入重做日志中,用来在数据库宕机时能及时恢复数据,里面记录了数据的详细变更记录。默认数据库会有3个重做日志文件,可以通过查询V$LOGFILE获取。这3个重做日志文件是轮流使用的,当第一个用满后将切换到第二个、当第二个用满之后切换到第三个,当第三个用满之后切换到第一个,切换之后目标重做日志就被覆盖了,也就是丢失了。例如当第一个用满后将切换到第二个,那么原来第二个重做日志上的数据就丢失了。当然,这个重做日志的文件大小和个数都是可以配置的。
特点:及时写入,自动循环覆盖
归档日志
归档日志主要是重做日志的一个备份,也可以用来进行数据的恢复,也可以用来进行数据库的同步。由于重做日志会循环使用,并且还会出现覆盖丢失的情况,因此,需要将重做日志放到别的地方进行备份存储,这也就诞生了归档日志。归档日志默认是不开启的,需要配置数据库才能使用,并且需要占用许多存储,因此需要及时的清理。重做日志会定时的存储成归档日志,并且在切换的时候也会存储到归档日志中,防止重做日志丢失。
特点:自动触发写入、可永久存储
问题:ora-01291: missing logfile
有了Logminer和归档日志和重做日志的简单介绍之后就可以进入今天的正题了,我们在实时抽取oracle归档日志的时候发现,当数据量很大的时候经常会出现oracle错误:ora-01291: missing logfile,提示找不到重做日志文件了。
首先我们需要分析Logminer的第二步:DBMS_LOGMNR.ADD_LOGFILE,这一步不仅需要将归档日志添加到Logminer引擎中,还需要将重做日志也需要添加进来,因为归档日志的数据并不是及时的,需要配合归档日志 + 重做日志才能保证及时性,但是重做日志又有被覆盖的可能,因此就会出现ora-01291错误。了解了问题原因,那么我们如何解决问题呢?既然只有在数据量很大的时候才会出现,那么我们可以将重做日志的个数增加到10个,每个文件大小增加到5G。这个调整需要谨慎操作,官方的说法是最好将重做日志的切换时间控制在半小时左右。这样就不会出现ora-01291的错误了,因为重做日志的切换频率降低了、文件个数也增加了。例如Logminer目前正在读取重做日志5 + 归档日志,只有当oracle此时立马把 重做日志5,6,7,8,9,0,1,2,3,4,5(以10个重做日志为例)全部写满才会导致重做日志5丢失,而此时每个操作日志的大小为5G,总共需要写入50G的数据,你不可能那么快写入50GB,当你写入的时候Logminer已经读取完了,因此就不会再出现找不到重做日志的问题了。
未来发展方向
Flink CDC 在新能源制造业的实践
将 redo log 异步传输到另外一台没有业务压力的 Oracle 实例上, 然后在另外一台机器上开启并发切分 scn range 事件,开启 LogMiner 线程并发的解析对应 scn range 事件,顺序的处理获取到的事件。