本文主要包括:
- Hbase数据压缩
Hbase数据压缩
压缩格式的选择
常用的几种压缩格式:lzo,gzip,snappy,bzip2,我们简单做一下对比,方便我们在实际场景中选择不同的压缩格式。
- 支持特性对比:
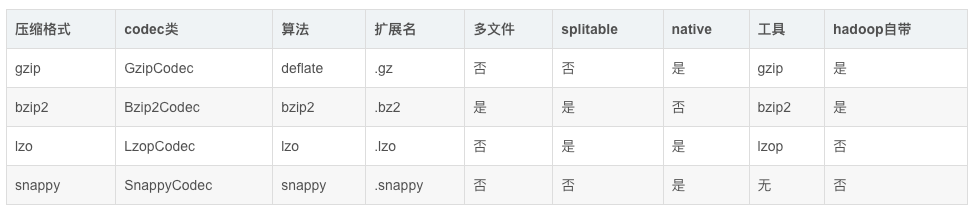
- 压缩相关codec实现在org.apache.hadoop.io.compress包下面
- gzip算法hadoop内置支持,使用时直接处理文本数据一样,使用方便,压缩比高,缺点就是不支持split。如果压缩后文件与块大小相当,可以考虑使用gzip压缩,比如:小时原始日志压缩成gzip文件,使用方便。
- bzip2 支持split,压缩比高,支持多文件,缺点就是慢。
- lzo 压缩/解压速度也比较快,合理的压缩率;支持split(需要建索引,文件修改后需要重新建索引),支持hadoop native库,需要自己安装;
- snappy 压缩/解压速度也比较快,合理的压缩率,不支持split,支持hadoop native库,需要自己安装。可以用于map中间结果的压缩。
- 性能对比
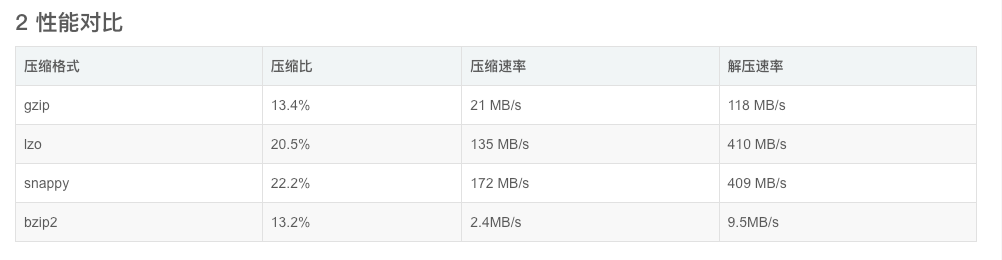
是否压缩数据以及使用何种压缩格式对性能具有重要的影响,一般原则:
- 需要平衡压缩和解压缩数据所需的能力、读写数据所需的磁盘 IO,以及在网络中发送数据所需的网络带宽。正确平衡这些因素有赖于集群和数据的特征,以及您的使用模式。
- 如果数据已压缩(例如 JPEG 格式的图像),则不建议进行压缩。事实上,结果文件实际上可能大于原文件。
- GZIP 压缩使用的 CPU 资源比 Snappy 或 LZO 更多,但可提供更高的压缩比。GZIP 通常是不常访问的冷数据的不错选择。而 Snappy 或 LZO 则更加适合经常访问的热数据。
- BZip2 还可以为某些文件类型生成比 GZip 更多的压缩,但是压缩和解压缩时会在一定程度上影响速度。HBase 不支持 BZip2 压缩。
- Snappy 的表现通常比 LZO 好。应该运行测试以查看您是否检测到明显区别。
- 对于 MapReduce,如果您需要已压缩数据可拆分,BZip2、LZO 和 Snappy 格式都可拆分,但是 GZip 不可以。可拆分性与 HBase 数据无关。
- 对于 MapReduce,可以压缩中间数据、输出或二者。相应地调整您为 MapReduce 作业提供的参数。
压缩方式
创建表的时候指定
- 直接在hbase建表
create 'gjc_test',{NAME=>'f1',COMPRESSION=>'Snappy'} - 在phoenix建表
create table ORACLEARCHIVESPACECOLLECTED_LATEST_BAK( EID VARCHAR, DEVICEID VARCHAR, FLUMETIMESTAMP VARCHAR, COLLECTEDTIME VARCHAR, COLLECTCONFIGID VARCHAR, UPLOADDATAMODELCODE VARCHAR, SOURCE_DB_ID VARCHAR, DF_FILE_SYSTEM VARCHAR, DF_BLOCKS VARCHAR, DF_USED VARCHAR, DF_AVAILABLE VARCHAR, DF_PERCENT_USE VARCHAR, DF_MOUNTED_ON VARCHAR, CMDNOTEXIST VARCHAR, EXECERROR VARCHAR, DF_PERCENT_USE_VALUE VARCHAR, CONSTRAINT my_pk PRIMARY KEY(EID,DEVICEID,FLUMETIMESTAMP,SOURCE_DB_ID) ) column_encoded_bytes=0, COMPRESSION='SNAPPY';对已有的表的数据进行压缩
- 在hbase中压缩
# 禁用表 disable 'device_logs' # 修改info列族的压缩格式 alter 'device_logs' ,{NAME=>'f1',COMPRESSION=>'Snappy'} # 启用表 enable 'device_logs' # 查看表信息 describe 'device_logs' # 手动触发major_compaction major_compact 'device_logs' - 通过phoenix方式压缩
注意:ALTER TABLE SNMP_BIZ_CPU_LATEST SET COMPRESSION='SNAPPY'; -- 在phoenix执行完后,如果想要数据文件立刻复制,需要手动触发major_compaction,在hbase执行 major_compact 'SNMP_BIZ_CPU_LATEST'
这里踩了一个坑,如果hbase的表是使用phoenix建表的,那么数据压缩也需要使用phoneix去压缩,这里使用hbase压缩了100多个表,导致所有压缩的表在phoenix无法查询
原因: phoneix的数据编码和hbase的底层编码不一样。使用hbase数据压缩,相当于让hbase按照自己的编码格式去解析phoneix的底层数据,数据就乱了
这里使用了各种办法,最后都没有把数据恢复回来,最后没办法,把数据重写了。把roekey从表里其他字段获取出来create table WINDOWSSECURITYCEV20201472COLLECTED( ROWKEY VARCHAR not null primary key, DEVICEID VARCHAR, EID VARCHAR, COLLECTEDTIME VARCHAR, COLLECTCONFIGID VARCHAR, UPLOADDATAMODELCODE VARCHAR, DEVICECOLLECTDETAILID VARCHAR, CODE VARCHAR, MESSAGE VARCHAR, PS_CODE VARCHAR, DATA VARCHAR, ERROR_MESSAGE VARCHAR, OPERATING_SYSTEM VARCHAR, DOMAIN_CONTROLLER VARCHAR, UPDATE_STATE_MESSAGE VARCHAR, COMPLIANCE VARCHAR, ENFORCEMENT VARCHAR ) column_encoded_bytes=0, COMPRESSION='SNAPPY'; hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=WINDOWSSECURITYCEV20201472COLLECTED_BAK WINDOWSSECURITYCEV20201472COLLECTED upsert into WINDOWSSECURITYCEV20201472COLLECTED select DEVICEID || to_char(to_number(to_date(COLLECTEDTIME,'yyyy-MM-dd hh:mm:ss','GMT+8')),'#') , DEVICEID , EID , COLLECTEDTIME , COLLECTCONFIGID , UPLOADDATAMODELCODE , DEVICECOLLECTDETAILID, CODE , MESSAGE , PS_CODE , DATA , ERROR_MESSAGE , OPERATING_SYSTEM , DOMAIN_CONTROLLER , UPDATE_STATE_MESSAGE , COMPLIANCE , ENFORCEMENT from WINDOWSSECURITYCEV20201472COLLECTED_BAK使用YCSB测试Hbase读写性能
YCSB工具安装:# 到githup上下载ycsb-hbase20-binding-0.17.0.tar.gz https://github.com/brianfrankcooper/YCSB/releases/tag/0.17.0 cd /root/gujc/ycsb-hbase20-binding-0.17.0/workloads cat workloada recordcount=150000 operationcount=150000 workload=site.ycsb.workloads.CoreWorkload readallfields=true readproportion=0.5 updateproportion=0.5 scanproportion=0 insertproportion=0 requestdistribution=zipfian # 生成数据 bin/ycsb load hbase20 -P workloads/workloada -cp /etc/hbase/conf/ -p table=gjc_test -p columnfamily=info # 测试数据 bin/ycsb run hbase20 -P workloads/workloada -cp /etc/hbase/conf/ -p table=gjc_test -p columnfamily=infoHBase中的Compaction详解
HBase是基于一种LSM-Tree(Log-Structured Merge Tree)存储模型设计的,写入路径上是先写入WAL(Write-Ahead-Log)即预写日志,再写入memstore缓存,满足一定条件后执行flush操作将缓存数据刷写到磁盘,生成一个HFile数据文件。随着数据不断写入,磁盘HFile文件就会越来越多,文件太多会影响HBase查询性能,主要体现在查询数据的io次数增加。为了优化查询性能,HBase会合并小的HFile以减少文件数量,这种合并HFile的操作称为Compaction,这也是为什么要进行Compaction的主要原因。Compaction的作用
其实Compaction操作属于资源密集型操作特别是IO密集型,这点后面也会提及到,Compaction其实就是以短时间内的IO消耗,以换取相对稳定的读取性能。Compaction 分类
HBase Compaction分为两种:Minor Compaction 与 Major Compaction,通常我们简称为小合并、大合并。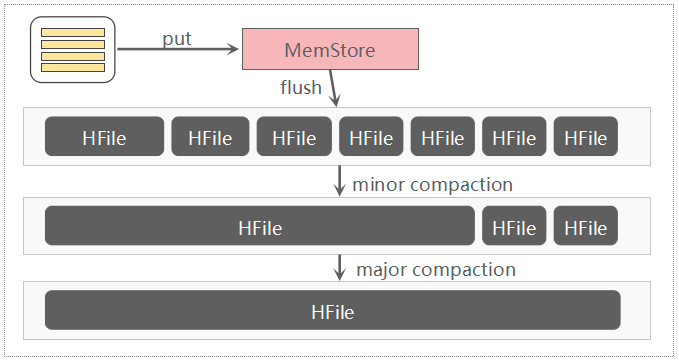
Minor Compaction:指选取一些小的、相邻的HFile将他们合并成一个更大的HFile。默认情况下,minor compaction会删除选取HFile中的TTL过期数据。
Major Compaction:指将一个Store中所有的HFile合并成一个HFile,这个过程会清理三类没有意义的数据:被删除的数据(打了Delete标记的数据)、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此,生产环境下通常关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。这里值得关注,默认情况下Minor Compaction也会删除数据,但只是删除合并HFile中的TTL过期数据。Major Compaction是完全删除无效数据,包括被删除的数据、TTL过期数据以及版本号过大的数据。
Compaction 触发条件
HBase触发Compaction的条件有三种: - memstore Flush
可以说compaction的根源就在于flush,memstore 达到一定阈值或其他条件时就会触发flush刷写到磁盘生成HFile文件,正是因为HFile文件越来越多才需要compact。HBase每次flush之后,都会判断是否要进行compaction,一旦满足minor compaction或major compaction的条件便会触发执行。 - 后台线程周期性检查
后台线程 CompactionChecker 会定期检查是否需要执行compaction,检查周期为hbase.server.thread.wakefrequency * hbase.server.compactchecker.interval.multiplier,这里主要考虑的是一段时间内没有写入请求仍然需要做compact检查。其中参数 hbase.server.thread.wakefrequency 默认值 10000 即 10s,是HBase服务端线程唤醒时间间隔,用于log roller、memstore flusher等操作周期性检查;参数 hbase.server.compactchecker.interval.multiplier 默认值1000,是compaction操作周期性检查乘数因子。10 * 1000 s 时间上约等于2hrs, 46mins, 40sec。 - 手动触发
是指通过HBase Shell、Master UI界面或者HBase API等任一种方式 执行 compact、major_compact等命令。(这里主要指的是Major Compact)
注意:HBase RS内部设计了两个线程池:large compactions与small compactions,用来分开处理Compaction操作,如果待合并文件的总大小大于(2 * hbase.hstore.compaction.max * hbase.hregion.memstore.flush.size)则交给large compactions线程池处理,否则交给small compactions线程池处理。
Compaction 参数解析
Major Compaction 参数
Major Compaction涉及的参数比较少,主要有大合并时间间隔与一个抖动参数因子,如下:
hbase.hregion.majorcompaction:Major compaction周期性时间间隔,默认值604800000,单位ms。
表示major compaction默认7天调度一次,HBase 0.96.x及之前默认为1天调度一次。设置为 0 时表示禁用自动触发major compaction。需要强调的是一般major compaction持续时间较长、系统资源消耗较大,对上层业务也有比较大的影响,一般生产环境下为了避免影响读写请求,会禁用自动触发major compaction。
