本文主要包括:
- Starrocks性能优化
大SQL报内存不够
执行2亿的数据group by,报错:
ERROR 1064 (HY000): Memory of Queryac34fc2a-bfea-11ee-afb0-0cda411dfefe exceed limit. Pipeline Backend: 192.168.101.97, fragment: ac34fc2a-bfea-11ee-afb0-0cda411dff01 Used: 21478902080, Limit: 21474836480. Mem usage has exceed the limit of single query, You can change the limit by set session variable query_mem_limit这里开启Starrocks的中间结果落盘:
- 在 BE 配置文件 be.conf 中指定落盘路径 spill_local_storage_dir,并重启集群使修改生效。
spill_local_storage_dir=/<dir_1>[;/<dir_2>] - 在SQL执行之前,首先设置以下参数
通过设置以上参数,大sql可以正常执行SET enable_spill = true; SET spill_mode = "auto"; set query_timeout = 600;
all partitions have no load data
fe的日志里,存在大量的all partitions have no load data,这是因为,实时采集的时候,设置了每秒streamload一次。但是很多表其实是没有数据的
fe.warn.log日志:
2024-02-01 16:39:16,437 WARN (thrift-server-pool-285904|291996) [FrontendServiceImpl.loadTxnPrepare():1562] failed to prepare txn_id: 40582: all partitions have no load data
2024-02-01 16:39:16,450 WARN (thrift-server-pool-285910|292002) [FrontendServiceImpl.loadTxnRollback():1620] failed to rollback txn 40582: transaction not found: 40582
2024-02-01 16:39:35,889 WARN (thrift-server-pool-285970|292062) [FrontendServiceImpl.loadTxnPrepare():1562] failed to prepare txn_id: 40583: all partitions have no load data
2024-02-01 16:39:35,899 WARN (thrift-server-pool-285972|292064) [FrontendServiceImpl.loadTxnRollback():1620] failed to rollback txn 40583: transaction not found: 40583可以在fe.conf里设置empty_load_as_error = false来规避
Query Profile 概述
通过将变量 enable_profile 设置为 true 以启用 Query Profile:
SET global enable_profile = true;具体可以参考Query Profile 概述
提高Starrocks的写入性能
设置在be.conf里设置:flush_thread_num_per_store=8
Too many versions. tablet_id: 219542, version_count: 1001, limit: 1000
Caused by: com.starrocks.connector.flink.manager.StarRocksStreamLoadFailedException: Failed to flush data to StarRocks, Error response:
{“Status”:“Fail”,“BeginTxnTimeMs”:0,“Message”:“Too many versions. tablet_id: 219542, version_count: 1001, limit: 1000”,“NumberUnselectedRows”:0,“CommitAndPublishTimeMs”:0,
“Label”:“0e20db82-c001-4ba6-aa85-2bde651e2e17”,“LoadBytes”:889,“StreamLoadPutTimeMs”:5,“NumberTotalRows”:0,“WriteDataTimeMs”:86,“TxnId”:41058,“LoadTimeMs”:92,“ReadDataTimeMs”:0,“NumberLoadedRows”:0,“NumberFilteredRows”:0}在be.conf 里设置以下参数
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2
update_compaction_num_threads_per_disk = 2 #(该参数属于主键模型单独的compaction参数)高并发执行越来越慢
执行sql时快时慢
具体表现在:
数据通过kafka_connetor导入到Starocks,刚开始查询速度很稳定,导入一段时间后,大概4个小时以后,再次查询相同的sql,每隔几秒钟,总有一个耗时比较长的。 并且kafka里的数据后期数据量就很少了。
把实时采集的程序停止后,查询就又变稳定了
问题排查流程–导入
https://forum.mirrorship.cn/t/topic/1680
too many tablet version 问题解决方法
https://forum.mirrorship.cn/t/topic/1578
发生 “close index channel failed” 和 “too many tablet versions” 错误应该如何处理?
