本文主要包括:
Ambari自定义服务
以集成ES为例
Ambari集成Elasticsearch
依赖条件: Ambari集群已正常安装
整体流程:
- 编写服务管理代码
- 上传至ambari-server安装节点的 /var/lib/ambari-server/resources/stacks/HDP/3.3/services/ 目录下
- 重启ambari-server服务
- 在Ambari页面安装集成的服务,并验证服务是否正常安装
- 在Ambari页面验证启动、停止、修改配置、状态监测功能
集成服务代码
栈stack在安装后服务器上的目录:/var/lib/ambari-server/resources/stacks/HDP
栈stack在源码上的目录:ambari-server/src/main/resources/stacks/HDP
所有新增服务的定义文件,都在栈目录下编写,使用HiDataPlus的Ambari时,栈为3.3版本,服务定义在 /var/lib/ambari-server/resources/stacks/HDP/3.3/services/ 目录下
服务定义部分,此处以Elasticsearch为例:
root@ddp1 ELASTICSEARCH]# pwd
/var/lib/ambari-server/resources/stacks/HDP/3.3/services/ELASTICSEARCH
[root@ddp1 ELASTICSEARCH]# tree
.
├── configuration
│ ├── elasticsearch-env.xml
│ └── elasticsearch.yml.xml
├── metainfo.xml
├── package
│ ├── archive.zip
│ ├── scripts
│ │ ├── elasticsearch_client.py
│ │ ├── elasticsearch.py
│ │ ├── elasticsearch_server.py
│ │ └── params.py
│ └── templates
└── quicklinks
└── quicklinks.jsonconfiguration: 配置文件目录,此目录下的文件要求为xml格式
metainfo.xml: 服务定义文件,包含了服务名称、服务说明、服务的组件定义、配置文件定义等内容。如此处定义了elasticsearch-server和elasticsearch-client两个组件
package/scripts/: 组件定义脚本,为Python脚本
params.py: 变量定义文件
elasticsearch.py: 通用的服务安装方法、配置文件生成方法
elasticsearch_server.py: elasticsearch-server组件的安装、配置、启动、停止、状态监测方法,可引用elasticsearch.py中定义的通用方法
elasticsearch_client.py: 与elasticsearch_server.py作用相同,区别是client为客户端操作,无状态监测方法
package/templates: 特殊格式的配置文件定义模板,为jinja2格式
quicklinks/quicklinks.json: 快捷链接定义文件,需要在metainfo.xml文件中配置
archive.zip: 自动生成,无需关心
下面是脚本和配置的具体内容:
- configuration/elasticsearch-env.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property require-input="true"> <name>elasticsearch.package.name</name> <value>elasticsearch/elasticsearch-7.16.1-linux-x86_64.tar.gz</value> <description></description> </property> <property require-input="true"> <name>Xms</name> <value>4g</value> <description></description> </property> <property> <name>Xmx</name> <value>4g</value> <description></description> </property> <property> <name>jvm.options</name> <value><![CDATA[################################################################ ## ## JVM configuration ## ################################################################ ## ## WARNING: DO NOT EDIT THIS FILE. If you want to override the ## JVM options in this file, or set any additional options, you ## should create one or more files in the jvm.options.d ## directory containing your adjustments. ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/7.15/jvm-options.html ## for more information. ## ################################################################ ################################################################ ## IMPORTANT: JVM heap size ################################################################ ## ## The heap size is automatically configured by Elasticsearch ## based on the available memory in your system and the roles ## each node is configured to fulfill. If specifying heap is ## required, it should be done through a file in jvm.options.d, ## and the min and max should be set to the same value. For ## example, to set the heap to 4 GB, create a new file in the ## jvm.options.d directory containing these lines: ## ## -Xms4g ## -Xmx4g ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/7.15/heap-size.html ## for more information ## ################################################################ -Xms{{Xms}} -Xmx{{Xmx}} ################################################################ ## Expert settings ################################################################ ## ## All settings below here are considered expert settings. Do ## not adjust them unless you understand what you are doing. Do ## not edit them in this file; instead, create a new file in the ## jvm.options.d directory containing your adjustments. ## ################################################################ ## GC configuration 8-13:-XX:+UseConcMarkSweepGC 8-13:-XX:CMSInitiatingOccupancyFraction=75 8-13:-XX:+UseCMSInitiatingOccupancyOnly ## G1GC Configuration # NOTE: G1 GC is only supported on JDK version 10 or later # to use G1GC, uncomment the next two lines and update the version on the # following three lines to your version of the JDK # 10-13:-XX:-UseConcMarkSweepGC # 10-13:-XX:-UseCMSInitiatingOccupancyOnly 14-:-XX:+UseG1GC ## JVM temporary directory -Djava.io.tmpdir=${ES_TMPDIR} ## heap dumps # generate a heap dump when an allocation from the Java heap fails; heap dumps # are created in the working directory of the JVM unless an alternative path is # specified -XX:+HeapDumpOnOutOfMemoryError # specify an alternative path for heap dumps; ensure the directory exists and # has sufficient space -XX:HeapDumpPath=data # specify an alternative path for JVM fatal error logs -XX:ErrorFile=logs/hs_err_pid%p.log ## JDK 8 GC logging 8:-XX:+PrintGCDetails 8:-XX:+PrintGCDateStamps 8:-XX:+PrintTenuringDistribution 8:-XX:+PrintGCApplicationStoppedTime 8:-Xloggc:logs/gc.log 8:-XX:+UseGCLogFileRotation 8:-XX:NumberOfGCLogFiles=32 8:-XX:GCLogFileSize=64m # JDK 9+ GC logging 9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m]]></value> <description></description> </property> </configuration>
注意:
a. <![CDATA[######]]>是一种标准语法,用于在ambari-web上展示具体的xml详情
b. elasticsearch/elasticsearch-7.16.1-linux-x86_64.tar.gz 默认是在/var/www/html/ambari/3.3.2.0-013/elasticsearch下,有一个http服务,这里需要把安装包放到这个目录下
这里的
2. configuration/elasticsearch.yml.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>cluster.name</name>
<value>digiwin</value>
<description>es集群名称</description>
</property>
<property>
<name>path.data</name>