hbase.hregion.majorcompaction.jitter:Major compaction抖动参数,默认值0.5
这个参数是为了避免major compaction同时在各个regionserver上同时发生,避免此操作给集群带来很大压力。 这样节点major compaction就会在 + 或 - 两者乘积的时间范围内随机发生。
Minor Compaction 参数
Minor compaction涉及的参数比major compaction要多,各个参数的目标是为了选择合适的HFile:
hbase.hstore.compaction.min: 一次minor compaction最少合并的HFile数量,默认值 3。表示至少有3个符合条件的HFile,minor compaction才会启动。一般情况下不建议调整该参数。如果要调整,不建议调小该参数,这样会带来更频繁的压缩,调大该参数的同时其他相关参数也应该做调整。早期参数名称为 hbase.hstore.compactionthreshold。
hbase.hstore.compaction.max: 一次minor compaction最多合并的HFile数量,默认值 10。这个参数也是控制着一次压缩的时间。一般情况下不建议调整该参数。调大该值意味着一次compaction将会合并更多的HFile,压缩时间将会延长。
hbase.hstore.compaction.min.size:文件大小 < 该参数值的HFile一定是适合进行minor compaction文件,默认值 128M(memstore flush size)意味着小于该大小的HFile将会自动加入(automatic include)压缩队列。一般情况下不建议调整该参数。但是,在write-heavy就是写压力非常大的场景,可能需要微调该参数、减小参数值,假如每次memstore大小达到1~2M时就会flush生成HFile,此时生成的每个HFile都会加入压缩队列,而且压缩生成的HFile仍然可能小于该配置值会再次加入压缩队列,这样将会导致压缩队列持续很长。
hbase.hstore.compaction.max.size:文件大小 > 该参数值的HFile将会被排除,不会加入minor compaction,默认值Long.MAX_VALUE没有什么限制。一般情况下也不建议调整该参数。
hbase.hstore.compaction.ratio:这个ratio参数的作用是判断文件大小 > hbase.hstore.compaction.min.size的HFile是否也是适合进行minor compaction的,默认值1.2更大的值将压缩产生更大的HFile,建议取值范围在1.0~1.4之间。大多数场景下也不建议调整该参数。
hbase.hstore.compaction.ratio.offpeak: 此参数与compaction ratio参数含义相同,是在原有文件选择策略基础上增加了一个非高峰期的ratio控制,默认值5.0。这个参数受另外两个参数 hbase.offpeak.start.hour 与 hbase.offpeak.end.hour 控制,这两个参数值为[0, 23]的整数,用于定义非高峰期时间段,默认值均为-1表示禁用非高峰期ratio设置。
Compaction 总结
HBase Compaction操作是为了数据读取做的优化,总的来说是以牺牲磁盘io来换取读性能的基本稳定。Compaction操作分为minor compaction与major compaction,其中major compaction消耗资源较大、对读写请求有一定影响,因此一般是禁用自动周期性执行而选择业务低峰期时手动执行。
具体可以参考HBase Compaction的前生今世-身世之旅
Hbase的MinorCompact过程解析及参数调优
hbase性能优化
在阿里云正式区做数据压缩的时候,因为这个集群内有一张表单表数据量就有6T,表太大了,不敢随便压缩,并且,hbase集群一直在告警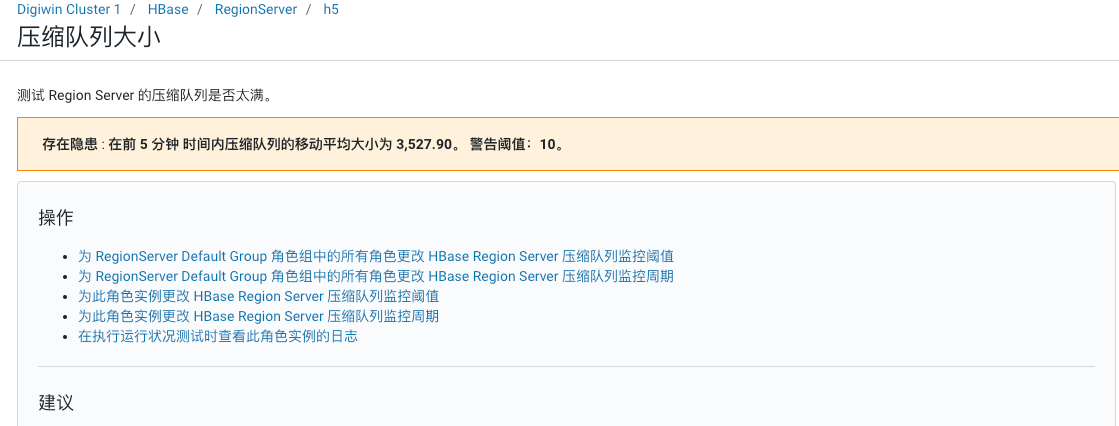
分析原因
这里分析了一下告警原因:
5.6 T 6.3 T /hbase/data/default/TraceV2TraceV2这张表每个小时能增长40G的数据,并且,该表设置了TTL,也就是说,每小时它要写40G数据,然后还要清理掉40G的数据。这么频繁的写操作,就会造成频繁的compaction
解决方法
因此需要对hbase做性能优化