本文主要包括:
- 使用Scala解析Json
本文主要包括:
本文主要包括:
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
Redis主要有5种数据类型,包括String,List,Set,Zset,Hash,满足大部分的使用要求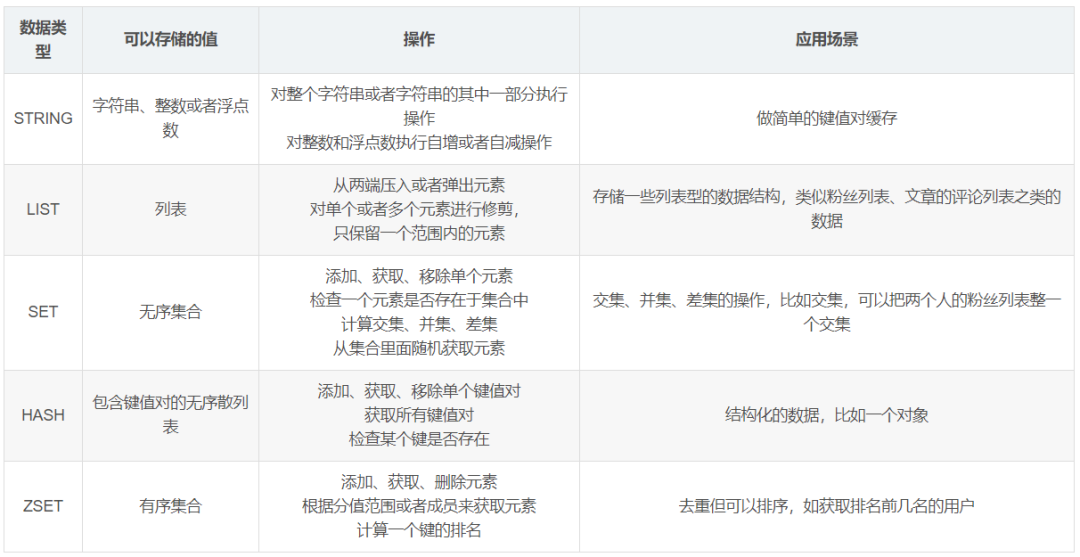
以上可以参考Redis 常见面试题
最近在测试任务的时候,把reids的key和value写反了,导致生产环境的reids凭空多了200多万脏数据,在网上查了一个批量删除的命令,直接在生产环境执行了,导致redis宕机、OOM了
所以,以后再操作生产环境数据库,特别是删除、大规模数据遍历、消耗性能比较大的情况下,在网上查的命令最好还是在测试环境测试一下再用,多么痛的领悟
这里记录一下两个命令:
在数据量较大的情况下,千万别用类似keys *的操作,keys会把reids里所有的key一口气都遍历一遍,消耗性能奇高。。
redis-cli -h ${ip} -p 6379 -n 4 -a '${pws}' keys '0^!*' |xargs redis-cli -h ${ip} -p 6379 -n 4 -a '${psw}' DEL在生产环境下,尽量使用scan
redis-cli -h ${ip} -p 6379 -n 4 -a '${psw}' --scan --pattern "0^!*" | xargs -L 1000 redis-cli -h ${ip} -p 6379 -n 4 -a '${psw}' del具体可以参考:Redis 千万不要乱用KEYS命令,不然会挨打的
本文主要包括:
使用sqoop从mysql导数据到hive,从本地服务器是可以访问mysql的(本地服务器是hadoop集群的一个datanode),但是sqoop导数据的时候依然连接不上mysql
报错如下:
从报错可以看出,是数据库连接失败,很常见的问题,但是从本地是可以直连mysql的。
因为sqoop导数据的时候,默认会启动4个map task,这4个map task会随机启动在不动的datanode上,所以在想,是不是因为其他节点没有权限访问mysql导致。
但是需要先搞清楚,sqoop在抽取数据的时候,是不是会把4个map task随机启动在不动的datanode上
在官网上有如下内容:
虽然讲的不是我们要找到,但是可以判断出,sqoop导数据就是会把maptask随机启动在不通的datanode上。
因此,sqoop在导数据到mysql的时候,要确认,hadoop集群的每个节点都要有mysql的读权限
如果是新添加的电脑,会在首次配置的时候输入验证码,这时候,需要快速在键盘上按下验证码,输入后就可正常连接了
注意,如果失败的次数过多,那么就会提示输入PIN码
如果被绑定的①~④有某个想重新绑定新的电脑,可以按如下步骤:
这里只是为了记录一下,省的下次还要继续查度娘
本文主要包括:
本文主要包括:
本文主要包括: