本文主要包括:
Iceberg简介:
pache Iceberg 是一种用于大型分析数据集的开放表格式。 Iceberg 使用类似于 SQL 表的高性能表格式向包括 Spark、Trino、PrestoDB、Flink 和 Hive 在内的计算引擎添加表。
从这个定义上来看,Iceberg是一个用于海量数据分析场景下的开源的表格式(其实笔者更愿意用Table Format),也就是说Iceberg本质上是一个表格式。
那什么是表格式?表格式和我们熟悉的文件格式(File Format)是一回事吗?
表和表格式是两个概念。表是一个具象的概念,应用层面的概念,我们天天说的表是简单的行和列的组合。而表格式是数据库系统实现层面一个抽象的概念,它定义了一个表中包含哪些字段,表下面文件的组织形式、表索引信息、统计信息以及上层查询引擎读取、写入表中文件的接口
可以参考Apache Iceberg 数据湖从入门到放弃(1) —— 初步入门三部曲
我们可以简单理解为他是基于计算层(flink、spark)和存储层(orc、parqurt)的一个中间层,我们可以把它定义成一种“数据组织格式”,Iceberg将其称之为“表格式”也是表达类似的含义。
他与底层的存储格式(比如ORC、Parquet之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的“表”的语义。
它构建在数据存储格式之上,其底层的数据存储仍然使用Parquet、ORC等进行存储。在hive建立一个iceberg格式的表。用flink或者spark写入iceberg,然后再通过其他方式来读取这个表,
比如spark、flink、presto等。
优势
- 增量读取处理能力:Iceberg支持通过流式方式读取增量数据,支持Structed Streaming以及Flink table Source;
- 支持事务(ACID),上游数据写入即可见,不影响当前数据处理任务,简化ETL;提供upsert和merge into能力,可以极大地缩小数据入库延迟;
- 可扩展的元数据,快照隔离以及对于文件列表的所有修改都是原子操作;
- 同时支持流批处理、支持多种存储格式和灵活的文件组织:提供了基于流式的增量计算模型和基于批处理的全量表计算模型。批处理和流任务可以使用相同的存储模型,数据不再孤立;Iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新。支持Parquet、Avro以及ORC等存储格式。
- 支持多种计算引擎,优秀的内核抽象使之不绑定特定的计算引擎,目前Iceberg支持的计算引擎有Spark、Flink、Presto以及Hive。
与其他数据湖产品对比: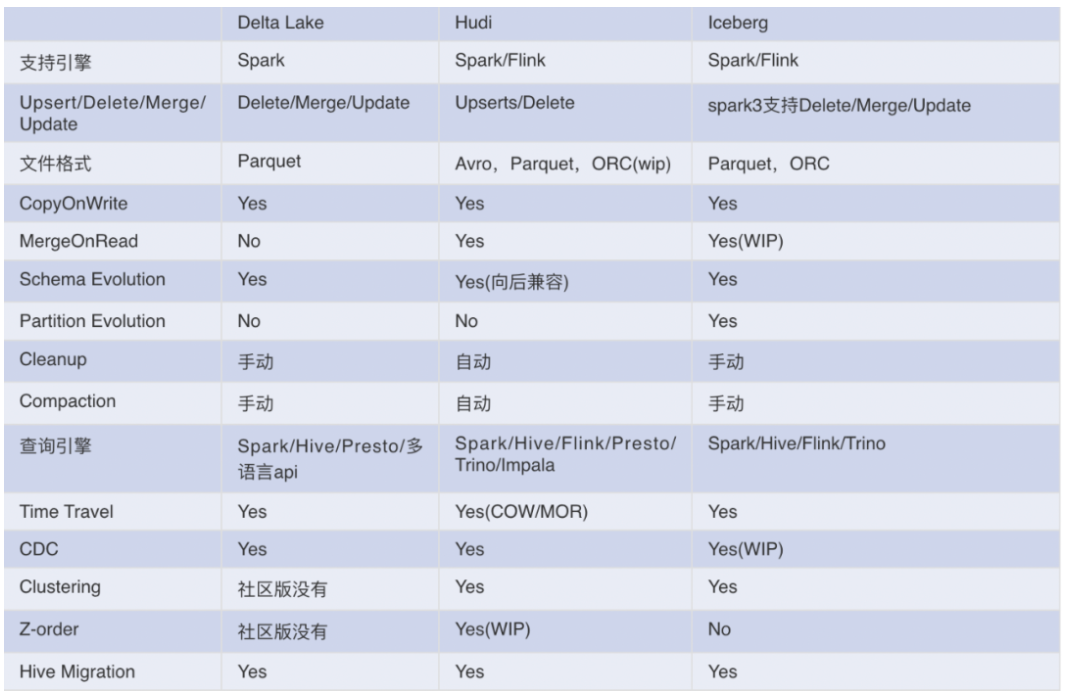
Iceberg架构
Iceberg只是一个table format,不存在架构方面
Iceberg写数据流程
Iceberg写入流程及文件结构:Iceberg在数据写入的时候,
① 先把数据写入到data file文件中;
② 当一组data file文件写完之后,会根据这个data file文件中column的一些统计信息(如:每个column的min/max值),生成一个对应的manifest文件;
③ 然后Iceberg把一次写入后涉及到的manifest文件组成一个 manifest list, manifest list文件中也会存入一些相关manifest的统计信息(如:分区信息,manifest有效性)等;
④ 然后按照整个manifest list 生成一个对应的snapshot文件;
⑤ 生成完snapshot文件之后,Iceberg会把当前snapshot的ID及存储路径等信息写入到metadata文件中;