<value>/data/elasticsearch/data</value>
<description>数据存储目录</description>
</property>
<property>
<name>path.logs</name>
<value>/data/elasticsearch/logs</value>
<description>日志存储目录</description>
</property>
<property>
<name>http.port</name>
<value>9200</value>
<description>http页面访问端口号</description>
</property>
<property>
<name>network.host</name>
<value>0.0.0.0</value>
<description>限制IP访问</description>
</property>
<property>
<name>discovery.zen.fd.ping_interval</name>
<value>1s</value>
<description>集群故障探查间隔时间,每隔多长时间会ping一次node</description>
</property>
<property>
<name>discovery.zen.ping_timeout</name>
<value>3s</value>
<description>自动发现其它节点时ping连接超时时间</description>
</property>
<property>
<name>discovery.zen.fd.ping_retries</name>
<value>3</value>
<description>集群故障探查次数,ping多次都失败时,该node被认为故障,默认是3次</description>
</property>
<property>
<name>discovery.zen.ping.unicast.hosts</name>
<value>{{elasticsearch_addresses}}</value>
<description>集群中master节点的初始列表</description>
</property>
<property>
<name>discovery.zen.join_timeout</name>
<value>5s</value>
<description>加入进的node时发送join request到master node的超时时间</description>
</property>
<property>
<name>discovery.zen.no_master_block</name>
<value>write</value>
<description>master宕机时集群拒绝的操作,write表示宕机可读,all表示宕机拒绝所有操作</description>
</property>
<property>
<name>transport.tcp.port</name>
<value>9300</value>
<description>tcp传输的端口号</description>
</property>
<property>
<name>node.name</name>
<value>{{nodename}}</value>
<description>本机node名称</description>
</property>
<property>
<name>cluster.initial_master_nodes</name>
<value>{{elasticsearch_master_addresses}}</value>
<description>主节点</description>
</property>
</configuration>
- metainfo.xml
<?xml version="1.0"?> <metainfo> <schemaVersion>2.0</schemaVersion> <services> <service> <name>ELASTICSEARCH</name> <displayName>Elasticsearch</displayName> <comment>Elasticsearch是一个实时的分布式搜索分析引擎,被用作全文检索、结构化搜索、分析以及这三个功能的组合.</comment> <version>7.16.1</version> <components> <component> <name>ELASTICSEARCH_SERVER</name> <displayName>Elasticsearch Server</displayName> <category>MASTER</category> <cardinality>1+</cardinality> <versionAdvertised>false</versionAdvertised> <commandScript> <script>scripts/elasticsearch_server.py</script> <scriptType>PYTHON</scriptType> <timeout>1200</timeout> </commandScript> </component> </components> <quickLinksConfigurations> <quickLinksConfiguration> <fileName>quicklinks.json</fileName> <default>true</default> </quickLinksConfiguration> </quickLinksConfigurations> <configuration-dependencies> <config-type>elasticsearch.yml</config-type> <config-type>elasticsearch-env</config-type> </configuration-dependencies> <restartRequiredAfterChange>true</restartRequiredAfterChange> </service> </services> </metainfo> - package/scripts/elasticsearch_client.py