上述报错是因为导入频率太快,数据没能及时合并 (Compaction) ,从而导致版本数超过支持的最大未合并版本数。默认支持的最大未合并版本数为 1000。可以通过如下方法解决上述报错:
增大单次导入的数据量,降低导入频率。
修改 BE 配置文件 be.conf 中相关参数的配置,以加快 Compaction:
对于明细表、聚合表和更新表,可以适当调大 cumulative_compaction_num_threads_per_disk、base_compaction_num_threads_per_disk 和 cumulative_compaction_check_interval_seconds 的值。例如
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2对于主键表,可以适当调大 update_compaction_num_threads_per_disk 的值。适当调小 update_compaction_per_tablet_min_interval_seconds 的值。
update_compaction_num_threads_per_disk = 4
update_compaction_per_tablet_min_interval_seconds = 30对于出现too many tablet versions的表,如何修复这个表?
现在是这个表无法读取
starrocks高并发压测与优化
可以查看官方拿sr与durid做的对比的描述:高并发条件下 druid 和 starrocks 性能对比与调优实践
StarRocks 常见告警及处理办法
StarRocks 常见告警及处理办法
StarRocks 最佳实践
BE宕机问题排查指南
be CPU突然飙高问题排查:
查看具体线程里在做什么操作:
perf top 通过perf top查看,starrocks::RuntimeState::log_error占用比较高
在starrocks官方论坛里看到,是因为:
log_error 死锁,导致频繁打 cancel 日志,CPU高
query_pool 内存不释放
5 tids: 814,817,819,825,833
0x7e6ea98 starrocks::RuntimeState::log_error(starrocks::Status const&)
0x7eaf680 starrocks::pipeline::ExchangeSinkOperator::set_finishing(starrocks::RuntimeState*)
0x550130c starrocks::pipeline::PipelineDriver::_mark_operator_finishing(std::shared_ptr<starrocks::pipeline::Operator>&, starrocks::RuntimeState*)
0x5502ce8 starrocks::pipeline::PipelineDriver::process(starrocks::RuntimeState*, int)
0x7e4e6e8 starrocks::pipeline::GlobalDriverExecutor::_worker_thread()
0x81649ec starrocks::ThreadPool::dispatch_thread()
0x815dc5c starrocks::Thread::supervise_thread(void*)
0xffff838fd5c8 (/usr/lib/aarch64-linux-gnu/libc.so.6+0x7d5c8)
0xffff83965edc (/usr/lib/aarch64-linux-gnu/libc.so.6+0xe5edc)解决方案: 升级到3.3.3+
如果不升级,只能重启be
高并发条件下 druid 和 starrocks 性能对比与调优实践
可以参考高并发条件下 druid 和 starrocks 性能对比与调优实践
BE 磁盘IO高调查
我们3个BE节点的有一个 BE 节点, 发现这个单节点的 IO 接近打满了,其他两个节点正常。 tablet所有 be 是均匀分布的。 大部分表都是 6分桶 ,目前集群里的表都是主键模型。iotop看了下 这个节点相比其他节点 garbage_sweeper 占用很大的读 io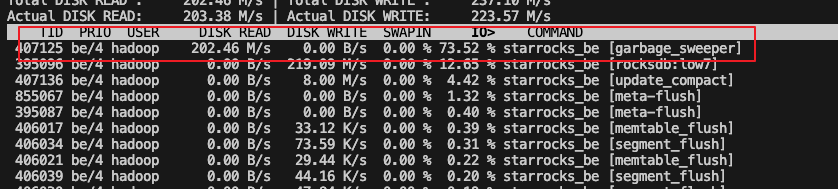
## 查看具体是哪块磁盘的IO占用高
iostat -x -k 1
## 关注第4列和第7列,可以定位到是读写哪些⽂件导致的磁盘io被打满
lsof -p $be_pid | grep '$be_storage_path' | grep 'w'
##