⑥ 当一切准备完毕之后,会以原子操作的方式commit这个metadata文件,这样一次iceberg的数据写入就完成了。随着每次的写入iceberg就生成了如下图这样的一个文件组织模式。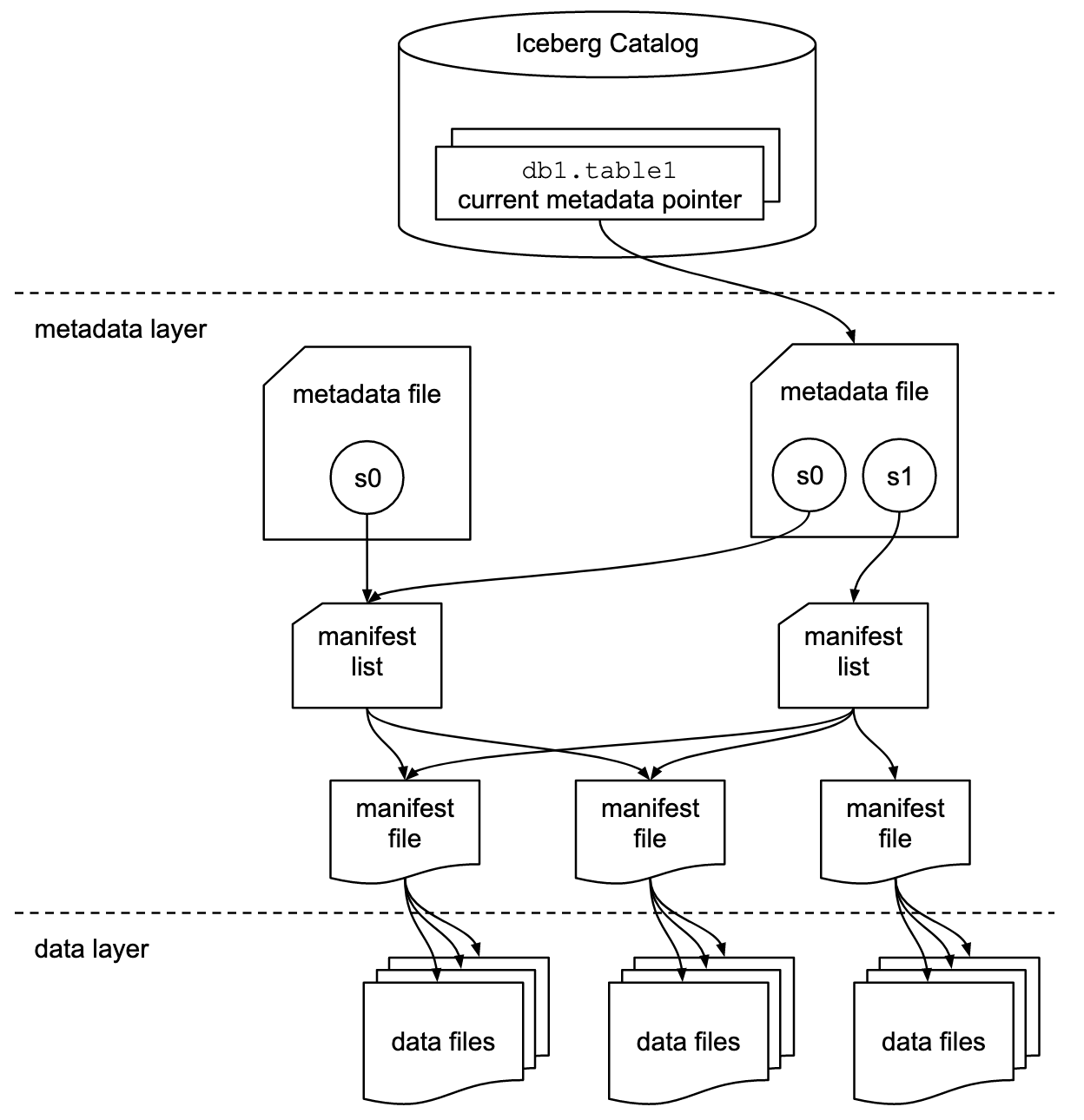
Iceberg读数据流程
Iceberg的分区查找优化:
Iceberg数据表每一次的修改后的状态都会生成一个snapshot(s0,s1)文件,snapshot文件中包含了一个manifest文件的list,
list中存储了当前的snapshot状态是由哪些manifest文件组成的。每一个manifest的文件中会指向到真实数据的存储文件 data file(一般是parquet格式)。
在这种结构中,每一个快照读取所需要的数据文件都已经清晰的定义在了manifest list 和 manifest的文件中,
并且manifest文件中还存储了相关的partition信息,那么在读取数据的时候如果需要删选partition,
通过manifest的中存储的信息以K&V映射方式在O(1)复杂度的计算中就能定位到需要读取的partition目录。
当前常用的数据读取引擎,例如hive需要遍历整个数据目录下的文件索引来寻找必要的partition,是一个O(n)的复杂度查找过程。
在大数据常见的海量分区下,采用partition映射的模式来选取目录的优化效果是非常明显的,
可以在Ryan Blue的讲座中看到在NetFlix的应用场景中2600个分区只需要10S就列出了,
而使用hive大概10分钟还没有完成 。
Iceberg谓词下推的三层过滤:
① 分区过滤:Iceberg支持查询中的谓词下推,前面已经说了Iceberg是支持隐式分区的,就是说在读取数据的时候不需要在SQL中指定分区。
Iceberg会接收上层计算引擎下推过来的谓词表达式,根据谓词表达式中column分区列的信息进行分区转换的计算。
例如 一个Iceberg表有一列 time ,用户设定了在 time 列上按照小时分区,当查询条件为 time >= 2020-01-01 10:00 AND < 2020-01-01 13:00 的时候Iceberg会根据下推过来的谓词表达式和Schema中定义的分区转换表达式进行计算。
直接算出数据分区是在 10点11点12点三个分区中,然后依据manifest中的分区字段直接定位到分区目录。
② 文件过滤:Iceberg会把谓词继续下推到更细的筛选粒度,根据谓词的表达式和manifest中column的min/max值Iceberg可以有效的过滤查询数据所覆盖的具体data file,
对扫描集做进一步的筛选,如果筛选column是有序的那么下推效果将更加明显。
③ RowGroup过滤:经过分区过滤和文件过滤之后Iceberg还会继续把谓词表达式下推到data file文件内部的RowGroup级别,
根据parquet文件的metadata信息对RowGroup做进一步的筛选。经过以上三层的筛选,Iceberg最终把数据的扫描集缩小到必须读取的RowGroup级别,
然后把需要读取的RowGroup数据读入到内存之中。
(同样在Ryan Blue的讲座中我们可以看到,通过层层筛选(命中 min/max)之后,iceberg使得数据计算任务从61小时降低到了22分钟)。
Iceberg的向量化读取和数据的zero copy:在低版本的spark中,由于spark DataSourceV2的API不支持批量读取,
因此Iceberg通过for循环把筛选后的数据一行一行的返回给spark去处理这个过程中既需要数据不断的在内存中互相拷贝,