from elasticsearch_server import * class ESClient(Script): def install(self, env): self.install_packages(env) install_elasticsearch() self.configure(env) def configure(self, env): import params env.set_params(params) elasticsearch() def status(self, env): raise ClientComponentHasNoStatus() def upgrade_es(self, env): import params print "Stopping Elasticsearch" Elasticsearch().stop(env) print "upgrading elasticsearch" Execute(format('rm -rf {params.es_home}')) self.install(env) print 'starting elasticsearch' Elasticsearch().start(env) print 'upgrade elasticsearch finished' if __name__ == "__main__": ESClient().execute() - package/scripts/elasticsearch_server.py
import sys, os, time from resource_management import * from elasticsearch import * class Elasticsearch(Script): def install(self, env): self.install_packages(env) install_elasticsearch() self.configure(env) def stop(self, env): import params Execute(format('kill `cat ' + params.pidfile + '`')) time.sleep(5) def start(self, env): import params self.configure(env) Execute(format("{params.es_home}/bin/elasticsearch -d -p " + params.pidfile ), user=params.es_user) time.sleep(5) def status(self, env): import params check_process_status(format(params.pidfile)) def configure(self, env): import params env.set_params(params) elasticsearch() if __name__ == "__main__": Elasticsearch().execute() - package/scripts/elasticsearch.py
import os import resource_management from resource_management import * from ambari_commons.yaml_utils import escape_yaml_property import ambari_simplejson as json def elasticsearch(): import params config = Script.get_config() pid_dir = params.piddir PropertiesFile("elasticsearch.yml", dir=params.es_config_dir, properties=config['configurations']['elasticsearch.yml'], owner=params.es_user, group=params.es_group, key_value_delimiter=": " ) Directory(pid_dir, owner=params.es_user, create_parents=True, group=params.es_group) for dir in params.local_dirs: Directory(dir, owner=params.es_user, create_parents=True, group=params.es_group) # jvm.options jvm_options = "" if (('elasticsearch-env' in config['configurations']) and ('jvm.options' in config['configurations']['elasticsearch-env'])): jvm_options = config['configurations']['elasticsearch-env']['jvm.options'] else: jvm_options = None File(os.path.join(params.es_config_dir, 'jvm.options'), owner=params.es_user, group=params.es_group, content=InlineTemplate(jvm_options)) def install_elasticsearch(): import params os.system('id ' + params.es_user + ";[[ $? -eq 1 ]] && " + 'useradd -m ' + params.es_user) Directory(params.install_dir, owner=params.es_user, create_parents=True, group=params.es_group) fileName = params.dir_name + '.tar.gz' if not os.path.exists(params.es_home): Execute('wget ' + params.download_url + ' -O /tmp/' + fileName, user=params.es_user) Execute('tar -zxf /tmp/' + fileName + ' -C ' + params.install_dir, user=params.es_user) Execute('mv ' + params.install_dir + '/elasticsearch-* ' + params.es_home) Execute(format('chown -R {params.es_user}:{params.es_group} {params.es_home}')) Execute('/bin/rm -f /tmp/' + fileName) - package/scripts/params.py
#!/usr/bin/env python from resource_management import * import ambari_simplejson as json import socket, os # server configurations config = Script.get_config() install_dir = "/opt/apps" dir_name = 'elasticsearch' es_home = install_dir + '/' + dir_name es_config_dir = es_home + "/config" piddir = es_home + "/pid" pidfile = piddir + "/elasticsearch.pid" datadir = default('/configurations/elasticsearch.yml/path.data', "") logdir = config['configurations']['elasticsearch.yml']['path.logs'] hostname = config['agentLevelParams']['hostname'] package_name=default('/configurations/elasticsearch-env/elasticsearch.package.name', "") searchguard_package_name=default('/configurations/elasticsearch-env/searchguard.package.name', "") Xmx=default('/configurations/elasticsearch-env/Xmx', "30g") Xms=default('/configurations/elasticsearch-env/Xms', "30g") baseUrl = '' if 'repositoryFile' in config and 'repositories' in config['repositoryFile']: for repo in config['repositoryFile']['repositories']: if repo['repoName'] == 'HDP': baseUrl = repo['baseUrl'] download_url = baseUrl + '/' + package_name yum_dir = baseUrl.split('/',3)[3] es_user = "elasticsearch" es_group = es_user local_dirs = [config['configurations']['elasticsearch.yml']['path.logs']] dirs=datadir.split(",") for dir in dirs: local_dirs.append(dir) elasticsearch_address="" if "clusterHostInfo" in config: if "elasticsearch_server_hosts" in config['clusterHostInfo']: elasticsearch_server_hosts=config['clusterHostInfo']['elasticsearch_server_hosts'] elasticsearch_httpport=config['configurations']['elasticsearch.yml']['transport.tcp.port'] elasticsearch_server_hosts_len = len(elasticsearch_server_hosts) for i in range(elasticsearch_server_hosts_len): elasticsearch_address += "\"" + (elasticsearch_server_hosts[i] +":"+ bytes(elasticsearch_httpport)) + "\"" if i < elasticsearch_server_hosts_len - 1: elasticsearch_address += "," elasticsearch_master_address="" if "clusterHostInfo" in config: if "elasticsearch_server_hosts" in config['clusterHostInfo']: elasticsearch_master_hosts=config['clusterHostInfo']['elasticsearch_server_hosts'] elasticsearch_master_hosts_len = len(elasticsearch_master_hosts) for i in range(elasticsearch_master_hosts_len): elasticsearch_master_address += "\"" + elasticsearch_master_hosts[i] + "\"" if i < elasticsearch_master_hosts_len - 1: elasticsearch_master_address += "," elasticsearch_addresses="[" + elasticsearch_address + "]" elasticsearch_master_addresses="[" + elasticsearch_master_address + "]" nodename = hostname hostname_ip = socket.gethostbyname(hostname) elasticsearch_hosts = [] if "clusterHostInfo" in config: if "elasticsearch_server_hosts" in config['clusterHostInfo']: elasticsearch_hosts=config['clusterHostInfo']['elasticsearch_server_hosts'] elasticsearch_hosts.sort() - quicklinks/quicklinks.json
以上脚本都没问题后,重启ambari-server服务{ "name": "default", "description": "default quick links configuration", "configuration": { "protocol": { "type":"https", "checks":[ { "property":"dfs.http.policy", "desired":"HTTPS_ONLY", "site":"elasticsearch.yml" } ] }, "links": [ { "name": "elasticseaarch_ui", "label": "ELASTICSEARCH UI", "component_name": "ELASTICSEARCH_SERVER", "url":"%@://%@:%@/_cat/indices?v", "requires_user_name": "false", "port":{ "http_property": "http.port", "http_default_port": "9200", "https_property": "http.port", "https_default_port": "9200", "regex": "\\w*:(\\d+)", "site": "elasticsearch.yml" } } ] } }
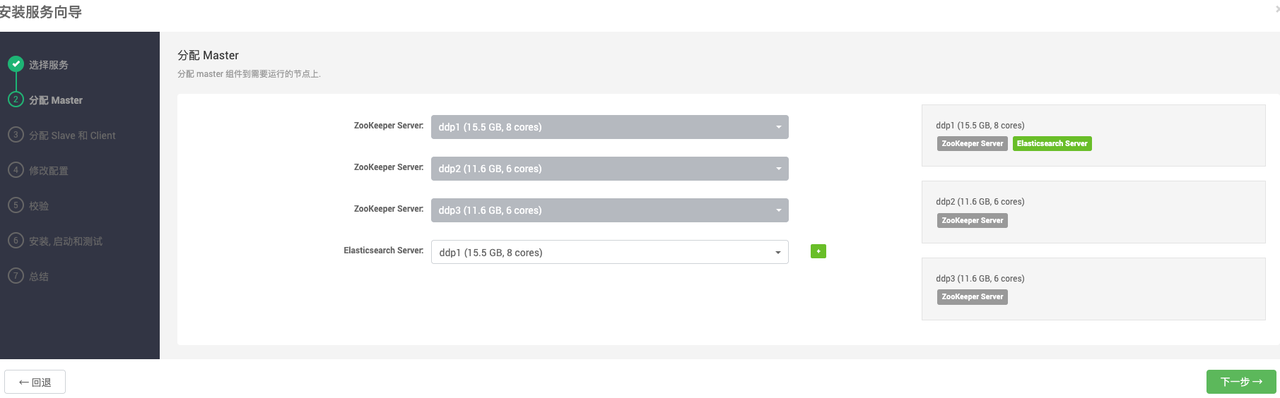
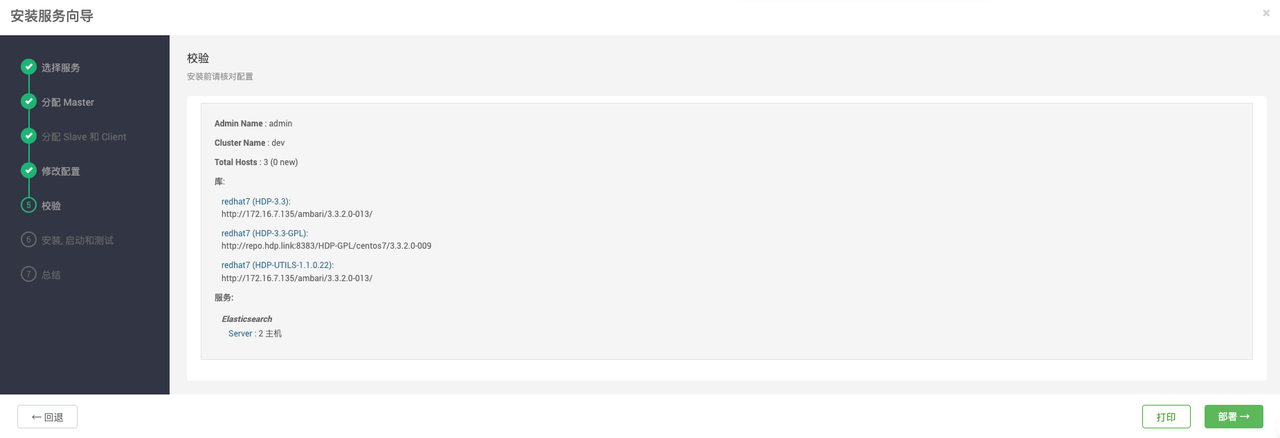
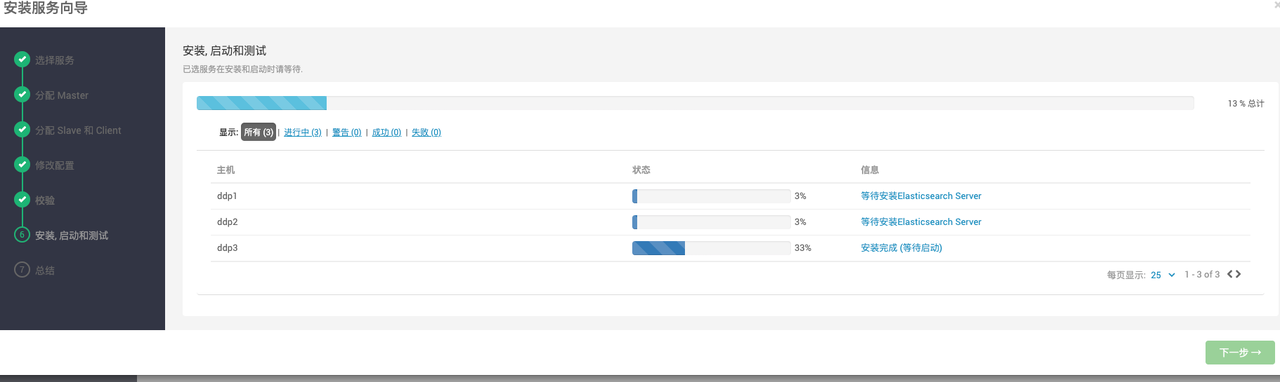
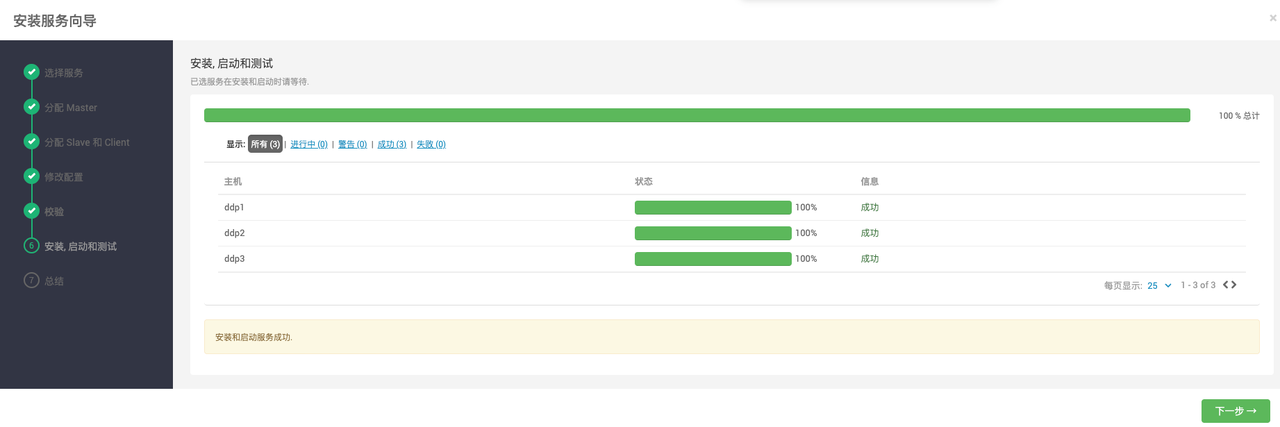
在页面安装ELASTICSEARCH


Ambari 汉化与修改图标
前端页面修改
各模块源码文件及安装后的文件
| 功能模块 | 源码文件 | 安装后目录 |
|---|---|---|
| 仪表盘主 | ambari-web/app/messages.js | /usr/lib/ambari-server/web/javascripts/app.js |
| 界面 | ||
| 管理员界面 | ambari-admin/src/main/resources/ui/admin-web/app/scripts/i18n.config.js/main.js | /var/lib/ambari-server/resources/views/work/ADMIN_VIEW{2.6.1.5}/scripts |
| 主页底部版权信息 | ambari-web/app/assets/index.html | /usr/lib/ambari-server/web/index.html |
| 登录框 | ambari-web/app/templates/login.hbs | /usr/lib/ambari-server/web/javascripts/app.js |
| DashBoard 页头 | /ambari-web/app/templates/application.hbs | /usr/lib/ambari-server/web/javascripts/app.js |
| 仪表盘的关于信息 | ambari-web/app/templates/common/about.hbs | /usr/lib/ambari-server/web/javascripts/app.js |
| 管理页面的关于信息 | /ambari-admin/src/main/resources/ui/admin-web/app/views/modals/AboutModal.html | /var/lib/ambari-server/resources/views/work/ADMIN_VIEW{2.6.1.5}/views/modals/AboutModal.html |
汉化文件:ambari-web/app/messages.js(覆盖原始文件), 安装后目录在/usr/lib/ambari-server/web/javascripts/app.js
修改logo图片:/usr/lib/ambari-server/web/img/ambari-log.png,把这个图片换成公司的图片
修改底部的公司名称: 在/usr/lib/ambari-server/web/index.html里:
<footer>
<div class="container footer-links">
<a data-qa="xxx公司" href="https://xxxx.com" target="_blank" rel="noopener noreferrer">xxx公司</a>.<br>
</div>
</footer>Ambari集成K8S服务
状态检测:
- 当前es的状态检测是通过检测 服务器上的PID文件来获取服务状态 :check_process_status(format(params.pidfile))
- 之后用k8s的状态检测:这个可能之后需要通过API的方式轮询获取每个POD的状态
- K8S之后看看是通过循环检测服务状态,如果服务正常就生成pid文件,还是通过修改check_process_status修改任务状态的获取方式
ambari的服务是和主机强绑定的
k8s的服务和主机天生非强绑定,是可弹性移动的