也无法发挥列式数据在现代CPU架构中的向量化处理能力。为了进一步提升读取速度,Iceberg在spark2.4.4版本之后,
利用spark BatchColumn的读取特性引入了向量化读取的能力。
① 经过谓词下推后,Iceberg把需要的RowGroup数据读入到了内存中。RowGroup是列式组织的,具有可向量化处理的优势;
② Iceberg会根据SQL语句的project来删减需要读取的 column trunk;
③ 然后Iceberg借助Arrow插件作为共享内存,以page + Batch size 为单位一次性的把一个批次大小的数据存入到共享内存中;
④ 当数据存储完之后把共享内存地址返回给spark,spark拿到共享内存地址之后,可以不再进行数据拷贝直接通过偏移量来访问Arrow获取数据。
可以参考Apache Iceberg 对推荐应用架构的优化及读写流程解析
思考
- Iceberg数据更新的时候貌似不是实时更新的,而是准实时更新的,而且,每次更新,都会生成文件,这就导致,如果频繁更新,那么HDFS上的小文件可能会比较多,这里可以测试一下
Iceberg简单使用案例
flinkcdc 读取mysql并写入Iceberg
需要注意的是,flink实时写Iceberg必须要开启checkpointset execution.checkpointing.interval=3sec; CREATE TABLE users_source_mysql ( uuid string , name STRING, age int, ts timestamp(3), part string ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '150.158.190.192', 'port' = '3306', 'username' = 'root', 'password' = 'Gjc123!@#', 'server-time-zone' = 'Asia/Shanghai', 'debezium.snapshot.mode' = 'initial', 'database-name' = 'test', 'table-name' = 'users_source_mysql' ); CREATE TABLE iceberg_users_source_mysql ( uuid INT PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts timestamp(3), part VARCHAR(20) ) WITH ( 'connector'='iceberg' -- 主键和分区均可多个,分割 , 'format-version' = '2' -- iceberg表版本,可选1,2 , 'write.upsert.enabled' = 'true' -- 开启upsert , 'engine.hive.enabled' = 'true' -- 启用hive同步 , 'catalog-name'='hive_catalog' -- 指定catalog , 'catalog-database'='iceberg' -- 指定hive database , 'uri'='thrift://xxxx:9083' -- hive hms地址,分割 , 'warehouse'='hdfs:///user/hive/warehouse/iceberg.db/iceberg_users_source_mysql' -- 仓库地址 ); insert into iceberg_users_source_mysql select uuid,name,age,ts,part from users_source_mysql;